岩石―流体相互作用のサロゲートモデル:グリッドサイズ不変アプローチ
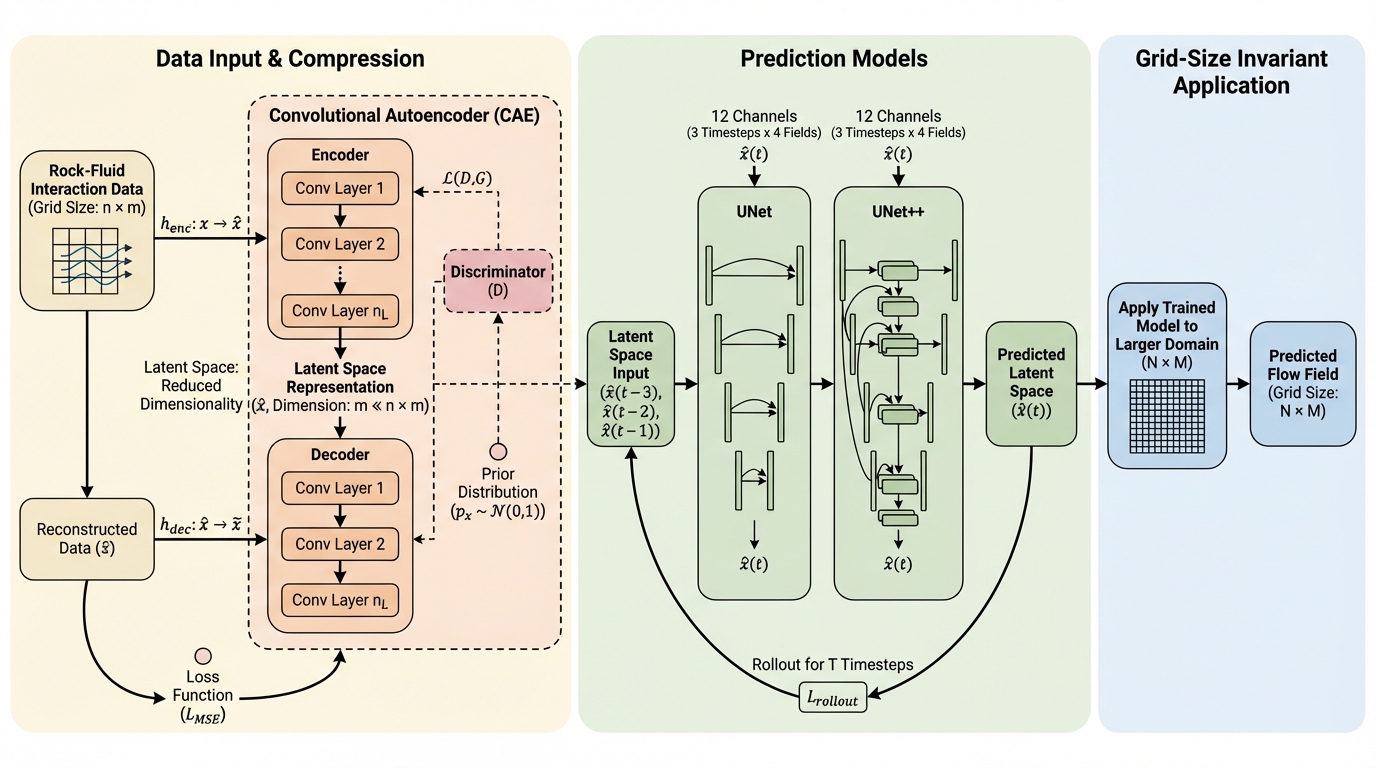
岩石―流体相互作用を含む多孔質媒体の流動予測は高解像度の数値計算ほど計算負荷が重くなりやすいため、学習ベースのサロゲートで「多数の条件を何度も回す」用途に適した代替手段を整理して示しています。 / 圧縮と予測を分ける縮約モデルと、学習時より大きい計算領域にも推論できるグリッドサイズ不変の単一ネットワークという二系統で計8モデルを構築し、UNetとUNet++、敵対的学習、rollout training、境界条件の罰則化などの設計差を比較しています。 / UNet++がUNetよりサロゲートとして良い予測性能を示し、学習メモリを抑えやすいグリッドサイズ不変アプローチが予測と真値の相関の良さにつながり、検討した縮約モデルより良い結果を示したと報告されています。