PEAR:機械翻訳における自動相対スコアリングのためのペアワイズ評価
PEARは、機械翻訳の品質評価(QE)において、従来の1つの翻訳文を独立して絶対評価する手法ではなく、2つの翻訳文を同時に読み込ませてその品質差の方向と大きさを直接予測する「段階的なペアワイズ比較」という新しいフレームワークを提案している。
TL;DR(結論)
PEARは、機械翻訳の品質評価(QE)において、従来の1つの翻訳文を独立して絶対評価する手法ではなく、2つの翻訳文を同時に読み込ませてその品質差の方向と大きさを直接予測する「段階的なペアワイズ比較」という新しいフレームワークを提案している。 このモデルは、人間による評価の差分を教師信号として学習し、翻訳文の入力順序を入れ替えても一貫した結果を出力する反対称正則化を導入することで、従来の単一評価モデルや、より大規模なパラメータを持つ既存のQEモデル、さらには参照訳を用いるメトリクスをも上回る精度を達成した。 参照訳がない状況でも高い相関性を示し、計算コストを抑えつつシステム間の比較や最小ベイズリスク(MBR)デコーディングの効用関数として有効に機能することが確認されており、現代の高品質な翻訳評価における非常に微妙な差異を識別するタスクにおいて極めて優れた実用性を持っている。
なぜこの問題か
現代の機械翻訳(MT)評価において、自動メトリクスはシステムの比較やモデル選択、ランキング作成に不可欠なツールとなっている。しかし、多くの既存メトリクスは、ソース文と1つの翻訳文を入力として絶対的なスコアを出力する構造を採用している。翻訳品質が向上し、優れたシステム同士の差が非常にわずかなものになるにつれ、単一の翻訳文を独立して評価する手法では、その微妙な品質の差を正確に捉えることが困難になっている。人間による評価においても、絶対的な評価値を与えるよりも、2つの翻訳文を並べてどちらが優れているかを判断する比較評価の方が、一貫性が高く、評価者間の合意が得られやすいことが先行研究で示されている。 PEARの開発チームは、この人間による比較の優位性を自動評価にも取り入れるべきだと考えた。従来の絶対評価に基づくQE(Quality Estimation)モデルでは、2つの翻訳文を比較する際にそれぞれの絶対スコアを算出して引き算を行うが、これは比較というタスクに対して最適化されたアプローチではない可能性がある。…
核心:何を提案したのか
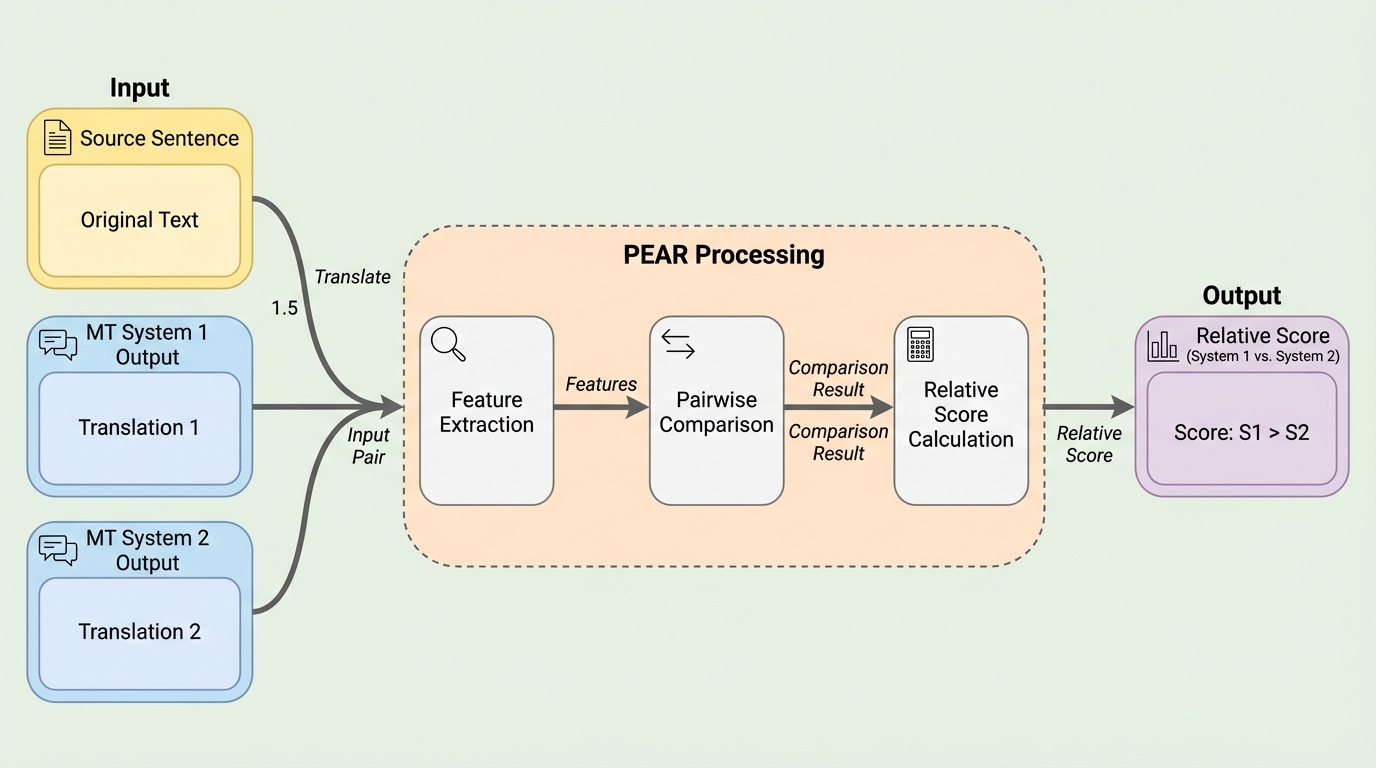
本研究では、機械翻訳の参照訳不要な評価(QE)を、段階的なペアワイズ比較タスクとして再構成する新しいメトリクス群「PEAR(Pairwise Evaluation for Automatic Relative Scoring)」を提案した。PEARは、ソースセグメントと2つの候補翻訳文を同時に入力として受け取り、それらの品質差の方向(どちらが優れているか)と大きさ(どの程度の差があるか)を直接予測する。出力されるスコアが正であれば1つ目の翻訳文が優れており、負であれば2つ目が優れていることを示し、値がゼロに近いほど両者の品質が拮抗していることを意味する。 この手法の核心は、比較を単なる2値の分類問題として扱うのではなく、連続的な数値としての「差」を予測する回帰問題として定式化した点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related