FLOPsを再利用せよ:非常にオフポリシーなプレフィックスによる条件付けを用いた、困難な問題における強化学習のスケールアップ
大規模言語モデルの数学やコーディング等の難問解決において、正解が稀なために学習が停滞する課題に対し、過去の成功トレースの冒頭部分を「プレフィックス」として与えることでオンポリシー学習を導く新手法「PrefixRL」を提案しました。
TL;DR(結論)
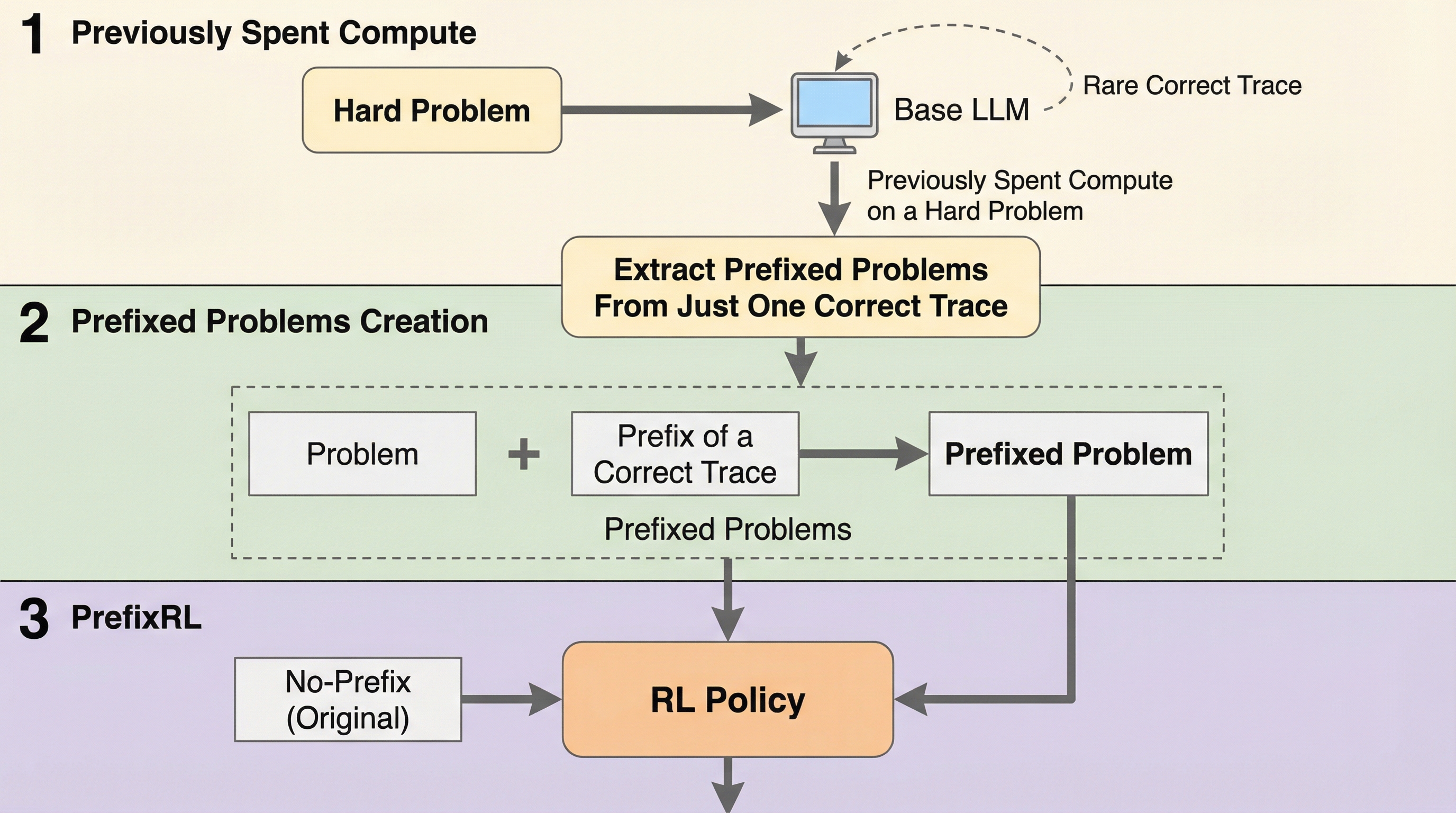
大規模言語モデルの数学やコーディング等の難問解決において、正解が稀なために学習が停滞する課題に対し、過去の成功トレースの冒頭部分を「プレフィックス」として与えることでオンポリシー学習を導く新手法「PrefixRL」を提案しました。成功データの接頭辞に続く部分のみをモデルに生成・学習させることで、オフポリシー学習特有の不安定さを回避しつつ、難易度を適切に調整して強力な報酬信号を復活させ、学習効率を劇的に向上させることに成功しています。プレフィックス付きの問題での学習が元の問題の性能も向上させる「バック一般化」を確認し、計算効率を2倍、最終的な報酬を3倍に高めるとともに、異なるモデル間のデータ転用でも高い柔軟性と汎用性を示すことを実証しました。
なぜこの問題か
大規模言語モデル(LLM)の数学的推論やコーディング能力を向上させるために、強化学習(RL)は極めて重要な役割を果たしています。しかし、現在主流となっているオンポリシー強化学習には、問題の難易度が非常に高い場合に学習が完全に停滞するという致命的な欠点が存在します。正解率が極めて低い難問においては、モデルが正解のトレースを自力で生成できる確率がほぼゼロに等しく、学習の指針となる報酬信号が全く得られないため、膨大な計算資源(FLOPs)を投入しても勾配が消失し、性能が向上しない「停滞レジーム」に陥ってしまいます。この問題を解決するために、過去の推論過程や以前の学習で得られた「オフポリシーデータ」を再利用する手法が検討されてきたが、既存のアプローチにはそれぞれ重大な副作用が伴います。 例えば、成功したトレースを用いて教師あり微調整(SFT)を行う「ミッドトレーニング」手法では、モデルが特定の正解を丸暗記してしまい、トークンの多様性を示すエントロピーが急激に減少する「エントロピー崩壊」を引き起こします。これにより、その後の強化学習における探索能力が著しく損なわれ、最終的な性能が頭打ちになることが分かっています。…
核心:何を提案したのか
本研究では、オフポリシーの成功トレースを直接的な学習目標(教師)として扱うのではなく、オンポリシーな探索を導くための「条件(プレフィックス)」として利用する新しい強化学習フレームワーク「PrefixRL」を提案しました。この手法の核心は、成功したトレースの冒頭部分を問題文に付加して「プレフィックス付き問題」を作成し、その続きを現在のモデルに生成させることで、オンポリシー強化学習の枠組みの中で学習を進める点にあります。PrefixRLは、オフポリシーデータの接頭辞を固定し、その後の生成部分に対してのみ勾配を適用します。これにより、モデルは現在のモデルの確率分布から遠いトークン列を直接模倣することを強制されず、オフポリシー学習に伴う不安定さを回避できます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related