均質なTransformerモデルを用いたペアなしマルチモーダルデータのための連合学習
従来のマルチモーダル学習は画像とテキストのペアが揃った大規模な中央集権的データを必要としていましたが、医療や金融などの機密分野ではデータが分散し、かつペアが存在しない「ペアなしデータ」の状態が一般的であるという課題がありました。
TL;DR(結論)
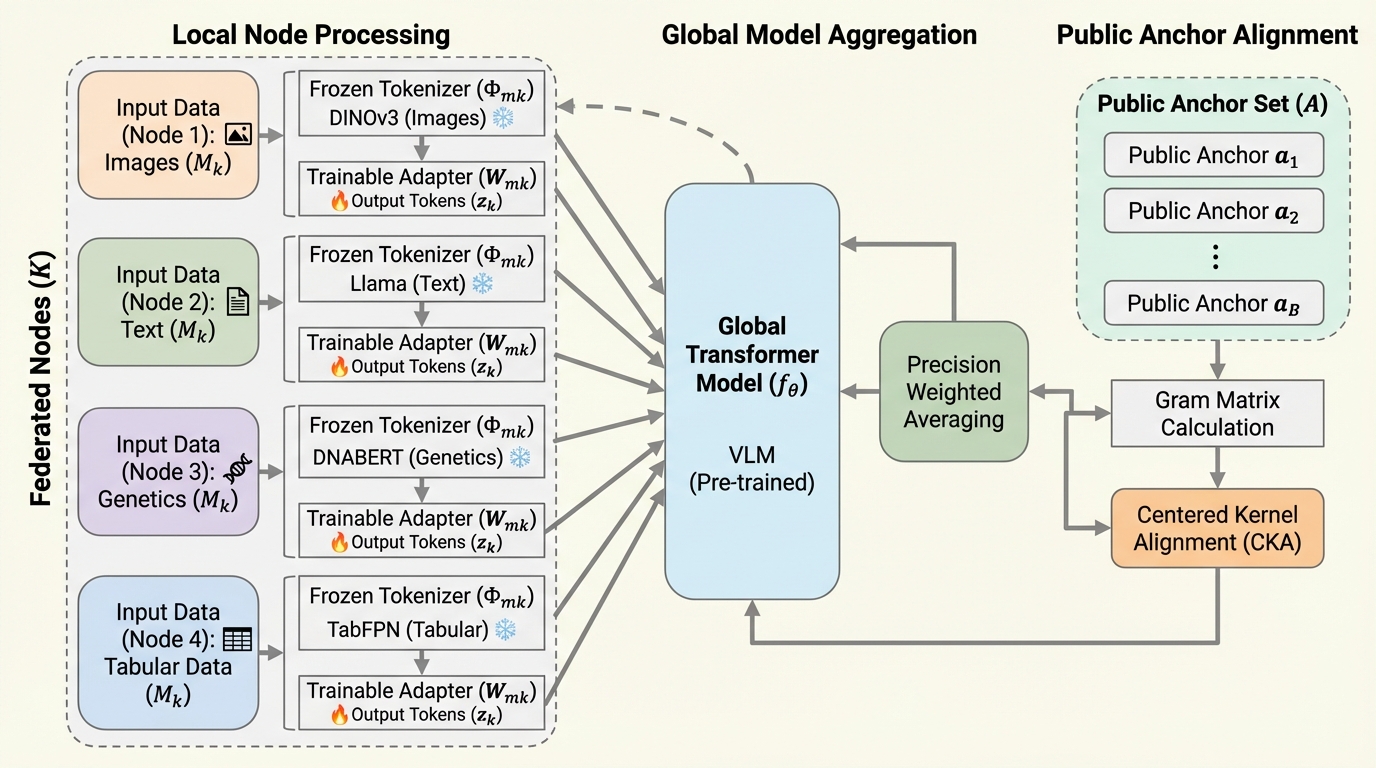
従来のマルチモーダル学習は画像とテキストのペアが揃った大規模な中央集権的データを必要としていましたが、医療や金融などの機密分野ではデータが分散し、かつペアが存在しない「ペアなしデータ」の状態が一般的であるという課題がありました。本研究では、異なるモダリティを共通のトークン形式に変換して単一のTransformerモデルに投入する均質なフレームワークを提案し、データの断片化という問題を根本から解決することを目指しています。 プライバシーを保護しつつ異なる拠点間のデータを整列させるため、少数の公開アンカーセットを利用してデータの幾何学的構造を同期させる手法を導入しており、生のデータや特徴量を共有することなく、数学的に強固なプライバシー保証を実現しています。具体的には、中心化カーネル整列(CKA)とグラム行列を用いることで、各拠点のローカルな多様体をグローバルなコンセンサスに適合させ、異なる種類のデータ間での意味的な整合性を確保することに成功しています。 さらに、通信効率を劇的に向上させるための低ランク近似(LoRA)を拡張したGeoLoRAや、データの不確実性を考慮した精度加重平均プロトコルを提案することで、巨大な基盤モデルを効率的かつ堅牢に連合学習させる仕組みを構築しました。
なぜこの問題か
現代の機械学習において、マルチモーダルな基盤モデルの訓練は、画像とテキストのペアのような整列された膨大なデータセットを中央のデータセンターに集約できる環境に限定されています。しかし、現実世界の連合学習(FL)環境では、データはしばしばペアになっておらず、異なるノード間に断片化されて存在しています。例えば、ある病院のノードには画像データのみがあり、別のノードにはテキスト形式のログのみが保管されているといった状況です。これらのデータセットは厳格なプライバシー保護の対象であり、共通のサンプルを共有することはありません。既存の連合学習手法は、各クライアントが整列されたペアを所有しているか、あるいは生の特徴量埋め込みを共有することを前提としていますが、これはデータの主権を侵害する可能性があり、現実的な運用には適していません。 特に医療分野においては、ペアになったマルチモーダルデータを作成すること自体が非常に困難です。すべての患者に対して画像、テキスト、遺伝子、表形式データといったすべてのモダリティが揃っている必要があり、そのような完全なデータセットは稀です。また、複数のモダリティを組み合わせることは、匿名化の観点からも問題となります。…
核心:何を提案したのか
本研究の核心は、すべてのモダリティを共通のTransformerモデルで処理する「均質なマルチモーダル連合学習フレームワーク」を提案した点にあります。この提案は、異なる基盤モデルが学習を通じて共通の世界表現へと収束していくという「プラトニック表現仮説」に基づいています…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related