Flow3r:因子分解したフロー予測で、拡張可能な視覚幾何学学習
Flow3rは、密な3D形状やカメラ姿勢の教師信号に強く依存してきた3D/4D復元を、画像間の密な対応関係(フロー)を監督信号として使うことで、未ラベルの単眼動画へ学習を広げる枠組みです。 / 2枚の画像のフローを、片方の画像から得る幾何の潜在表現と、もう片方の画像から得る姿勢(カメラ)の潜在表現を組み合わせて非対称に予測する設計を中核にし、既存の視覚幾何アーキテクチャへ統合して約80万本規模の未ラベル動画も学習に利用します。 / 制御実験では代替のフロー設計より良い結果が示され、未ラベル動画を増やすほど一貫して性能が伸び、静的・動的にまたがる8つのベンチマークで最先端の結果を達成し、特に野外の動的動画のようにラベルが乏しい条件で改善が大きいと報告されています。
TL;DR(結論)
- Flow3rは、密な3D形状やカメラ姿勢の教師信号に強く依存してきた3D/4D復元を、画像間の密な対応関係(フロー)を監督信号として使うことで、未ラベルの単眼動画へ学習を広げる枠組みです。
- 2枚の画像のフローを、片方の画像から得る幾何の潜在表現と、もう片方の画像から得る姿勢(カメラ)の潜在表現を組み合わせて非対称に予測する設計を中核にし、既存の視覚幾何アーキテクチャへ統合して約80万本規模の未ラベル動画も学習に利用します。
- 制御実験では代替のフロー設計より良い結果が示され、未ラベル動画を増やすほど一貫して性能が伸び、静的・動的にまたがる8つのベンチマークで最先端の結果を達成し、特に野外の動的動画のようにラベルが乏しい条件で改善が大きいと報告されています。
なぜこの問題か
近年の視覚幾何推論は、複数視点画像から静的または動的シーンの3D構造を推定する際に、最適化ベースの手法から、入力画像に対して幾何と姿勢を直接出力するフィードフォワード型の予測器へと重点が移っています。ところが本文抜粋が示す通り、これらのシステムの成功は、学習時に「密な幾何」と「カメラ姿勢」という教師信号を広い範囲で用意できることに強く依存していました。こうした教師は多視点復元パイプライン(例としてStructure-from-Motionが挙げられています)から得られることが多い一方で、スケールさせて収集するのは高コストで、現実世界の動的シーンや野外の動的動画、エゴセントリック動画などでは特に不足しやすいと説明されています。 この依存関係は、別分野で自己教師の目的関数が大規模化を支えた流れと対比され、視覚幾何学習だけが大規模・多様なデータへ広げにくい要因として位置づけられています。一方で、画像間の密な対応関係は古典的な多視点推定の中核であり、近年は汎用的な画像ペアや動画に対して密対応を推定するモデルが進展しています。…
核心:何を提案したのか
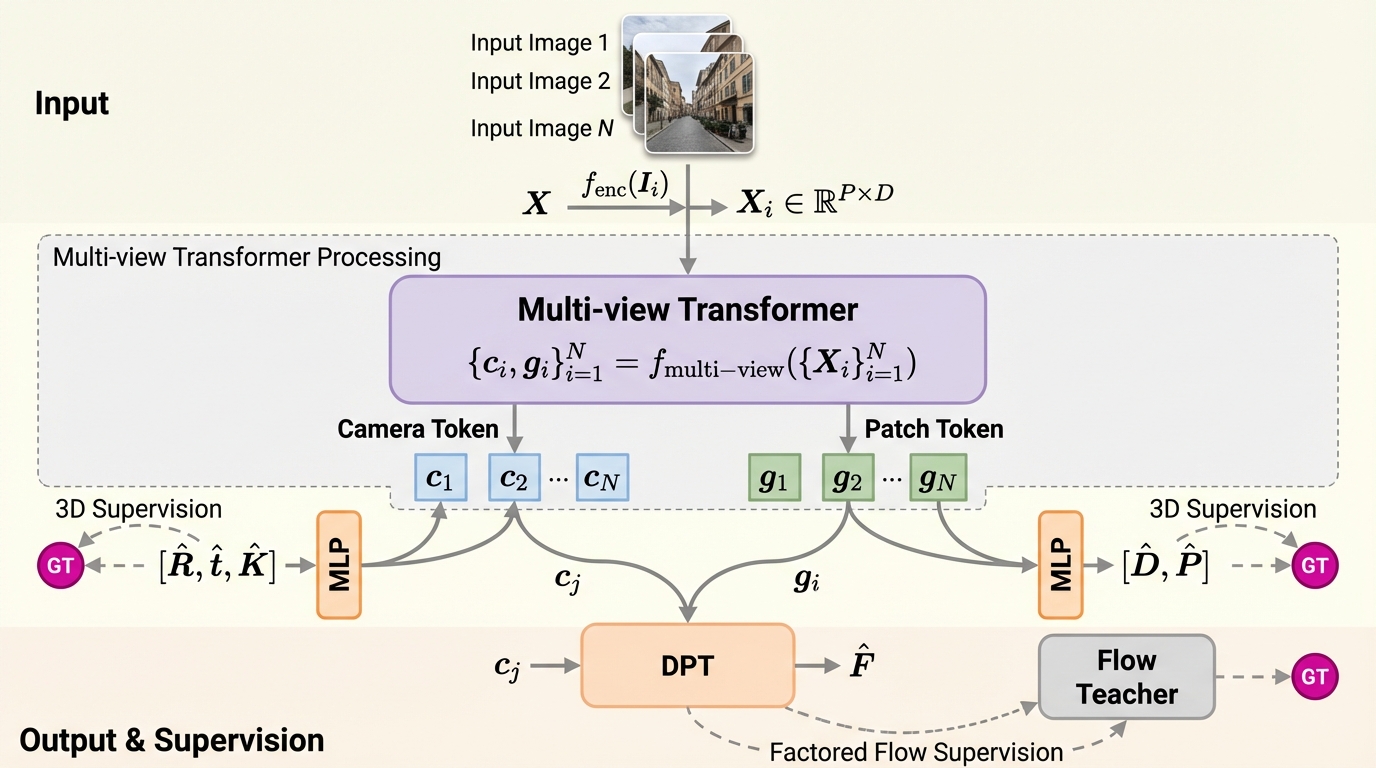
Flow3rが提案する中心は、視覚幾何モデルの学習を「フローの予測」で強く導くために、フロー予測モジュールを因子分解し、非対称な情報の組み合わせとして定義する点です。具体的には、2枚の画像の間のフローを推定するとき、片方の画像から得た幾何に対応する潜在表現を「ソース側」として使い、もう片方の画像から得たカメラ姿勢に対応する潜在表現を「ターゲット側」として使います。これにより、フローという2Dの教師信号が、シーン幾何とカメラ運動の両方に同時に働くように設計されています。 この着想は、本文抜粋で説明されている射影幾何の見方とも整合します。静的シーンであれば、ソース画像で推定した点群表現(点マップ)とターゲット画像のカメラパラメータを用いて、投影によって対応点(すなわちフロー)を計算できるため、フローは「ソースの幾何」と「ターゲットの姿勢」によって誘導されると捉えられます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related