SumTablets:シュメール語粘土板の楔形文字と翻字を対応づけたデータセット
SumTabletsは、シュメール語粘土板の楔形文字をUnicode字形列として表したものと、Oraccで公開されている対応翻字を大規模に対にしたデータセットで、翻字を現代的な自然言語処理の課題として扱うための「入力(字形)―出力(翻字)」の基盤を用意しています。
TL;DR(結論)
- SumTabletsは、シュメール語粘土板の楔形文字をUnicode字形列として表したものと、Oraccで公開されている対応翻字を大規模に対にしたデータセットで、翻字を現代的な自然言語処理の課題として扱うための「入力(字形)―出力(翻字)」の基盤を用意しています。
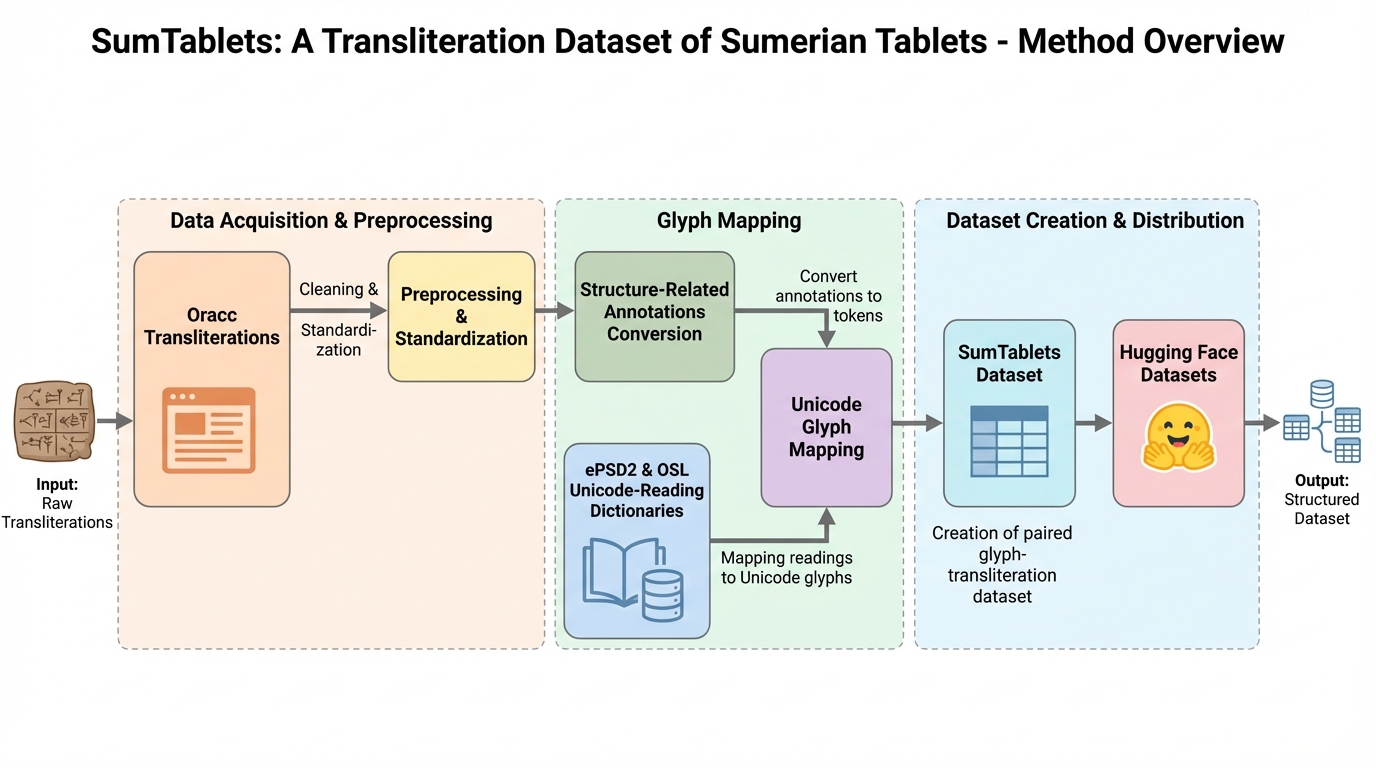
- Oracc由来の翻字を前処理で標準化し、欠損や版面上の区切りなどは特殊トークンとして両側に並行保持したうえで、ePSD2とOSLの辞書を使って各読みを元の字形へ写像し、91,606点・総字形数6,970,407の対データとして整備しています。
- 公開データを用いて辞書サンプリングと自己回帰型言語モデルの微調整という2つのベースラインを評価し、chrFで辞書が61.22、微調整モデルが97.54と報告しており、専門家が一枚ずつ手作業で翻字する代わりに生成結果を素早く確認する用途の可能性を示しています。
なぜこの問題か
シュメール語の翻字は、粘土板上の楔形文字に対する研究者の解釈を、ラテン文字を中心とする表記で書き下すための慣習的な仕組みです。ETCSL、CDLI、Oraccといったデジタル・アッシリア学の取り組みにより、多数の翻字がオンラインで公開され、検索や分析に向く形で整理されてきました。一方で、翻字と「タブレット上の字形そのもの」を機械可読な形で対にした、包括的で扱いやすいデータが不足していたため、翻字生成に現代的な自然言語処理手法を適用しにくい状況が続いていました。背景として、研究者は実物や画像を見て読みを決めるのが一般的であり、作業の成果物としてデジタル字形列を併記する運用が通常は残りにくい点が挙げられています。楔形文字は文脈により複数の読みを取り得る多価性があり、本文では例として、𒅗が「ka」「dug4」「kiri3」「zuh」や音節「ka」などに読まれ得ることが示されています。翻字側も、同音異義の区別に下付き数字を使ったり、語幹と接辞をハイフンで連結したりするなど、近代以降に整えられた表記慣習に依存します。…
核心:何を提案したのか
提案の中心は、Unicodeで表したシュメール語楔形文字タブレットの字形列と、Oraccで公開されている対応翻字を、同じタブレット単位で結び付けたデータセットSumTabletsの提示です。規模は91,606点のタブレットで、総字形数は6,970,407とされています。重要なのは、単に字形と翻字を並べるだけでなく、版面上の構造情報を失いにくい表現に揃えている点です。具体的には、面の開始、改行、欠損区間、区切り線、段(カラム)、空白といった情報を特殊トークンとして導入し、字形側と翻字側の対応する位置に並行して残す方針を取っています。これにより、モデルが字形と読みの対応だけではなく、「どこで行が切れるか」「欠損がどこにあるか」といった配置の手掛かりも入力として受け取れる形になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related