表現準同型はTransformer言語モデルにおける構成的汎化を予測し改善する
ニューラルネットワークが既知の要素を未知の組み合わせで理解する「構成的汎化」は長年の難題であり、本研究ではモデルの内部表現が代数的な構成構造をどの程度保持しているかを定量化する新指標「準同型誤差(HE)」を提案した。 実験の結果、この準同型誤差はノイズ環境下での分布外(OOD)への汎化性能と強い相関(決定係数0.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
ニューラルネットワークが既知の要素を未知の組み合わせで理解する「構成的汎化」は長年の難題であり、本研究ではモデルの内部表現が代数的な構成構造をどの程度保持しているかを定量化する新指標「準同型誤差(HE)」を提案した。 実験の結果、この準同型誤差はノイズ環境下での分布外(OOD)への汎化性能と強い相関(決定係数0.
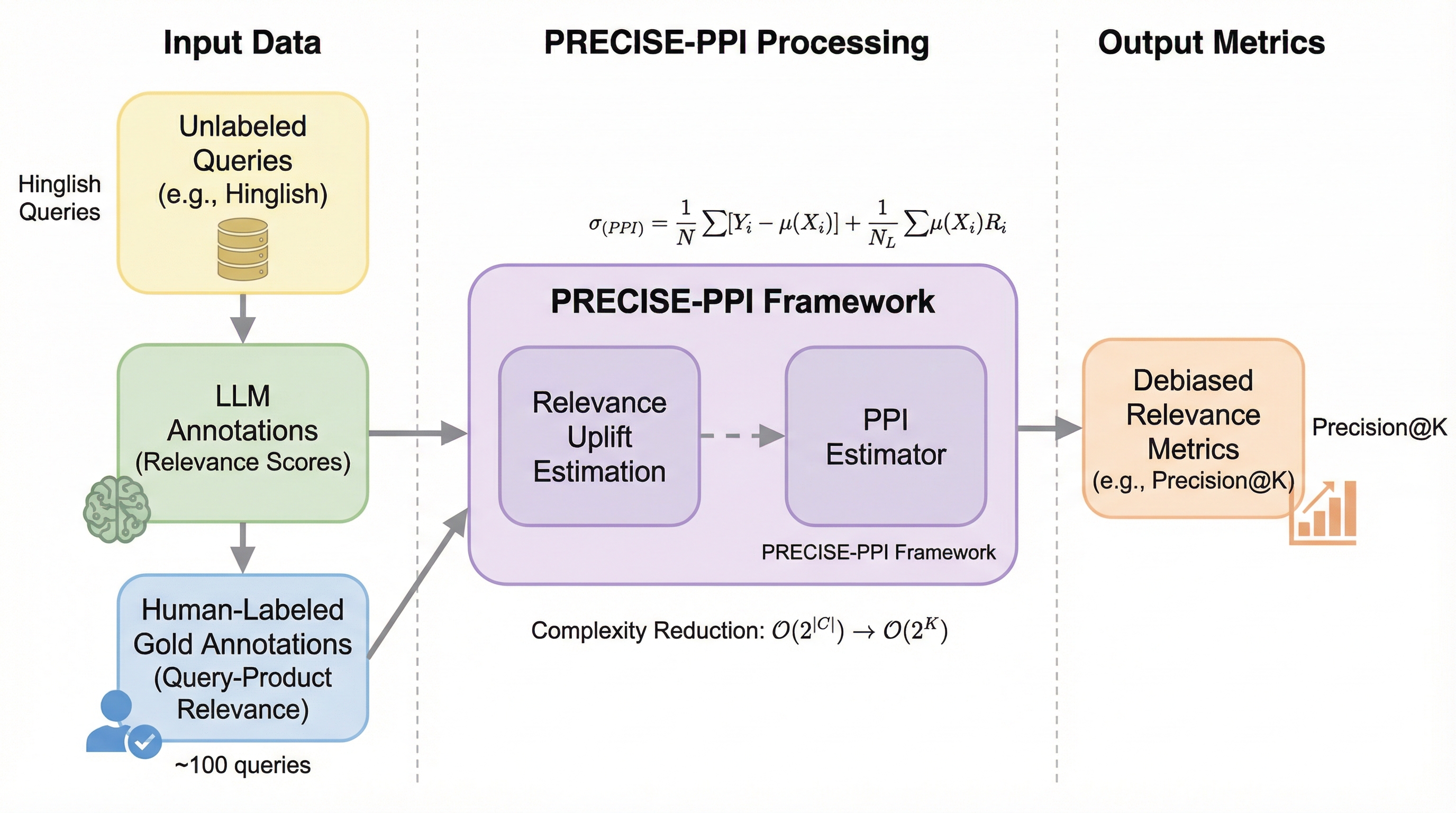
検索システムの評価において、膨大な人的コストと大規模言語モデル(LLM)固有のバイアスが課題となる中、本研究では少数の人間による注釈と大量のLLM判定を統計的に融合させる新フレームワーク「PRECISE」を提案した。
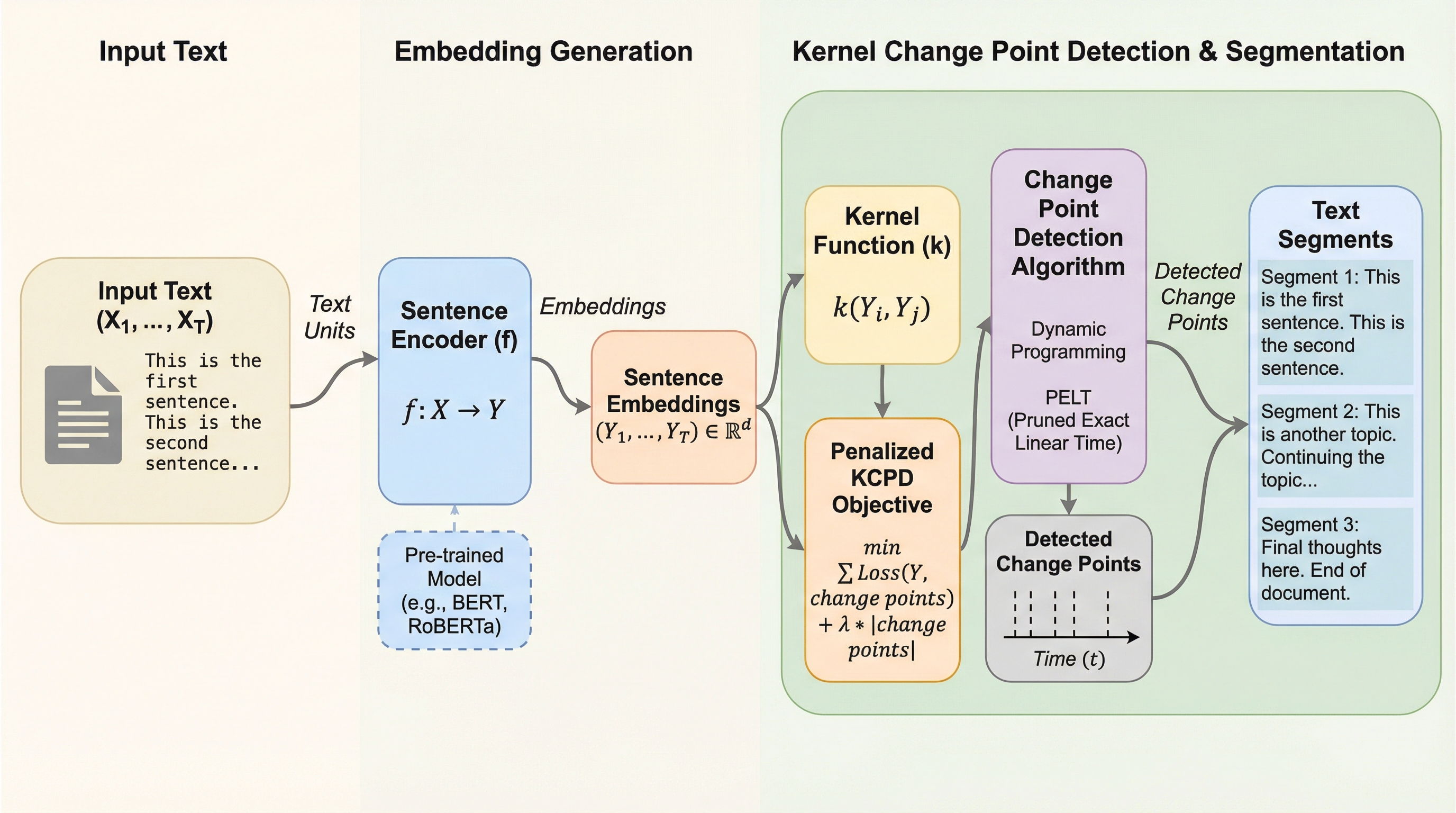
テキストセグメンテーションにおける境界ラベルの付与コストや主観性の問題を解決するため、事前学習済みの文埋め込みとカーネル変化点検出(KCPD)を組み合わせた、学習不要で汎用性の高い教師なし手法「Embed-KCPD」が提案されました。
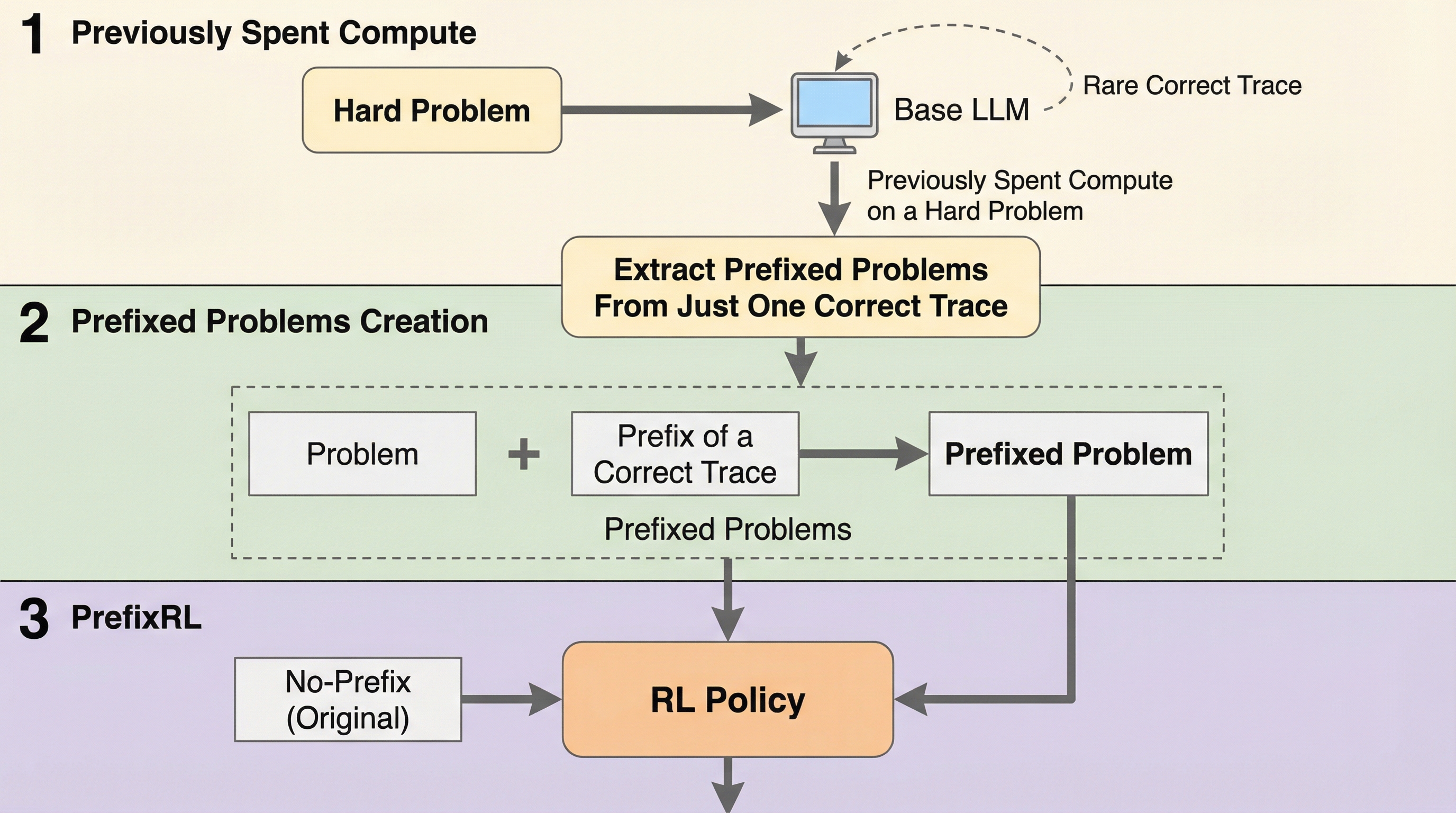
大規模言語モデルの数学やコーディング等の難問解決において、正解が稀なために学習が停滞する課題に対し、過去の成功トレースの冒頭部分を「プレフィックス」として与えることでオンポリシー学習を導く新手法「PrefixRL」を提案しました。
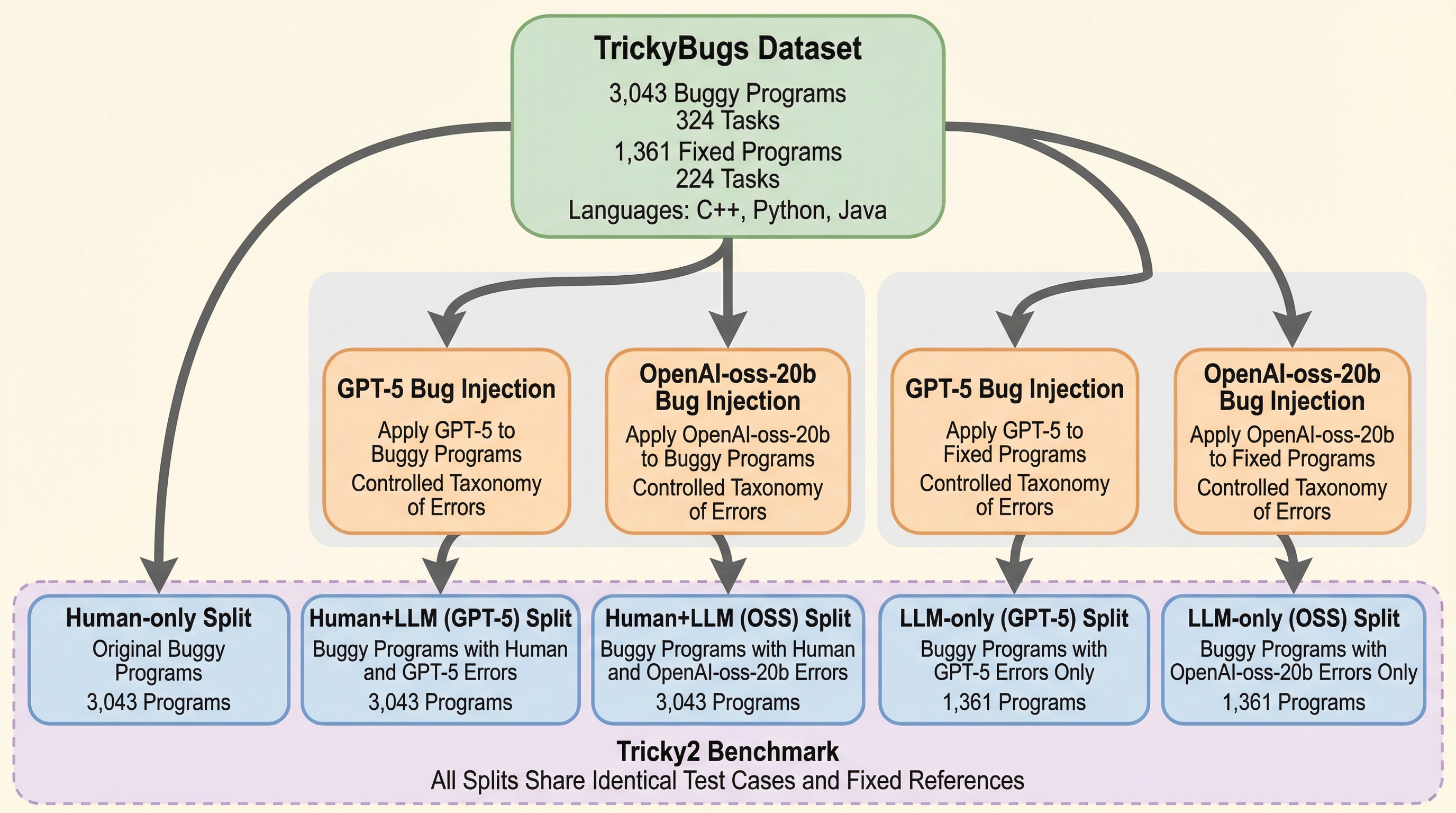
ソフトウェア開発において大規模言語モデル(LLM)の活用が急速に広がる中で、人間が書いたコードとAIが生成したコードが混在する環境での信頼性確保が重要な課題となっています。本研究では、人間由来のバグとLLMが生成したバグが同一プログラム内で共存する「混合起源エラー」を評価するための新しいベンチマーク「Tricky$^2$」を提案し、その複雑性を体系的にモデル化しました。検証の結果、人間とAIのバグが組み合わさることでエラー同士が互いを隠蔽または悪化させる相互作用が発生し、単一のバグ修正よりも難易度が劇的に上昇することが実証されました。
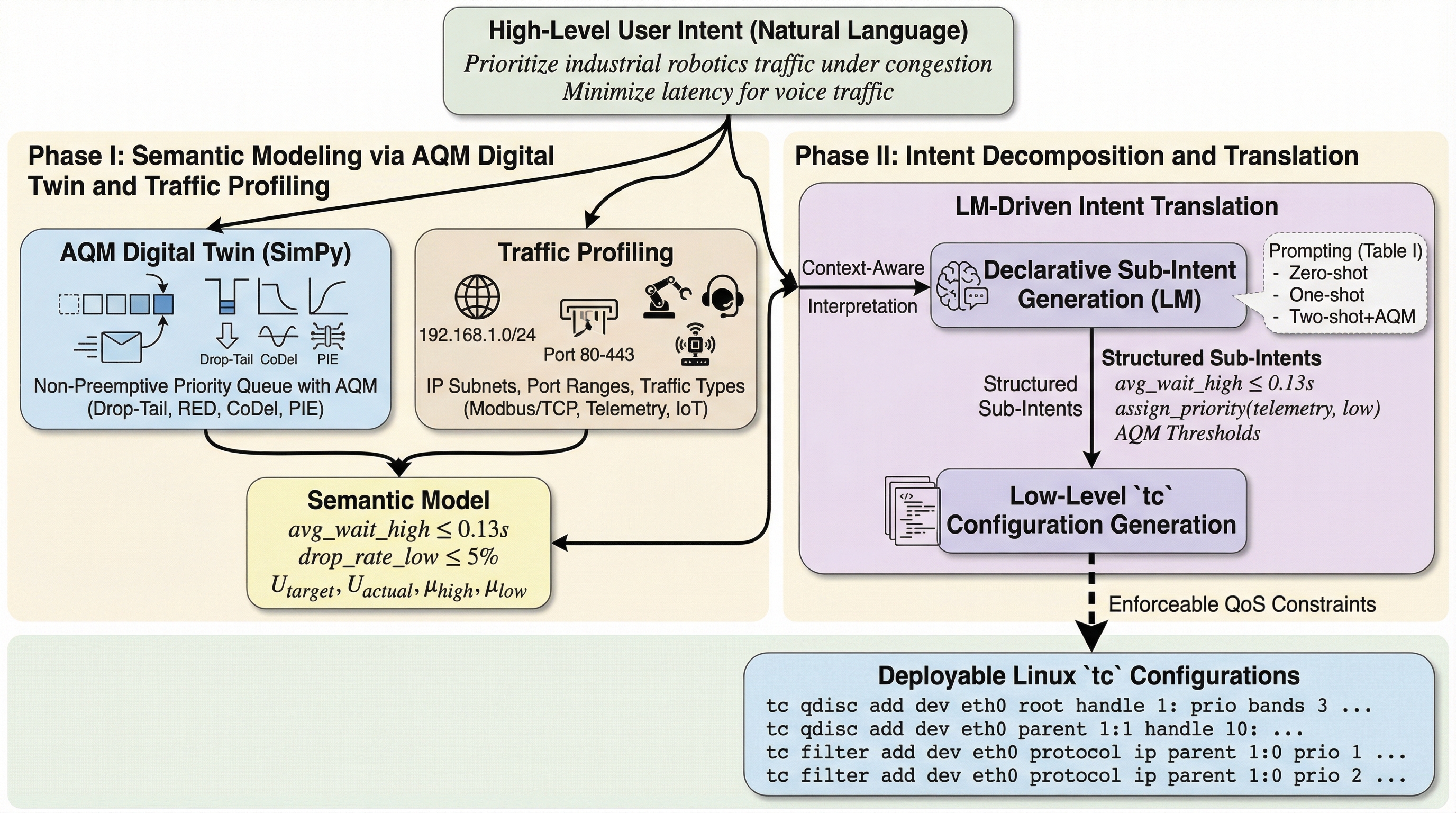
ネットワーク管理者が自然言語で記述した抽象的な「意図」を、Linuxのトラフィック制御(tc)ルールへ自動変換するエンドツーエンドのパイプライン「Intent2QoS」を提案しました。このシステムは、管理者が「ビデオ会議の遅延を最小限にする」といった高レベルな目標を入力するだけで、複雑な低レベルコマンドを自動生成し、専門知識が不足している環境でも高度なQoS設定を可能にします。 キューイング理論に基づくデジタルツインを用いたセマンティックモデルと言語モデルを統合することで、従来の言語モデル単体では困難だったネットワークの物理的挙動の考慮と正確な設定生成を実現しました。これにより、単なる構文の正しさだけでなく、遅延やパケットドロップ率といった物理的な制約を反映した、実際にデプロイ可能な設定セットの出力が可能になります。 100件の意図を用いた検証では、LLaMA3(8B)がセマンティック類似度0.88を達成し、AQM情報を活用したプロンプト手法により設定のばらつきを従来の3分の1に抑制できることが示されました。このフレームワークは、手動設定に伴うヒューマンエラーを排除し、ネットワーク運用のスケーラビリティを大幅に向上させる強力な基盤を提供します。
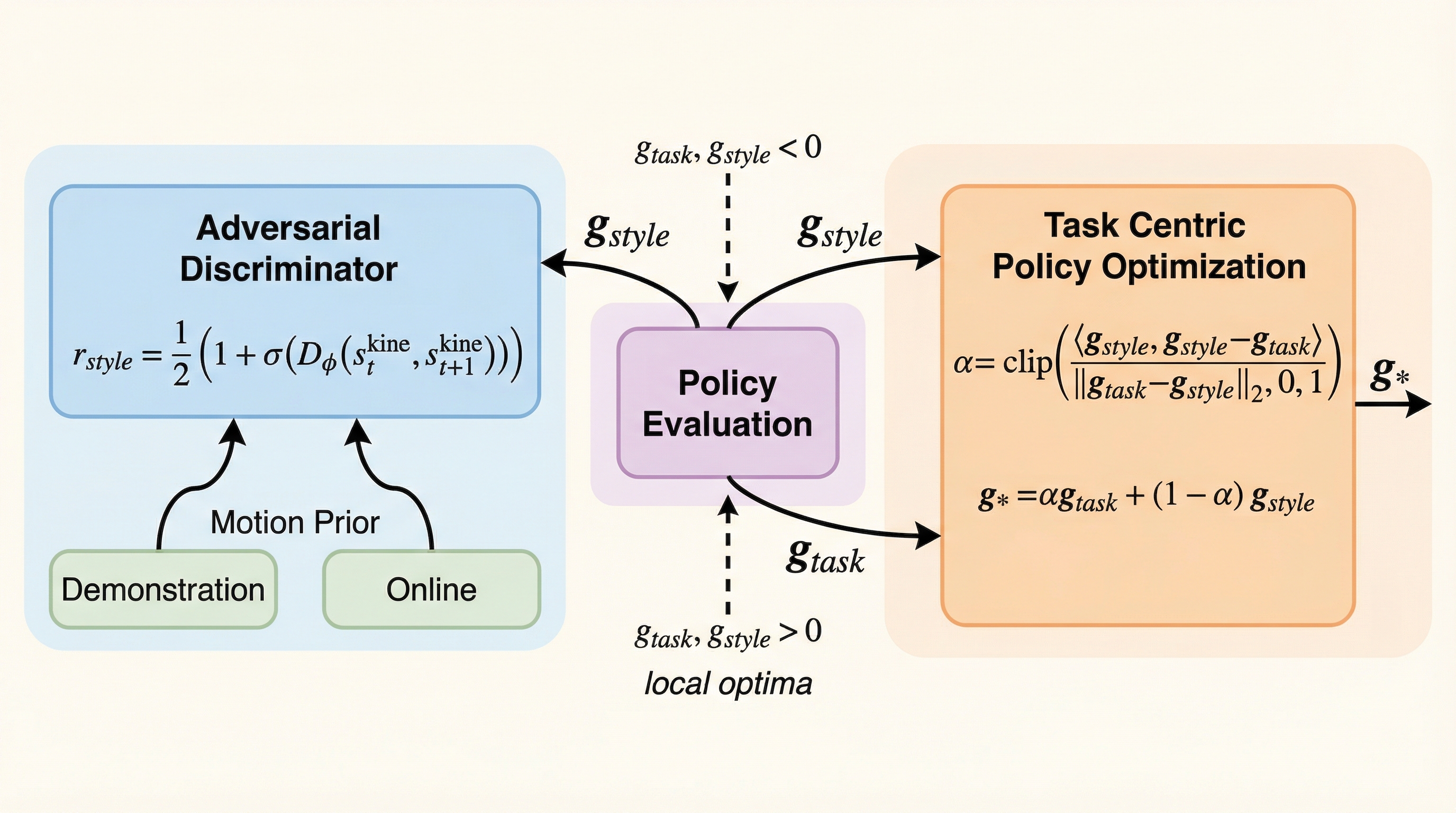
ヒューマノイドロボットの制御において、人間の動作データを模倣する手法は自然な動きを実現する一方で、ロボットの身体構造との違いやタスクとの不整合により、単純な模倣がタスク性能を著しく低下させるという深刻な課題がありました。
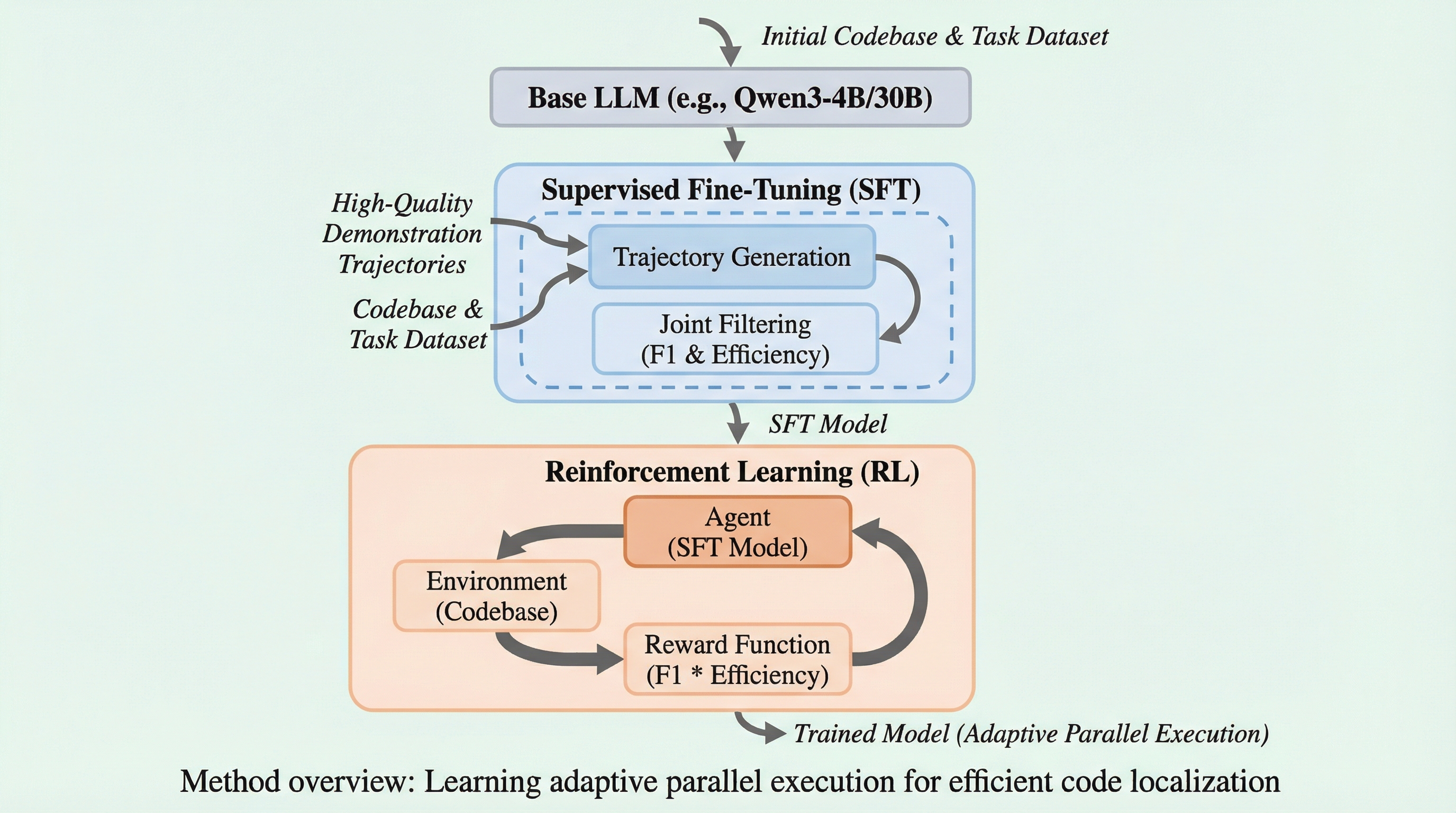
ソフトウェア開発の自動化において、修正箇所を特定するコード位置特定は計算リソースの半分以上を消費する大きなボトルネックです。従来手法は逐次実行による情報不足や、固定的な並列化による34.9%もの冗長な呼び出しという課題を抱えていましたが、本研究の「FuseSearch」は情報の新規性と呼び出し回数の比率を「ツール効率」として定義し、適応的な並列実行戦略を学習しました。 検証の結果、4Bパラメータの小型モデルでありながらSWE-bench VerifiedでファイルレベルF1スコア84.7%を達成し、実行時間を93.6%、消費トークン量を68.9%削減するという、圧倒的な品質とコストパフォーマンスの両立を実現しています。 この手法は、情報の新規性を常に監視しながら並列度を動的に調整することで、冗長な信号を排除し、最終的な位置特定の精度を向上させるという相乗効果をもたらしており、実用的な自動開発エージェントの構築に向けた新たな標準を提示しています。
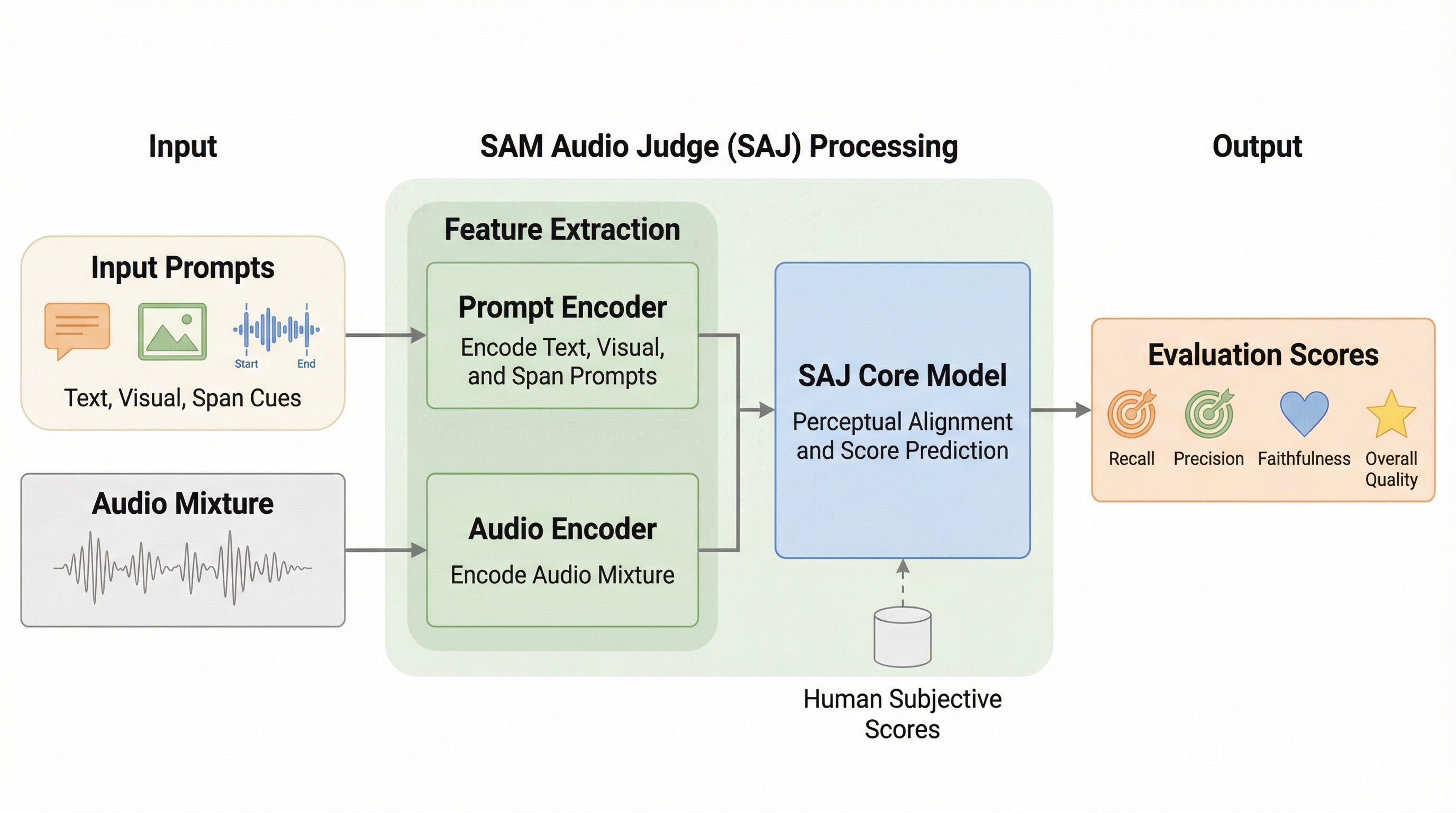
従来の音源分離評価で主流だったSDRなどの指標は、正解信号への依存や人間の知覚との乖離という大きな課題を抱えていましたが、本研究では正解信号を必要とせず、人間の知覚と高度に一致する新しい客観的評価指標「SAM Audio Judge(SAJ)」を開発しました。
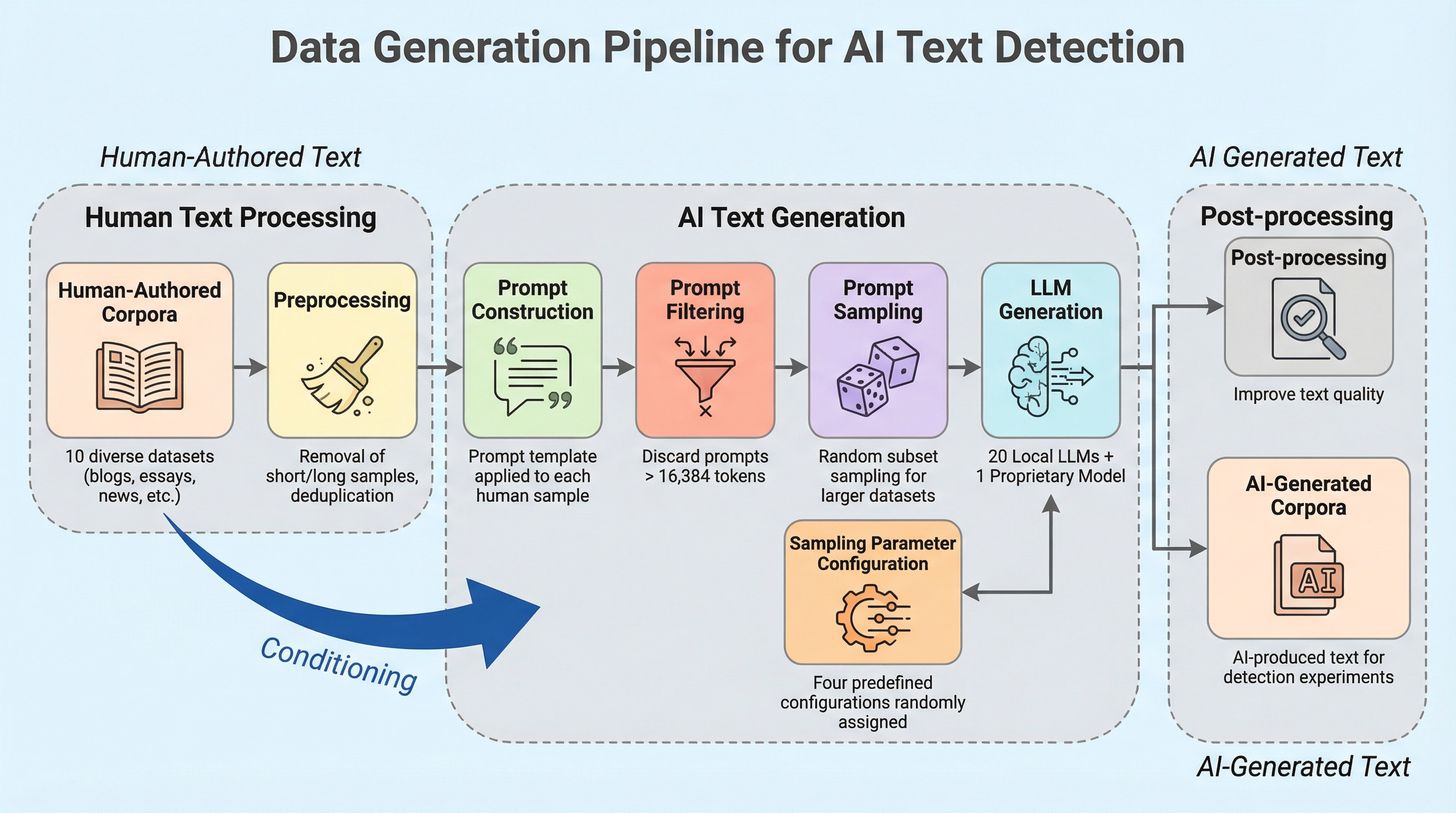
人間が書いた10億トークンの著作物と、21種類の言語モデルから生成された19億トークンのテキストを組み合わせた、合計29億トークンに及ぶ大規模なコーパスを構築し、AI生成テキストを識別するための新しい学習手法を提案した。