大規模言語モデル(LLM)特化型ファインチューニングによるAI生成テキスト検出の有効性
人間が書いた10億トークンの著作物と、21種類の言語モデルから生成された19億トークンのテキストを組み合わせた、合計29億トークンに及ぶ大規模なコーパスを構築し、AI生成テキストを識別するための新しい学習手法を提案した。
TL;DR(結論)
人間が書いた10億トークンの著作物と、21種類の言語モデルから生成された19億トークンのテキストを組み合わせた、合計29億トークンに及ぶ大規模なコーパスを構築し、AI生成テキストを識別するための新しい学習手法を提案した。 「モデルごと」および「モデルファミリーごと」のファインチューニングという2つの新しいパラダイムを導入し、テキスト全体の文脈を考慮したトークンレベルの分類を行うことで、既存のオープンソースの基準を大幅に上回る検出精度を実現した。 1億トークンのベンチマークにおいて最大99.6%のトークンレベル精度を達成し、教育、出版、デジタルセキュリティにおける真正性検証の課題に対し、高度な生成テキストを極めて高い確率で識別できることを実証した。
なぜこの問題か
大規模言語モデル(LLM)の急速な進歩により、人間が書いたものと見分けがつかないほど自然で流暢なテキストの生成が可能になった。OpenAIのGPTシリーズ、GoogleのGemini、AnthropicのClaudeといったモデルは、カスタマーサポートやジャーナリズム、クリエイティブな執筆活動において前例のない機会を提供する一方で、テキストの真正性を検証するという技術的および倫理的な課題を突きつけている。AI生成テキストの識別は、教育、出版、デジタルセキュリティの分野で極めて重要な問題となっている。特に教育現場では、学生がLLMを使用してエッセイやレポート、宿題を作成することで、学術的な誠実さや評価の妥当性が損なわれる懸念がある。既存の検出ツールは不完全であり、AIが書いたテキストを見逃す「偽陰性」や、人間が書いたテキストをAIによるものと誤判定する「偽陽性」が高い割合で発生しており、これが検出ツールやそれに基づく学術政策への信頼を低下させている。 また、社会的な側面では、誤情報や情報の操作が大きな脅威となっている。…
核心:何を提案したのか
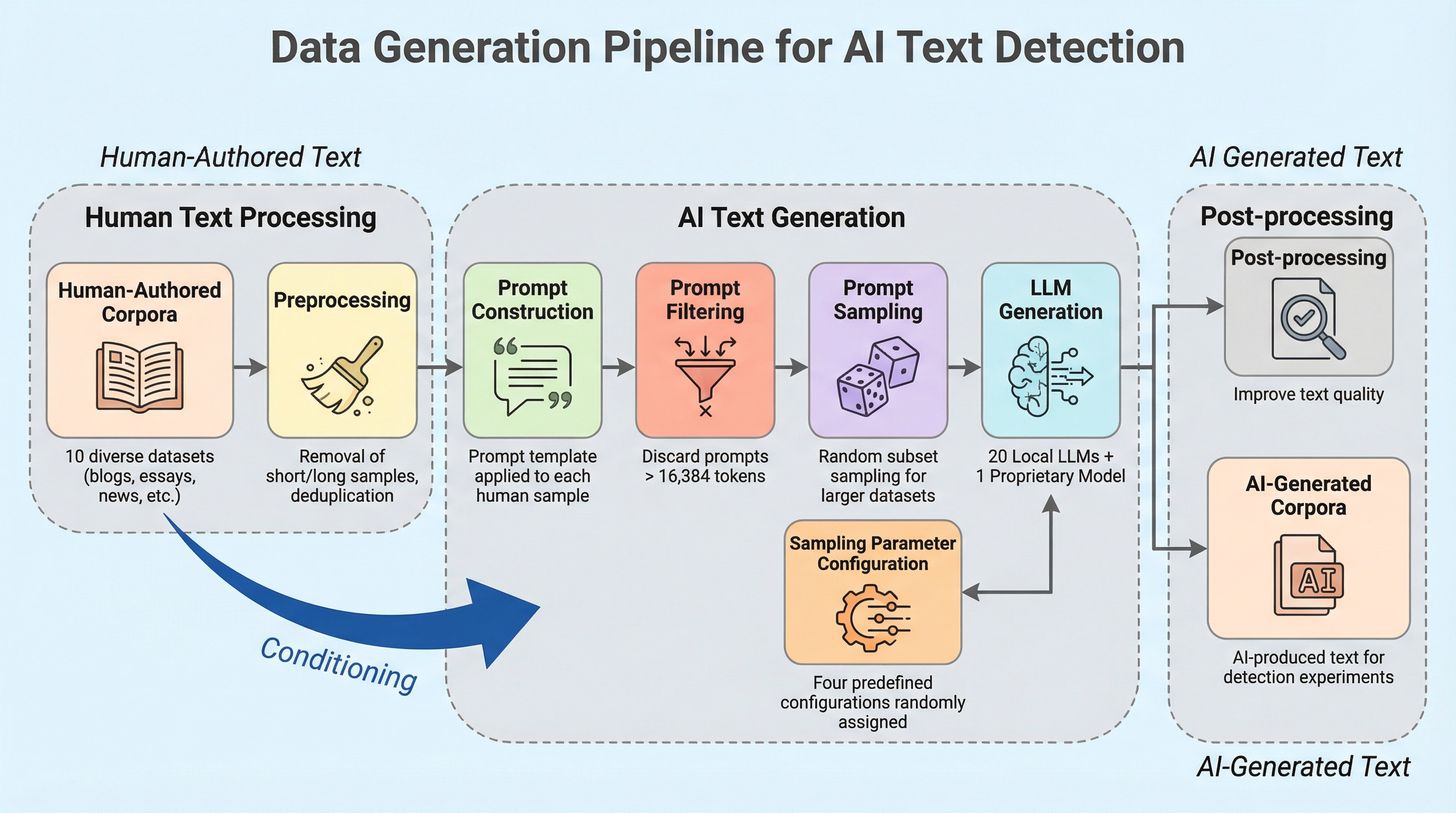
本研究の核心は、AI生成テキスト検出のための包括的な実験フレームワークと、大規模なコーパス、そして新しい学習戦略の提案にある。まず、ブログ、エッセイ、ニュース記事、オンライン上の議論、クリエイティブな執筆など、多岐にわたるジャンルを網羅した10億トークンの人間による著作物コーパスを収集した。これに対応する形で、21種類の異なる大規模言語モデルを用いて、多様なドメインにわたる19億トークンのAI生成テキストコーパスを構築するためのスケーラブルなフレームワークを開発した。使用されたモデルには、MetaのLlama-3.1やLlama-3.2、MicrosoftのPhi-3やPhi-4シリーズ、Mistral AIのMinistralやMistral-Nemo、Alibaba CloudのQwen2およびQwen2.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related