SD-E$^2$:トークン予算制約下での推論のための意味的探索
小規模言語モデル(SLM)が限られたトークン予算内で高度な推論を行うため、生成される推論プロセスの「意味的な多様性」を報酬として最適化する新しい強化学習フレームワーク「SD-E$^2$」が提案されました。
TL;DR(結論)
小規模言語モデル(SLM)が限られたトークン予算内で高度な推論を行うため、生成される推論プロセスの「意味的な多様性」を報酬として最適化する新しい強化学習フレームワーク「SD-E$^2$」が提案されました。 この手法は、固定された文埋め込みモデルを用いて推論戦略の重複を幾何学的に測定し、単なる語彙の言い換えではない真に新しい解法の探索を促すとともに、正解発見後は効率的な活用へと切り替える「認知的適応」を実現します。 検証では、Qwen2.5-3B等のモデルを用いて数学(GSM8Kで27.4ポイント向上)や医学の難関タスクで従来手法を大幅に上回る精度を達成し、計算資源が制約された環境下での推論効率を劇的に改善できることが示されました。
なぜこの問題か
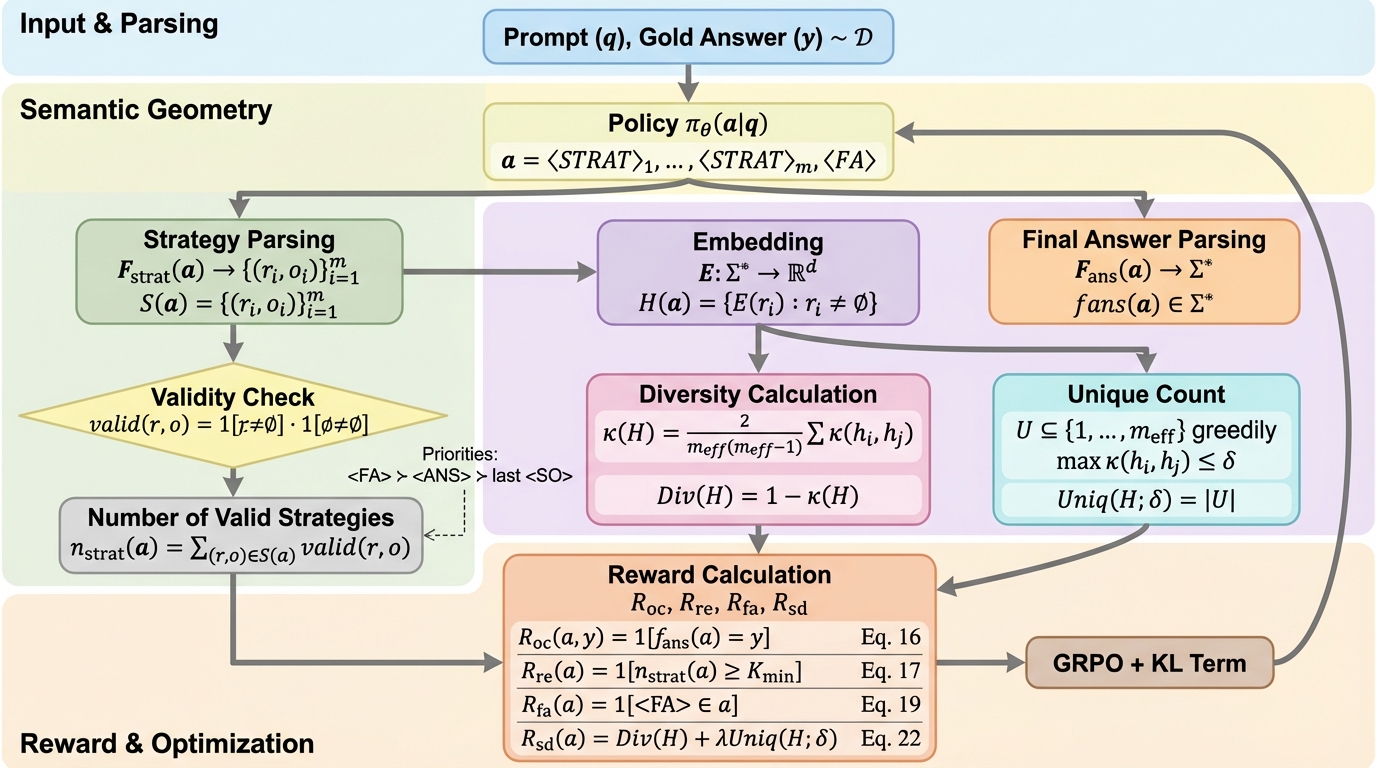
大規模言語モデル(LLM)は数学や科学の分野で驚異的な推論能力を示していますが、その膨大なパラメータ数は運用コストと遅延の増大を招いており、低コストで展開可能な小規模言語モデル(SLM)への期待が高まっています。しかし、SLMはモデル容量の限界から、複雑な推論においてLLMと同等の精度を維持することが困難であり、特に限られたトークン予算の中で「新しい戦略を探索すること」と「有望な道を深掘りして活用すること」のバランスをどう取るかが大きな課題です。従来の強化学習手法であるRLHFやDPO、あるいはDeepSeek-AIなどが採用するGRPOなどは、主に最終的な回答の正誤という疎な信号に依存しており、中間ステップを評価する手法であっても、生成された内容が「意味的に新しいのか」それとも「単に語彙を変えただけなのか」を区別する尺度が欠けていました。 その結果、モデルは同じような失敗戦略を何度も繰り返したり、表面的な表現を変えるだけで実質的な進展がない推論を生成したりするという、非効率な探索行動に陥りやすいという問題がありました。…
核心:何を提案したのか
本研究が提案する「SD-E$^2$(Semantic Diversity – Exploration–Exploitation)」は、意味的な多様性を明示的に報酬化する革新的な強化学習フレームワークです。この手法の核心は、固定された文埋め込みモデル(sentence-embedding model)を活用して、生成された推論プロセスの「意味的な広がり」と「戦略の重複度」を幾何学的に測定することにあります。SD-E$^2$は、モデルが新しい戦略を探索している間、それが既存の試行と意味的に異なれば報酬を与え、逆に似通った内容であれば報酬を抑制します。そして、一度でも正しい解法(戦略)が見つかると、探索から「活用」へと報酬の比重を切り替え、成功した経路を定着させるボーナスを付与します。これを著者らは「認知的適応(cognitive adaptation)」と呼んでいます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related