エージェント型ビジネスプロセス管理システム
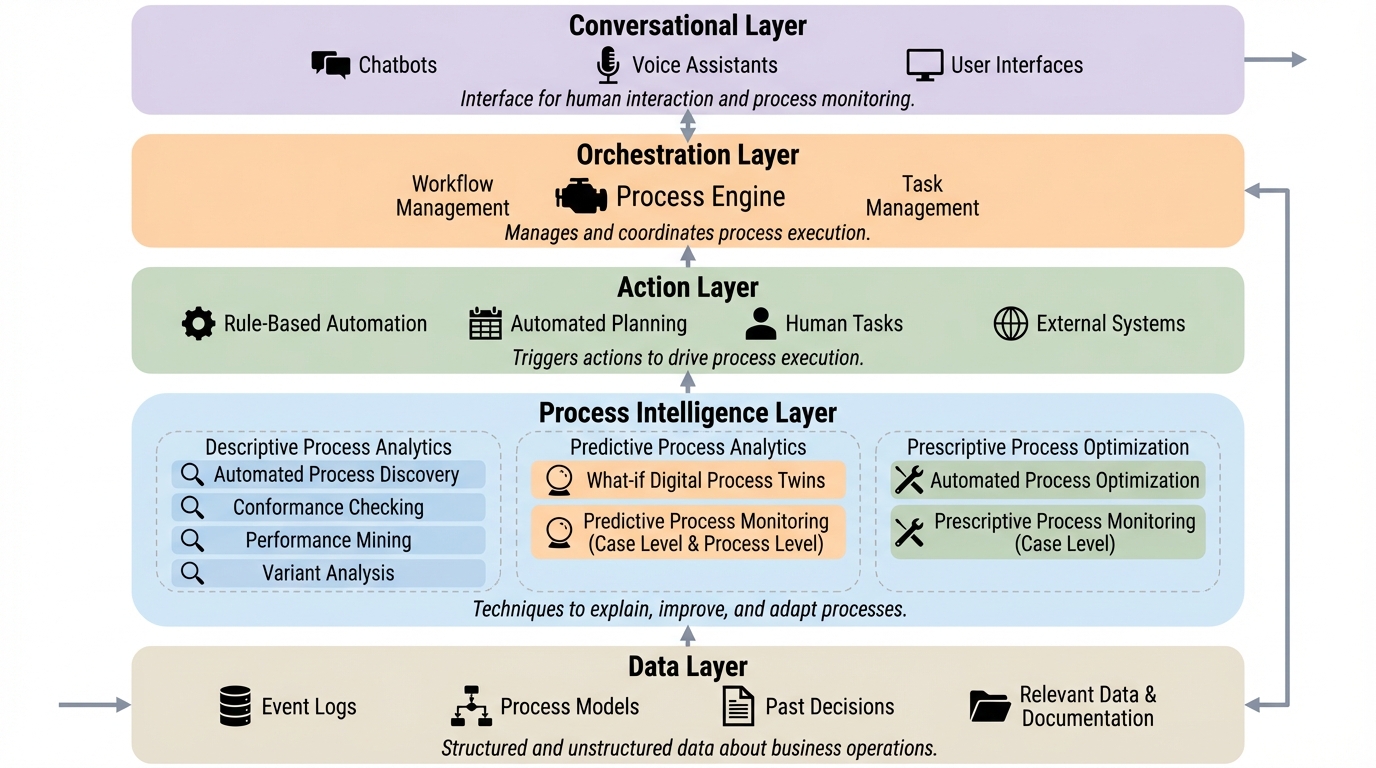
エージェント型ビジネスプロセス管理システム(A-BPMS)は、従来のルールベースの自動化を超え、生成AIやエージェント型AIを活用して自律的なプロセスの実行と最適化を目指す新しいプラットフォームの概念である。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
エージェント型ビジネスプロセス管理システム(A-BPMS)は、従来のルールベースの自動化を超え、生成AIやエージェント型AIを活用して自律的なプロセスの実行と最適化を目指す新しいプラットフォームの概念である。
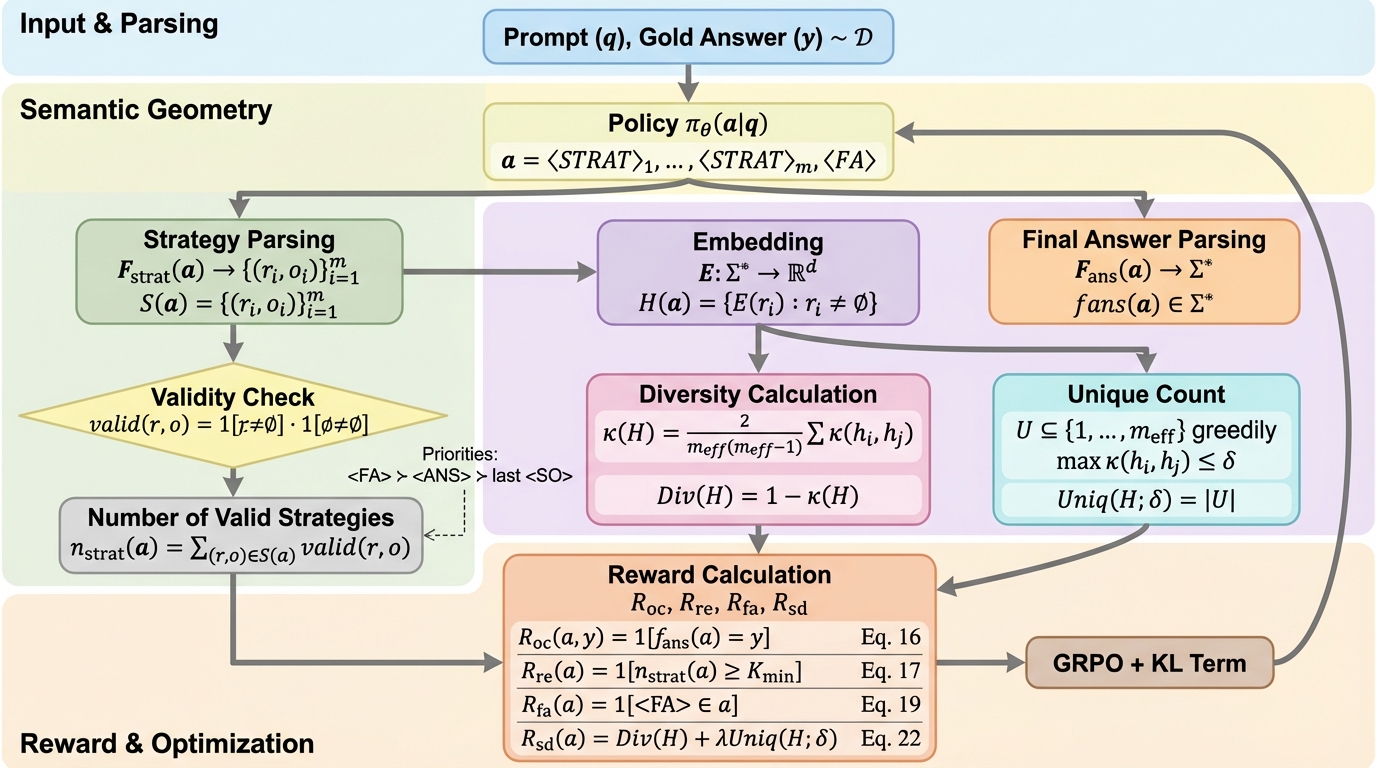
小規模言語モデル(SLM)が限られたトークン予算内で高度な推論を行うため、生成される推論プロセスの「意味的な多様性」を報酬として最適化する新しい強化学習フレームワーク「SD-E$^2$」が提案されました。
従来のマルチモーダル学習は画像とテキストのペアが揃った大規模な中央集権的データを必要としていましたが、医療や金融などの機密分野ではデータが分散し、かつペアが存在しない「ペアなしデータ」の状態が一般的であるという課題がありました。
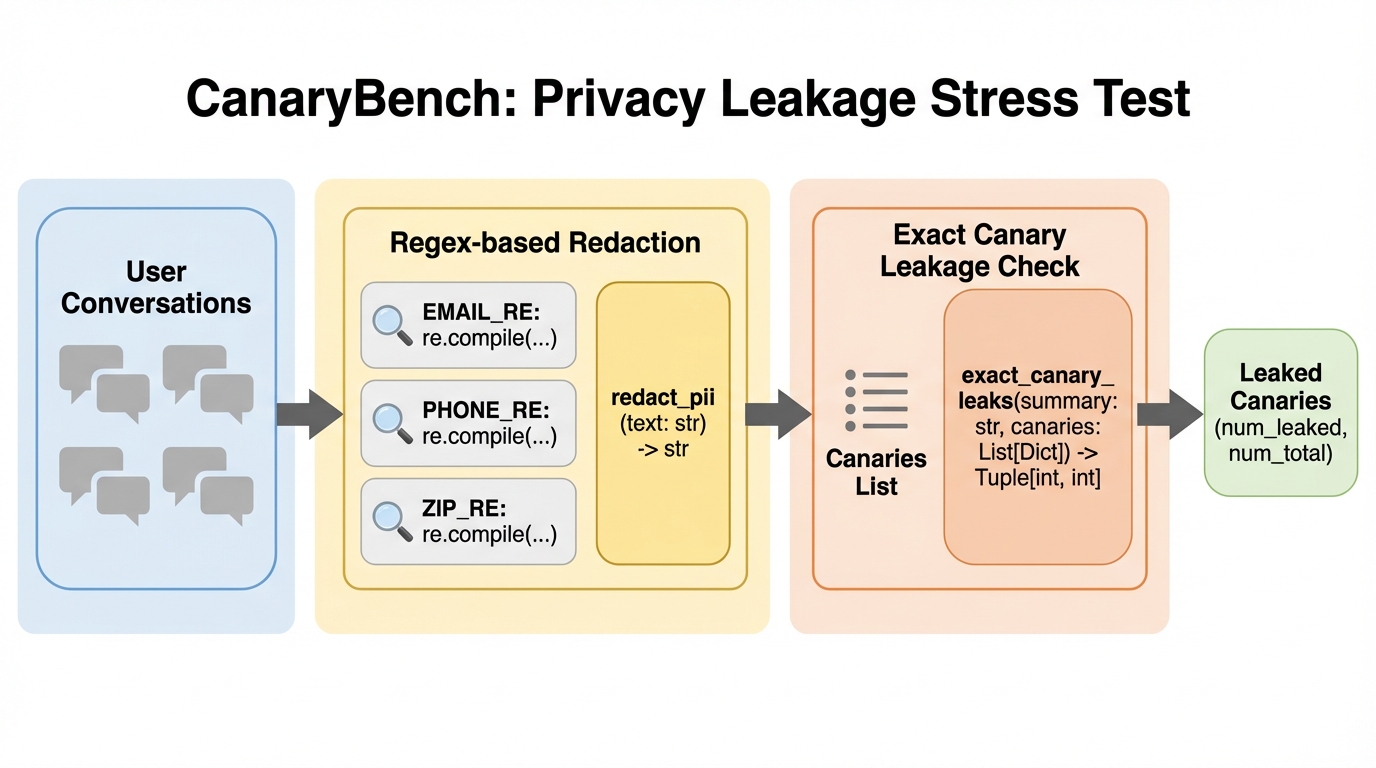
CanaryBenchは、大規模言語モデル(LLM)の会話データをトピックごとにクラスタ化して要約する際、個人の特定につながる情報(PII)がどの程度漏洩するかを測定する新しいベンチマークである。実験の結果、元の会話を直接引用する「抽出型」の要約手法を用いると、特定の識別文字列(カナリア)を含むクラスタの96.
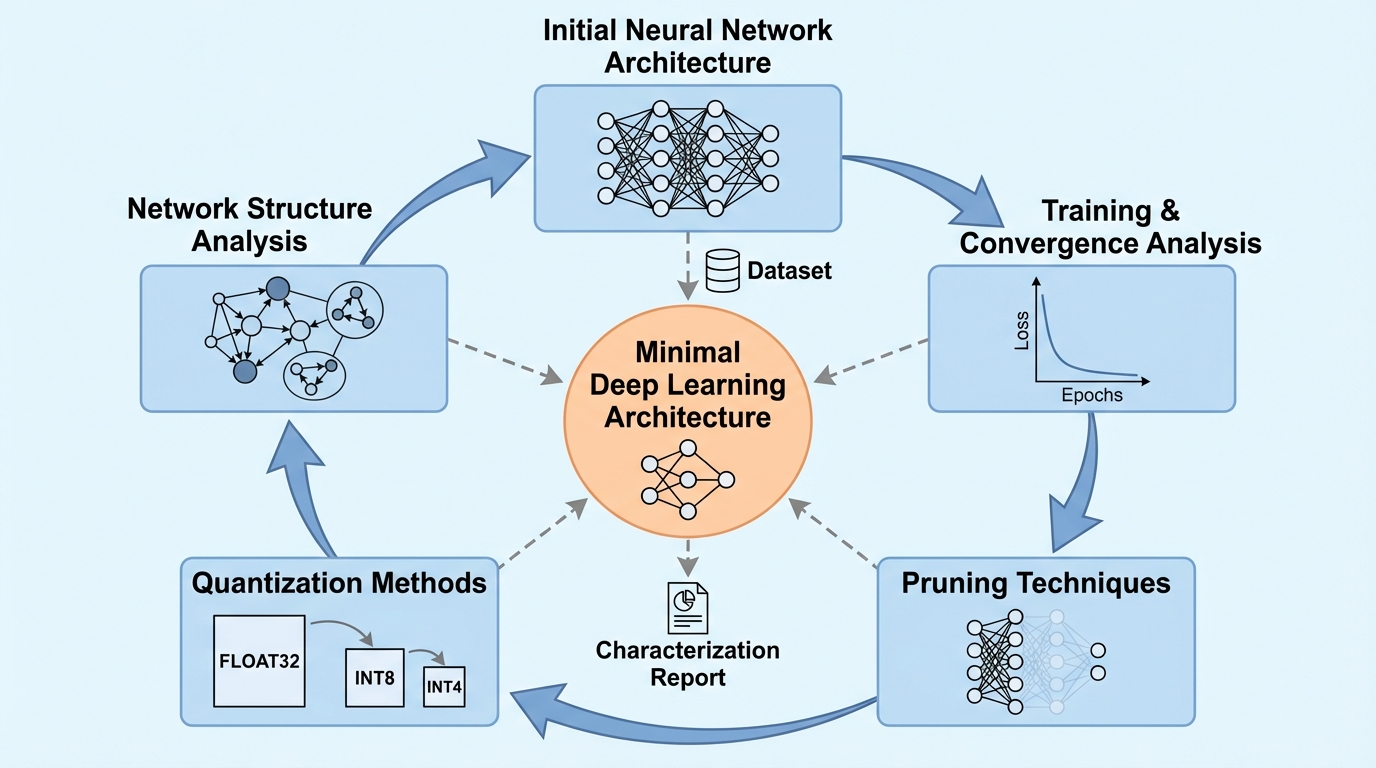
本研究は、深層ニューラルネットワーク(DNN)、畳み込みニューラルネットワーク(CNN)、およびビジョン・トランスフォーマー(ViT)を対象に、特定のタスクを解決するために必要な「最小限のアーキテクチャ」を特定するための統一的な計算手法を提案し、学習の収束性、枝刈りへの耐性、量子化の堅牢性を体系的に解析した。
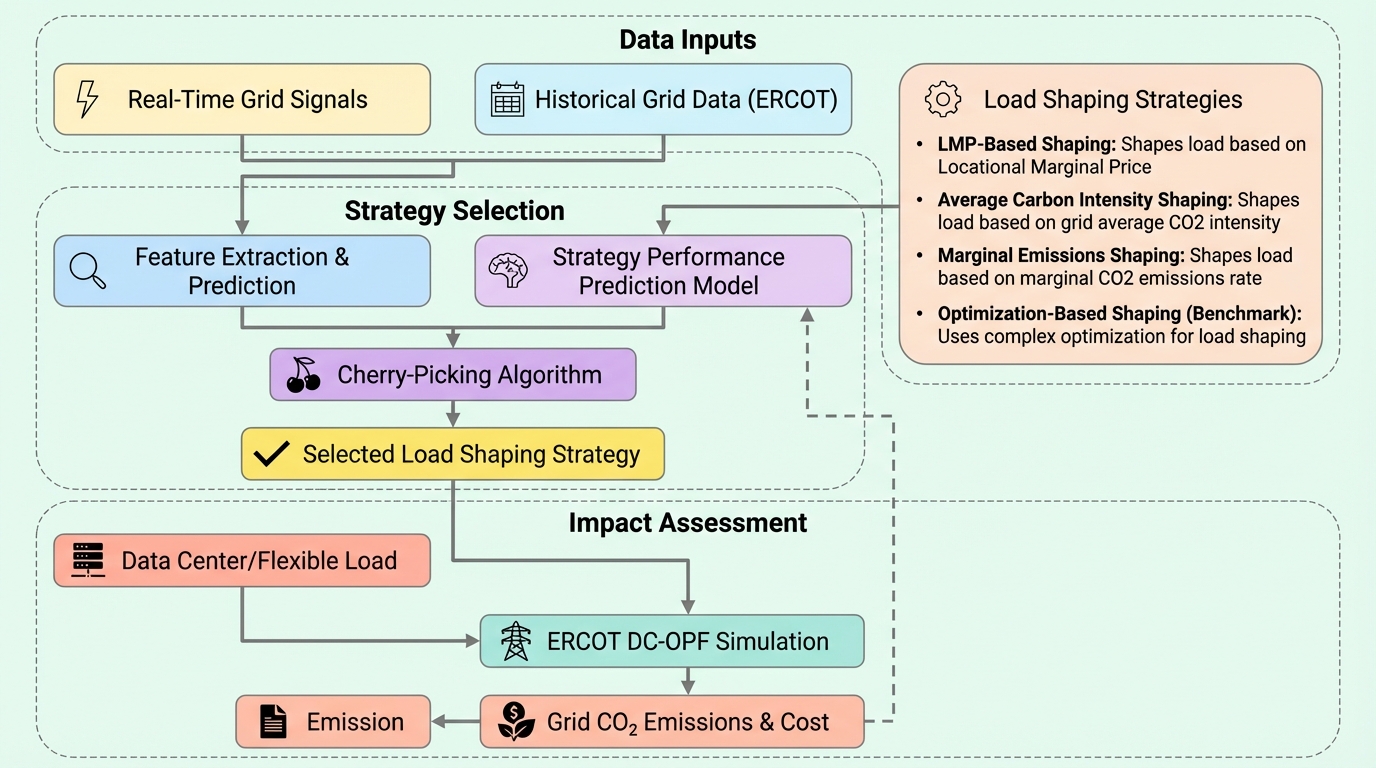
データセンター等の大規模負荷において、単一の指標に頼らず日々の系統信号に基づき最適な制御戦略を「チェリーピッキング(厳選)」することで、従来の価格ベースの手法より2〜3倍高いCO2削減効果が得られることが判明しました。
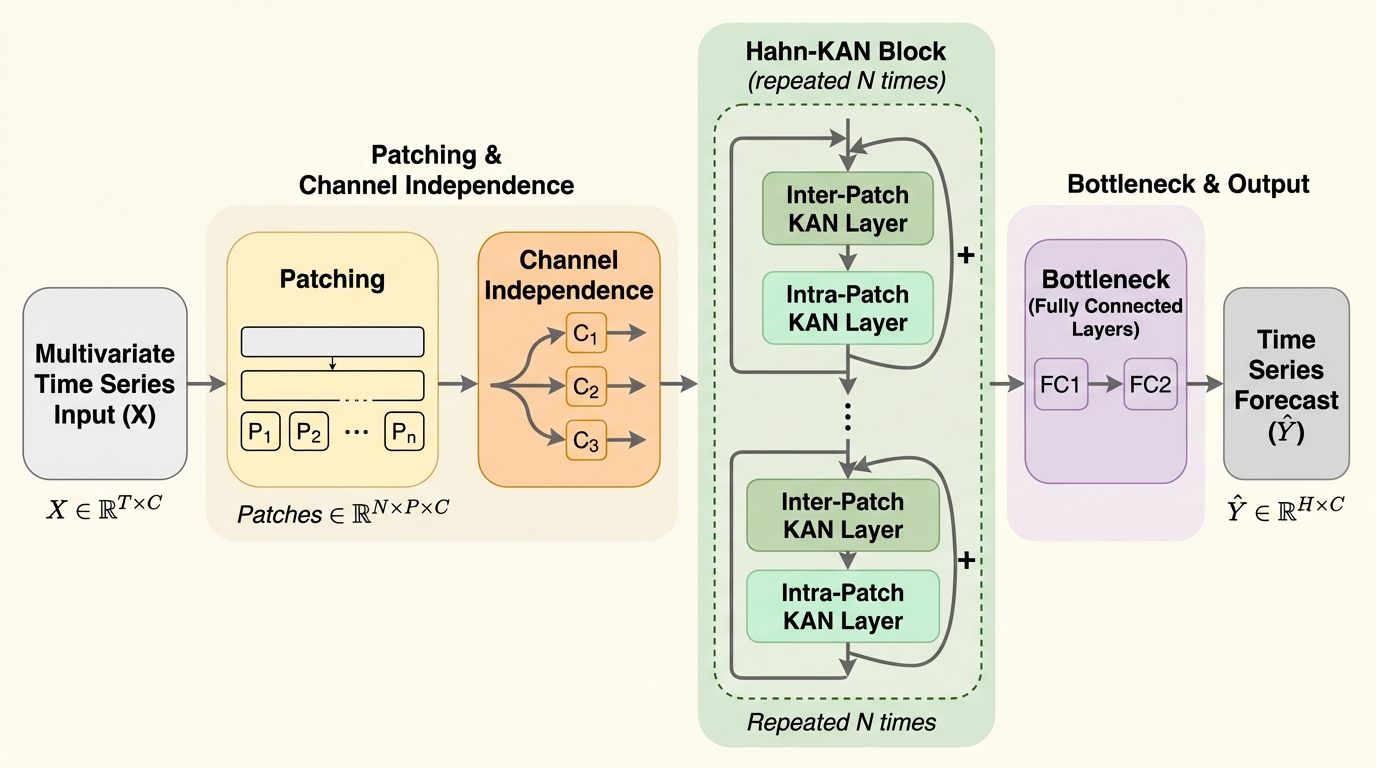
従来の時系列予測で主流だったTransformerの計算量の多さや、MLPが抱える高周波成分の学習の苦手さ(スペクトルバイアス)を解決するため、Hahn多項式を学習可能な活性化関数として組み込んだ新しいネットワーク構造「HaKAN」が開発されました。
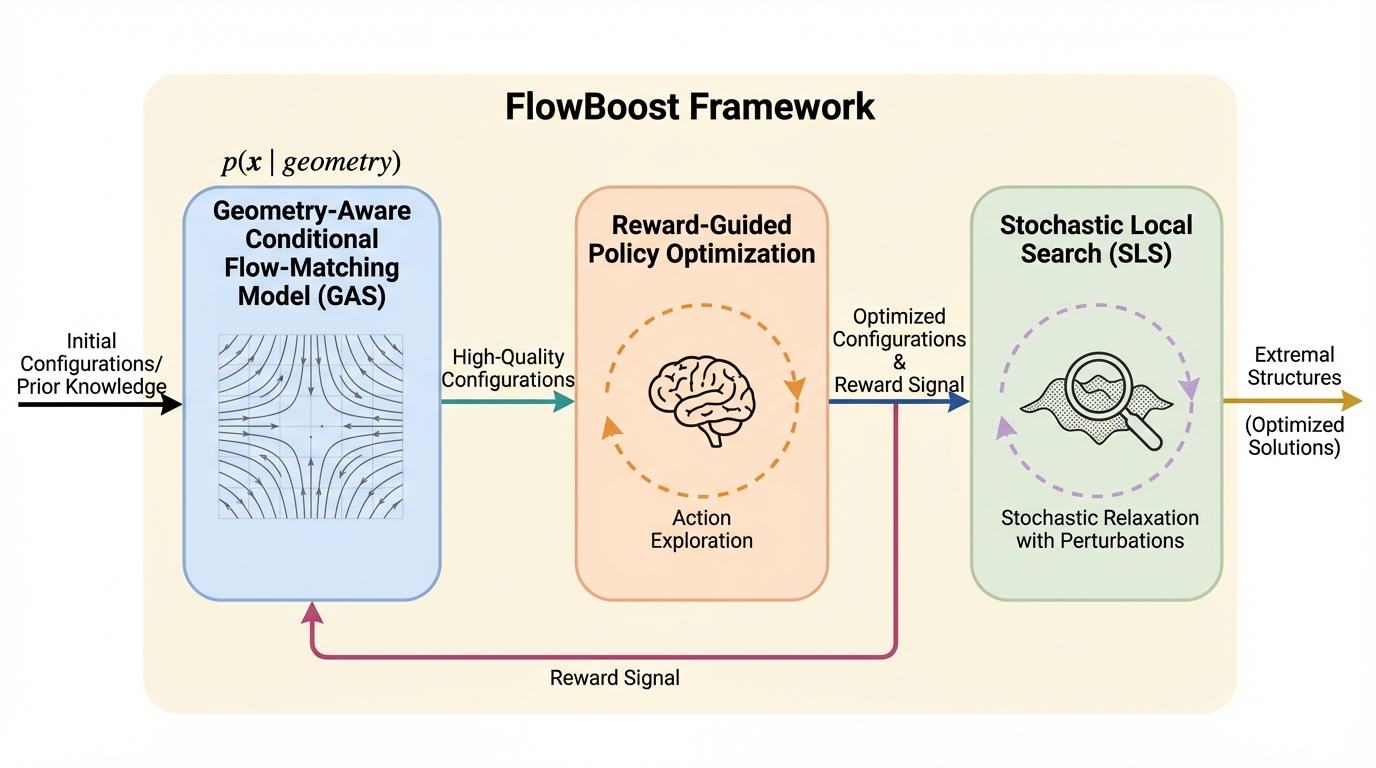
数学の極値幾何学における構造発見において、従来の離散的な手法や大規模言語モデル(LLM)に依存する手法の限界を打破するため、連続的な空間で直接動作する新しい生成フレームワークであるFlowBoostを提案しました。
PEARは、機械翻訳の品質評価(QE)において、従来の1つの翻訳文を独立して絶対評価する手法ではなく、2つの翻訳文を同時に読み込ませてその品質差の方向と大きさを直接予測する「段階的なペアワイズ比較」という新しいフレームワークを提案している。
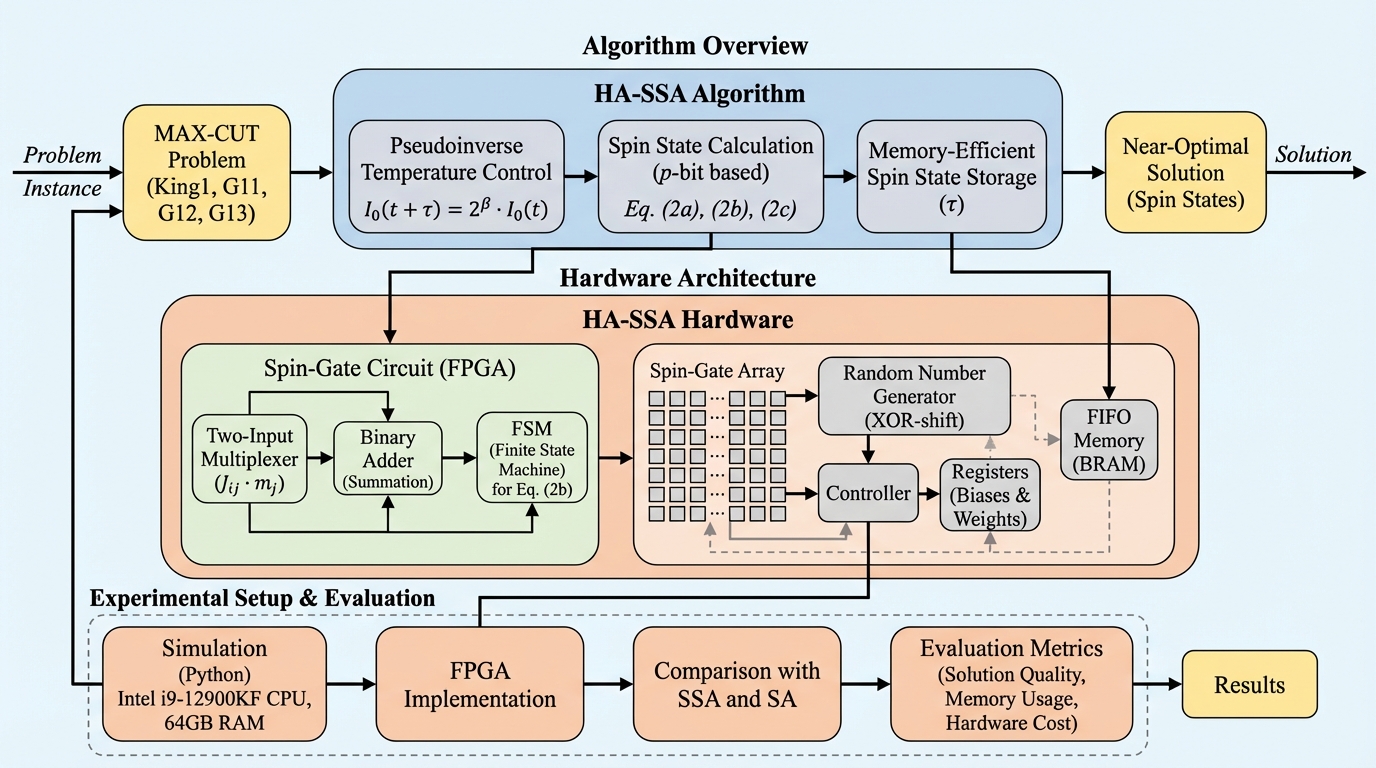
組合せ最適化問題を高速に解く手法として期待される確率的シミュレーテッドアニーリング(SSA)において、ハードウェア実装時の課題であった膨大なメモリ使用量を削減するため、中間状態の保存タイミングを最適化したHA-SSAアルゴリズムが提案されました。