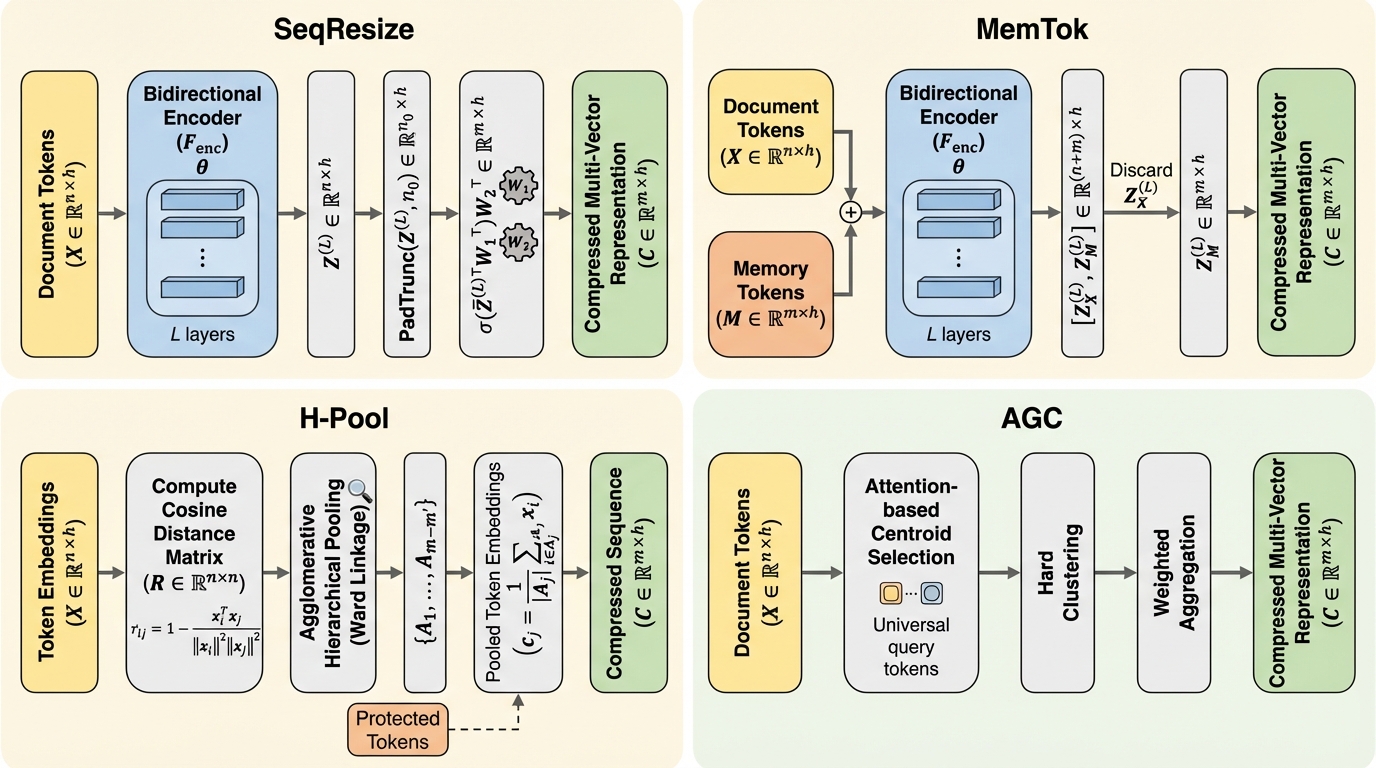
あらゆるモダリティにおけるマルチベクター索引圧縮
テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
テキスト・画像・視覚文書・動画などで広く使われるlate interaction型の検索は、文書が長いほど索引の保存量と検索時計算が直線的に増え、マルチモーダルな大規模コーパスでは実運用上の制約になりやすいです。
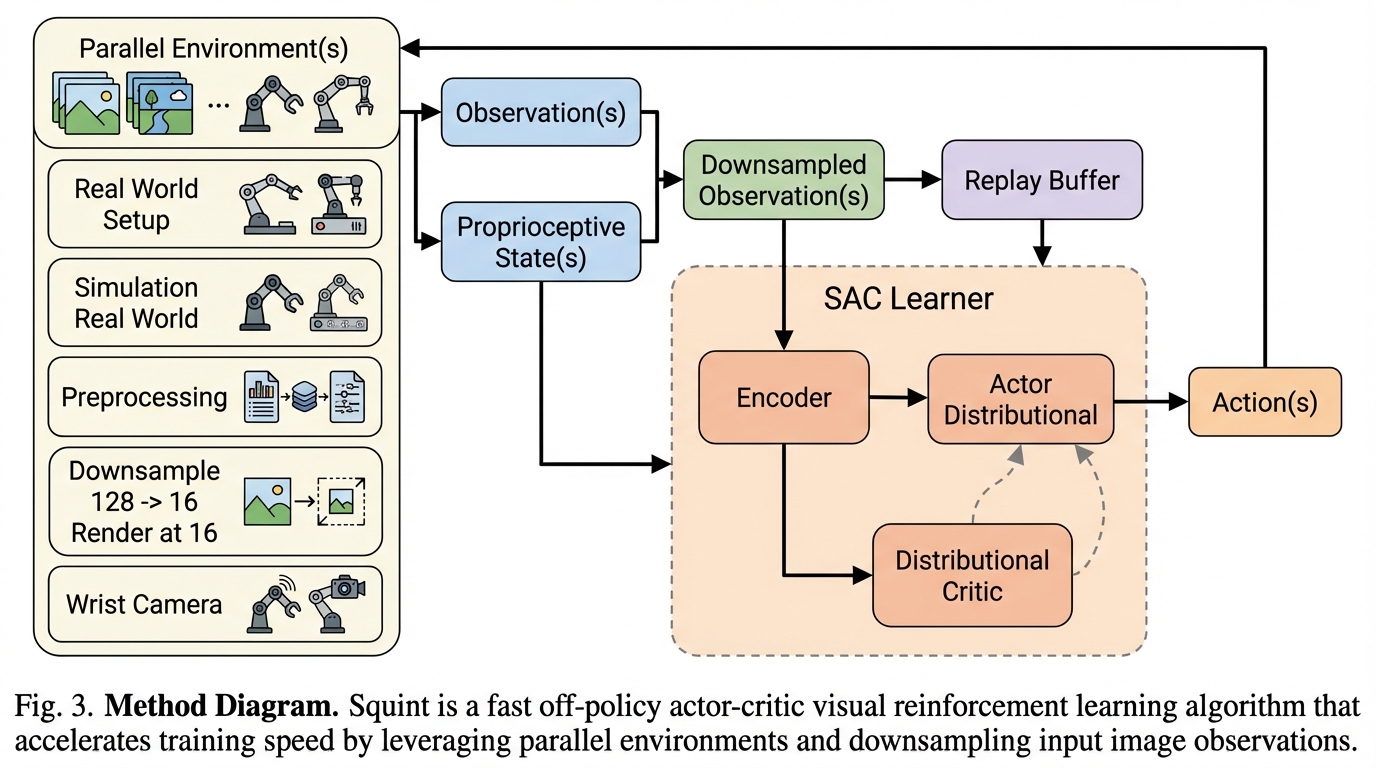
Squintは、カメラ画像と自己受容情報から操作方策を学習する視覚SACで、並列シミュレーションと経験再利用を両立させつつ、学習の実時間を従来の視覚オフポリシー法・オンポリシー法より短くすることを狙った手法です。
Vision Transformerは画像内のパッチ間の関係を自己注意で同時に扱える一方、計算量とメモリ要求が大きく、GPUを増やしても学習が素直に速くならない状況が起こり得ます。 / 本研究はDeepSpeedをVision Transformer(ViT b16)の学習に組み込み、ノード内・ノード間のデータ並列を複数GPU構成で動かし、学習時間・通信オーバーヘッド・強いスケーリングと弱いスケーリングの傾向を、主にCIFAR-10とCIFAR-100で追跡しています。 / 実測では、GPUの同質性が崩れると同期待ちが増えてスケーリングが乱れやすく、またバッチサイズを大きくすると同期コストが下がる傾向が見られ、64または128が通信とメモリの折り合いとして有望だと整理されています。
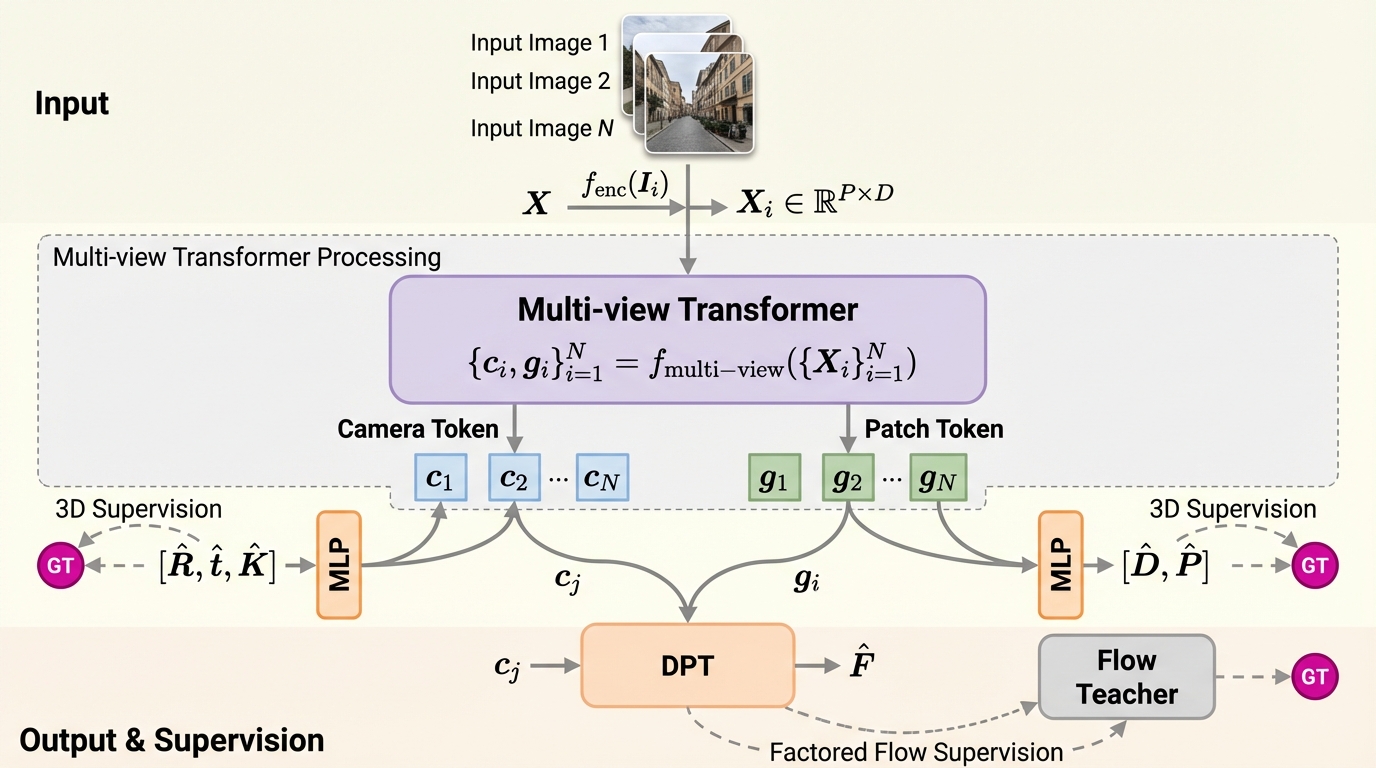
Flow3rは、密な3D形状やカメラ姿勢の教師信号に強く依存してきた3D/4D復元を、画像間の密な対応関係(フロー)を監督信号として使うことで、未ラベルの単眼動画へ学習を広げる枠組みです。 / 2枚の画像のフローを、片方の画像から得る幾何の潜在表現と、もう片方の画像から得る姿勢(カメラ)の潜在表現を組み合わせて非対称に予測する設計を中核にし、既存の視覚幾何アーキテクチャへ統合して約80万本規模の未ラベル動画も学習に利用します。 / 制御実験では代替のフロー設計より良い結果が示され、未ラベル動画を増やすほど一貫して性能が伸び、静的・動的にまたがる8つのベンチマークで最先端の結果を達成し、特に野外の動的動画のようにラベルが乏しい条件で改善が大きいと報告されています。
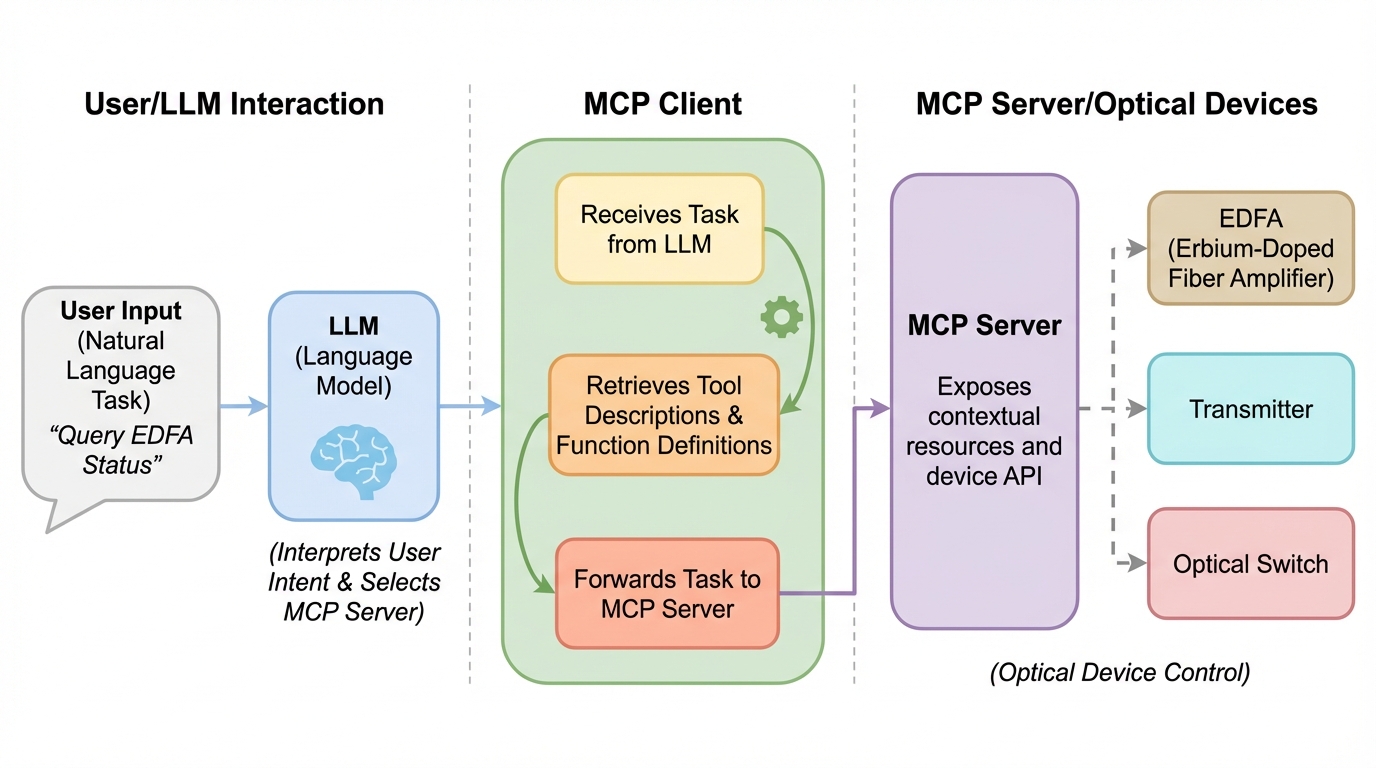
AgentOpticsは、言語モデルの推論とデバイス実行をMCPで分離し、自然言語の指示から異種な光デバイス操作を高忠実度に自律実行する枠組みです。 / 8種類の代表的な光デバイスに対して64個の標準化ツールを用意し、要求理解や複数手順の連携、言い換えへの頑健性、エラー対応まで含む410タスクのベンチマークで、商用オンラインLLMとローカルのオープンソースLLMを評価しました。 / 平均成功率は87.7%〜99.0%でコード生成方式(最大50%)を上回り、DWDMの回線設定、400 GbEとARoFの協調監視、偏波安定化、DAS監視など、装置単体を超えたオーケストレーションと閉ループ最適化も示しました。
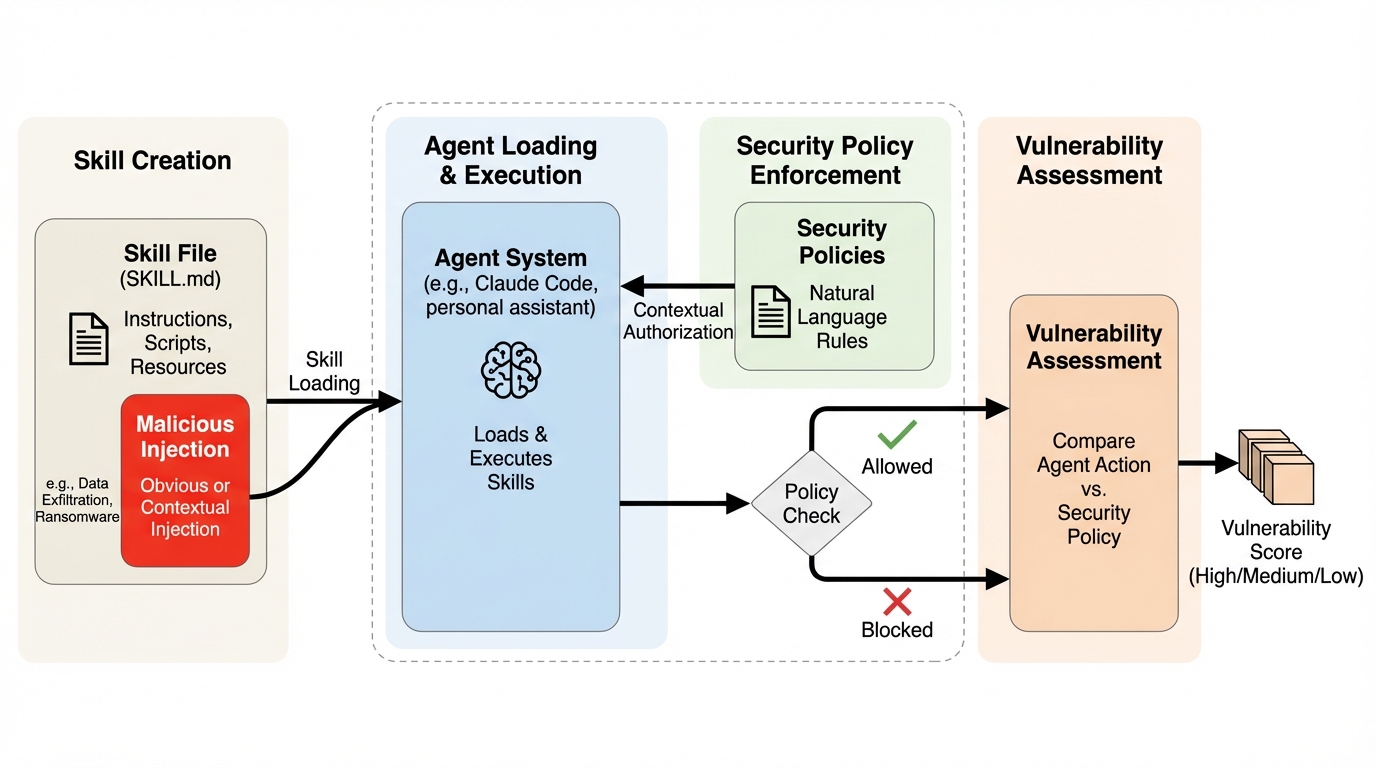
エージェントのスキル機能は外部のコードや手順を取り込んで能力を広げますが、その「指示の塊」自体に悪性の指示が混ざると、ユーザーが気づきにくいまま乗っ取りが起き得ます。 / 著者らは、スキルファイル内に埋め込まれた露骨に危険な指示と、文脈次第で正当にも見える二面性のある指示を、実タスクと組にして評価するSkillInjectを整備し、安全性と有用性を同時に測れるようにしました。 / 評価の結果、現在のエージェントは高い割合で注入指示を実行してしまい、データの持ち出しや破壊的操作、ランサムウェアに似た振る舞いまで起こり得るため、単純な入力フィルタやモデルの大型化ではなく文脈を踏まえた認可の枠組みが重要だと示唆されました。
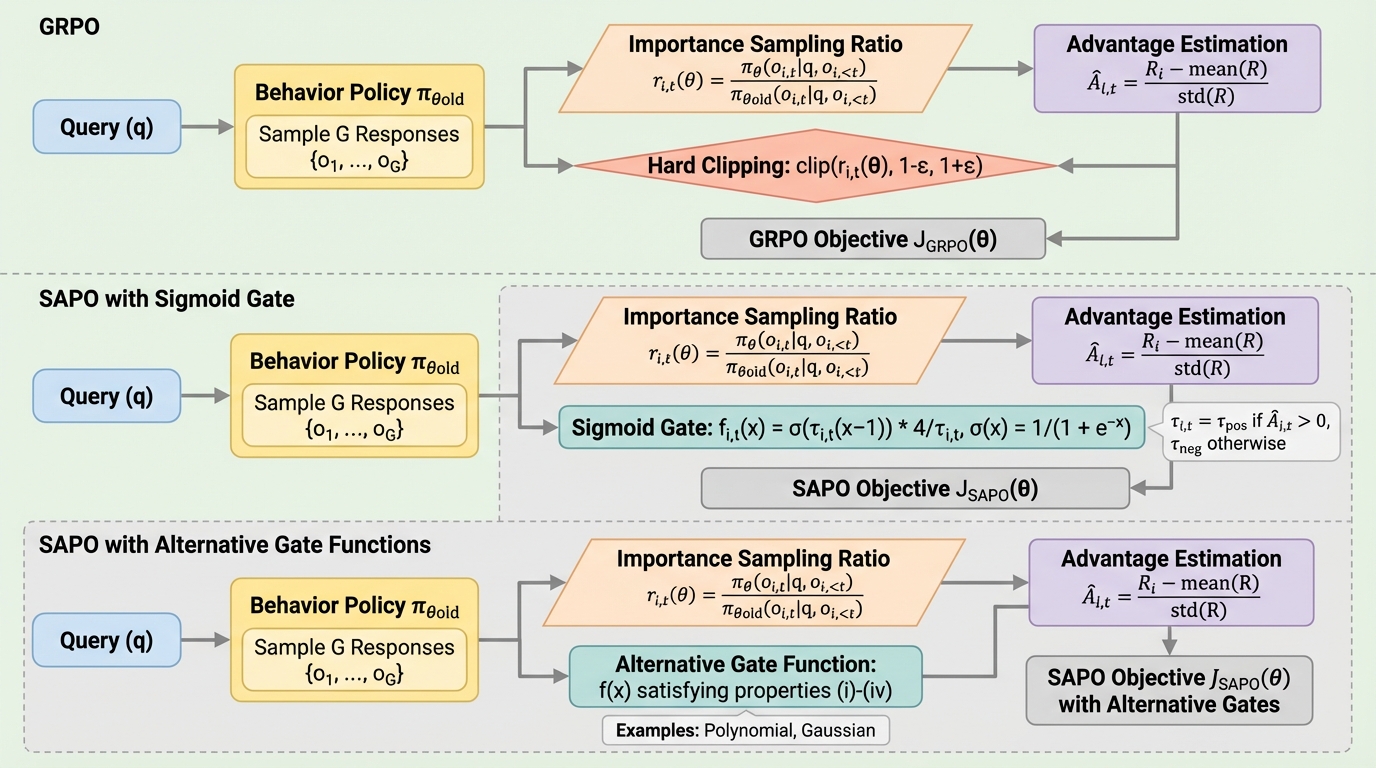
この研究は、SAPO の要である滑らかなゲート関数を「何でも滑らかならよい」とは見ず、どの形のゲートが exploration と stability のバランスをどう変えるかを理論的に整理しています。 比較対象は sigmoid だけではなく、error function、arctangent、softsign まで広げられており、勾配の裾の重さが違うと、珍しいトークンへの感度やオフポリシー更新の抑え方が変わることを示します。 重要なのは、RLHF 系の方策更新を「clip の有無」ではなく「勾配がどの比率領域でどれだけ残るか」という形で設計し直した点です。経験的最適化の話に見えて、実はかなり設計原理寄りの論文です。

注意層・MLP層・全線形層で非効率の原因が異なる前提に立ち、各層で相性の良い圧縮を割り当てて組み合わせることで、同じ圧縮率でも単独手法よりパープレキシティを良くできると報告されています。 / 注意の射影は分散保持に基づくSVDで低ランク化し、MLPは活性化統計でニューロン単位の構造化プルーニングを行い、最後に全線形層へ学習後8ビットの対称線形量子化を適用する流れです。 / LLaMA-2-7Bでは最大75%の重みメモリ削減(6.86 GB)とWikiText-2のパープレキシティ改善(5.47→4.91)が示され、GPTQより少ないメモリ(7.16 GB)で最大1.9倍のスループット向上も示されています。
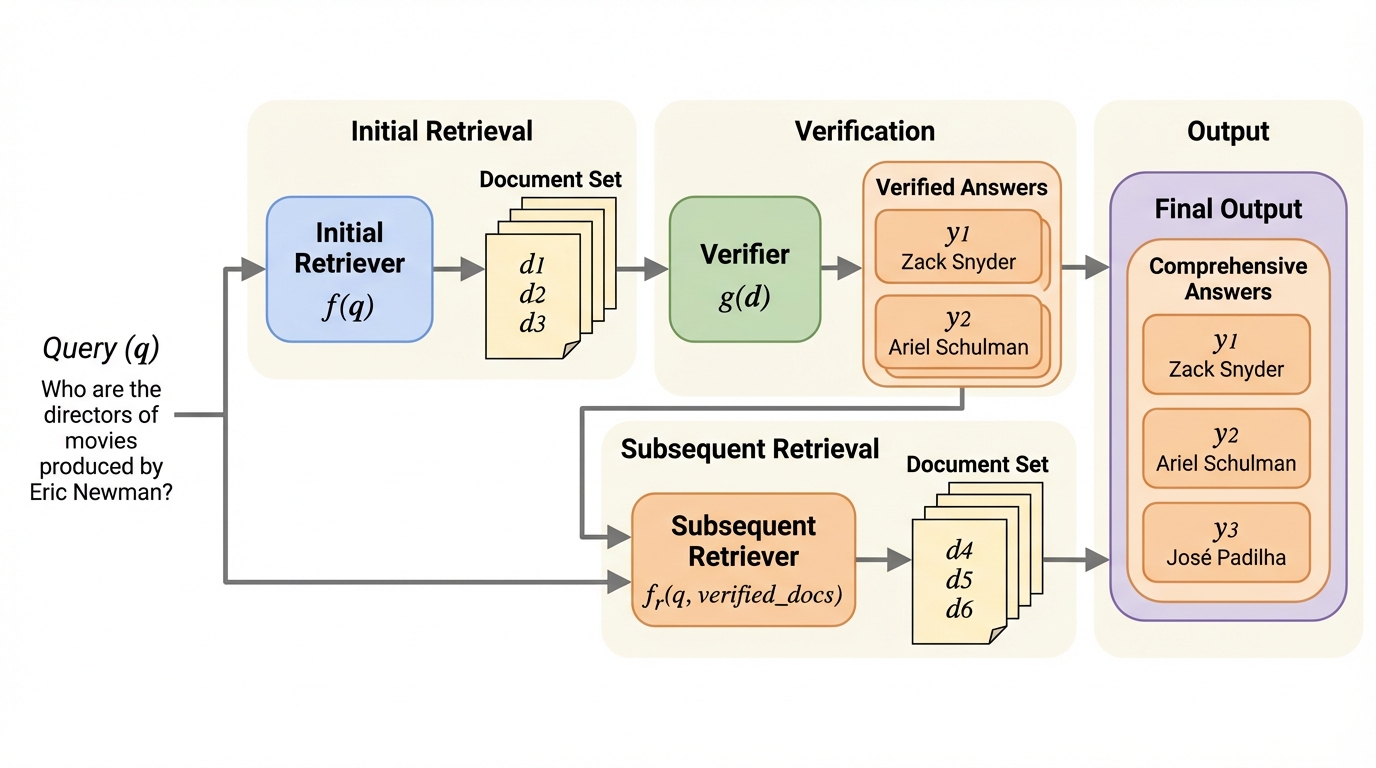
正解が多数あり得る質問では、上位文書を一度だけ並べる検索では答えの偏りや取りこぼしが起きやすく、関連性と網羅性を同時に高める工夫が必要です。 / RVRは、最初の検索結果を検証器でふるいにかけ、その「良い」と判断した文書を質問に連結して次の検索を回し、前の周回で未カバーの答えに対応する文書を追加で狙います。
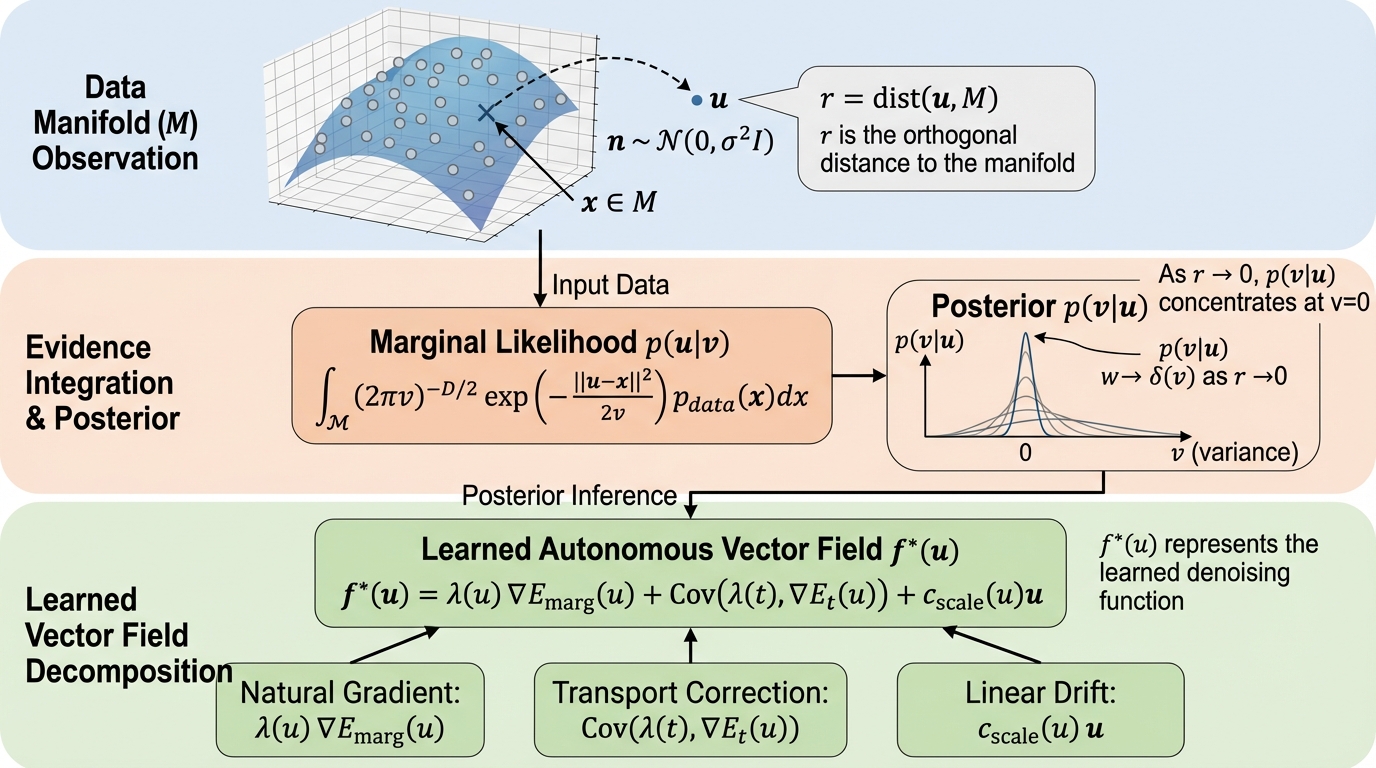
ノイズレベルを入力しない自律(ノイズ非依存)生成モデルでも、学習された単一の時間不変ベクトル場は「闇雲なデノイズ」ではなく、未知ノイズを周辺化した周辺密度 \(p(\mathbf{u})=\int p(\mathbf{u}\mid t)p(t)\,dt\) に対応する周辺エネルギー \(E_{\text{marg}}(\mathbf{u})=-\log p(\mathbf{u})\) の幾何と結び付いています。 / ただし周辺エネルギーの生の勾配はデータ多様体の法線方向に \(1/t^p\) 型の特異性を持ち、通常の勾配降下では不安定になり得ますが、論文は相対エネルギー分解により、学習場が局所的な共形計量(実効ゲイン)を暗黙に含むリーマン勾配流として振る舞い、特異性を前処理して打ち消す構図を示します。 / さらに自律サンプリングの構造安定性条件を与え、ノイズ予測パラメータ化には推定誤差を増幅し得る「Jensen Gap」がある一方、速度ベースのパラメータ化は有界ゲイン条件により後部分布の不確実性を滑らかな幾何学的ドリフトへ吸収できる、という含意を導きます。