Tricky$^2$: 人間とLLMの誤りの相互作用を評価するためのベンチマークに向けて
ソフトウェア開発において大規模言語モデル(LLM)の活用が急速に広がる中で、人間が書いたコードとAIが生成したコードが混在する環境での信頼性確保が重要な課題となっています。本研究では、人間由来のバグとLLMが生成したバグが同一プログラム内で共存する「混合起源エラー」を評価するための新しいベンチマーク「Tricky$^2$」を提案し、その複雑性を体系的にモデル化しました。検証の結果、人間とAIのバグが組み合わさることでエラー同士が互いを隠蔽または悪化させる相互作用が発生し、単一のバグ修正よりも難易度が劇的に上昇することが実証されました。
TL;DR(結論)
ソフトウェア開発において大規模言語モデル(LLM)の活用が急速に広がる中で、人間が書いたコードとAIが生成したコードが混在する環境での信頼性確保が重要な課題となっています。本研究では、人間由来のバグとLLMが生成したバグが同一プログラム内で共存する「混合起源エラー」を評価するための新しいベンチマーク「Tricky$^2$」を提案し、その複雑性を体系的にモデル化しました。検証の結果、人間とAIのバグが組み合わさることでエラー同士が互いを隠蔽または悪化させる相互作用が発生し、単一のバグ修正よりも難易度が劇的に上昇することが実証されました。
なぜこの問題か
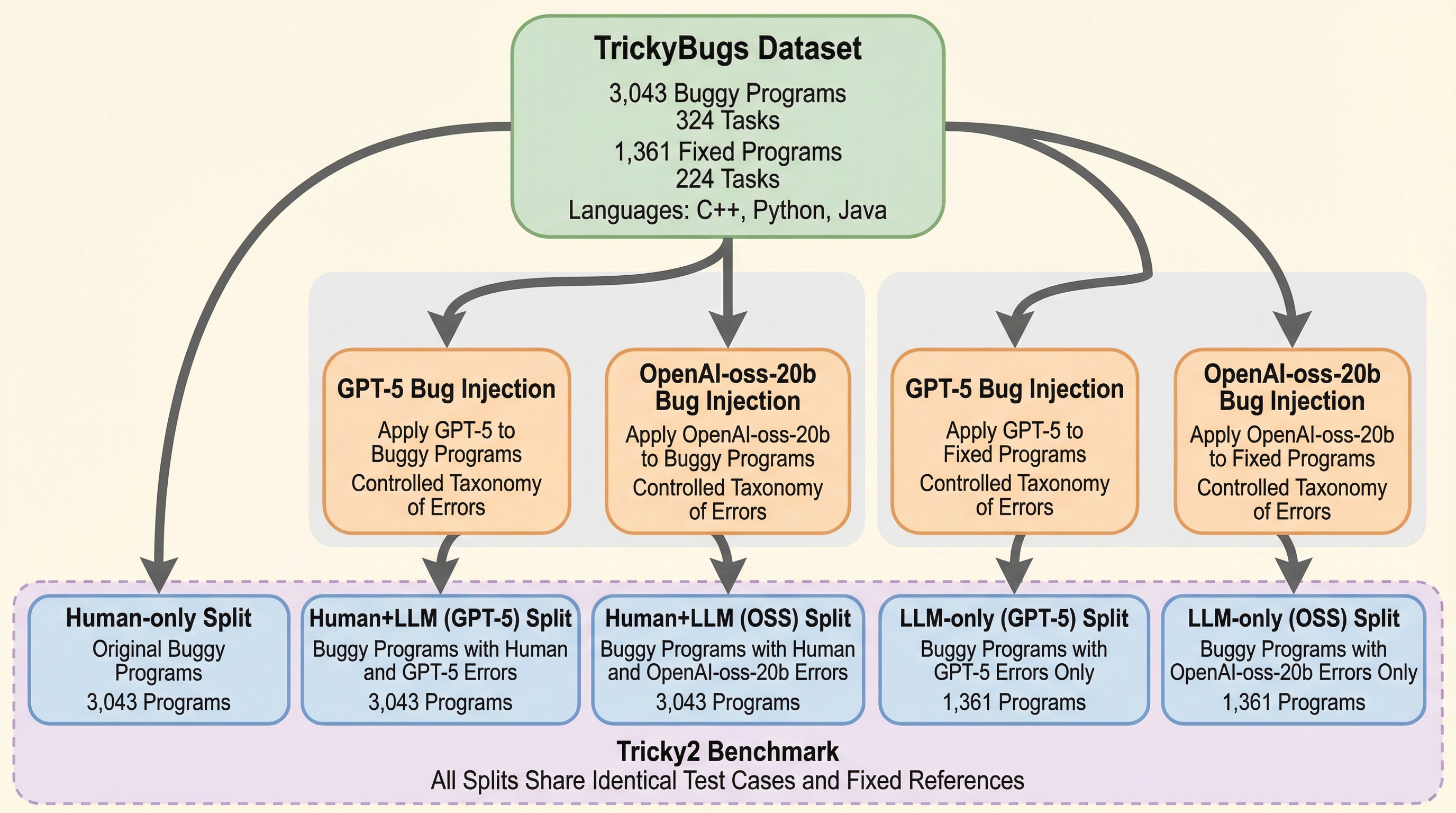
現在、ソフトウェアエンジニアリングの現場では、GitHub Copilotに代表される大規模言語モデル(LLM)の統合が劇的な速度で進んでいます。数百万人の開発者がこれらのツールを利用して、コードの自動補完やドキュメント作成、エラー修正を行っていますが、この人間とAIの共同作業はソフトウェアの信頼性に新たな懸念をもたらしています。先行研究によれば、LLMが生成するコードには、人間が書くコードとは質的に異なる種類のエラーが含まれる傾向があります。例えば、AI由来のコードは構造的には単純であっても、ハルシネーション(幻覚)や未使用の構造、高リスクなセキュリティ脆弱性が含まれやすいという特徴があります。対照的に、人間が書くコードは構造的な複雑さが大きく、保守性の面で困難が生じやすいという違いがあります。 しかし、これまでのバグ評価用ベンチマークの多くは、人間による欠陥(TrickyBugsやBugsInPy、Defects4Jなど)か、あるいはLLMによる合成エラー(buggy-HumanEvalやCriticGPTなど)のどちらか一方のみを対象としており、両者が混在する状況を想定していませんでした。…
核心:何を提案したのか
本研究では、人間とLLMのバグが共有されたプログラム文脈の中でどのように共存し、相互に影響を及ぼすかを評価するための新しいベンチマーク「Tricky$^2$」を提案しました。これは、競技プログラミングの提出物から収集された既存の人間によるバグデータセット「TrickyBugs」を基盤として拡張したものです。Tricky$^2$の最大の特徴は、エラーの発生源を「人間のみ(Human-only)」、「LLMのみ(LLM-only)」、そして「人間とLLMの混合(Human+LLM)」の3つのスプリットに分類し、それらを同一のプログラム構造内で明示的にモデル化している点にあります。これにより、単一のバグ修正能力だけでなく、複数の起源を持つエラーが絡み合った複雑なシナリオにおけるAIモデルの性能を多角的に測定することが可能になりました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related