翻訳で取り戻す:ベンチマークとデータセットの自動翻訳に向けた効率的パイプライン
多言語の大規模言語モデルを公平に評価するには、翻訳済みベンチマークの品質ばらつきによる意味のずれや文脈欠落を減らし、指標が誤解を招かない状態に整える必要があります。 / データセット向けとベンチマーク向けを切り分けた完全自動の翻訳フレームワークを用い、テスト時の計算量スケーリング戦略としてUSIと多ラウンド順位付けのT-RANK、さらにSCやBest-of-Nも選べる形で翻訳工程を構成します。 / 東欧・南欧の8言語に人気ベンチマーク/データセットを翻訳して参照ベース指標とLLM-as-a-judgeで検証したところ、既存資源を上回る翻訳が得られ、下流のモデル評価をより正確にし得ることと、枠組みと改善版ベンチマークを公開する点が示されています。
TL;DR(結論)
- 多言語の大規模言語モデルを公平に評価するには、翻訳済みベンチマークの品質ばらつきによる意味のずれや文脈欠落を減らし、指標が誤解を招かない状態に整える必要があります。
- データセット向けとベンチマーク向けを切り分けた完全自動の翻訳フレームワークを用い、テスト時の計算量スケーリング戦略としてUSIと多ラウンド順位付けのT-RANK、さらにSCやBest-of-Nも選べる形で翻訳工程を構成します。
- 東欧・南欧の8言語に人気ベンチマーク/データセットを翻訳して参照ベース指標とLLM-as-a-judgeで検証したところ、既存資源を上回る翻訳が得られ、下流のモデル評価をより正確にし得ることと、枠組みと改善版ベンチマークを公開する点が示されています。
なぜこの問題か
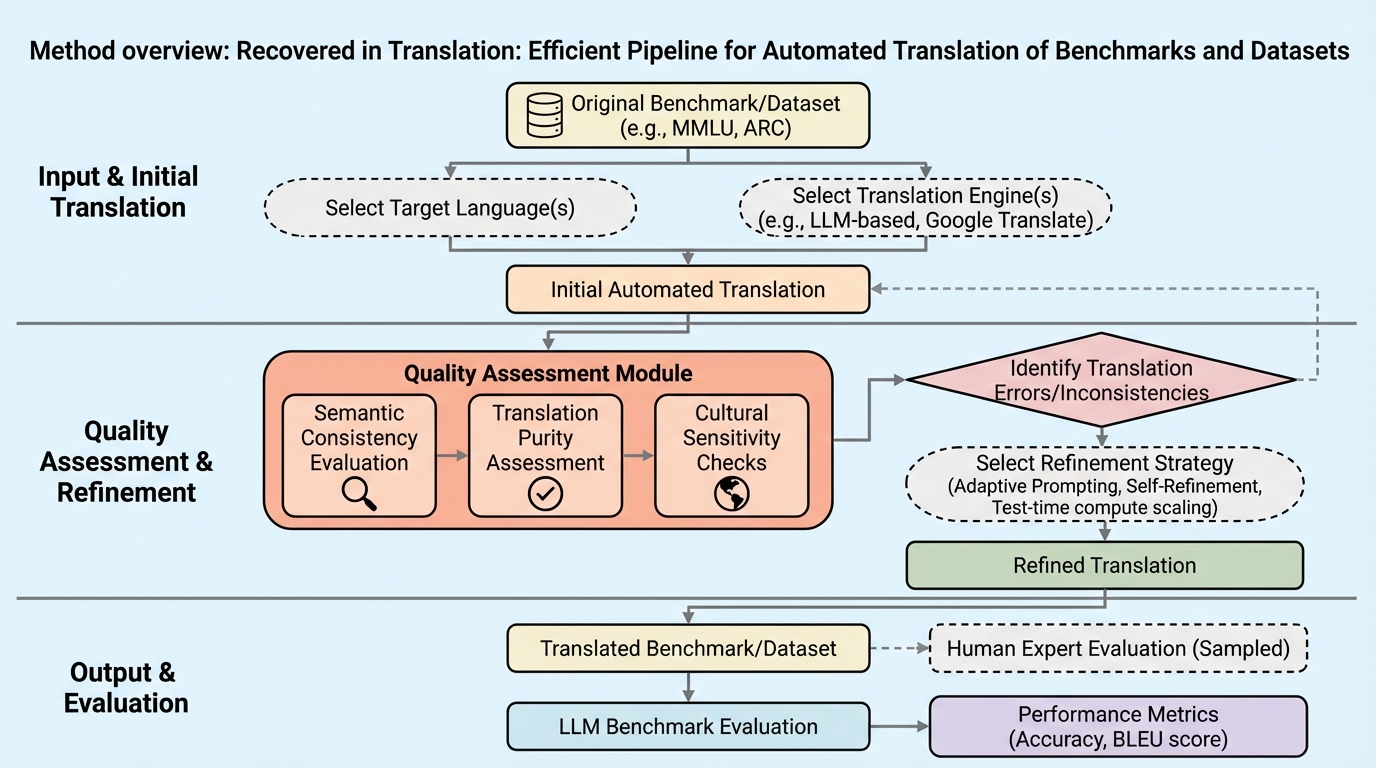
多言語LLMの評価は、英語以外の言語で十分な量のデータやベンチマークが揃いにくい状況を背景に、既存ベンチマークを翻訳して利用する場面が増えています。ところが翻訳済みベンチマークの品質が一貫しないと、原文の意図から意味がずれたり、必要な文脈が落ちたりして、評価指標そのものが誤解を招く可能性があります。著者らはこの点を「多言語評価の信頼性が損なわれている状態」として捉え、翻訳を単なる前処理ではなく、評価の妥当性を左右する工程として扱う必要があると述べています。 既存資源の課題として特に重要なのが、質問文と回答選択肢を別々に翻訳してしまい、文脈や文法の整合が崩れる問題です。文の補完型タスクなどでは、質問と選択肢の関係が翻訳で崩れると、タスク構造自体が変質してしまい、モデルが「推論できたのか」「言語運用で偶然当たったのか」の切り分けが難しくなります。加えて、古典的な機械翻訳ツールは指示に基づくプロンプティング能力を持たないことが多く、また一部の既存ベンチマークは古いLLMに依存して翻訳されているため、最新のフロンティアモデルが持つ多言語能力を十分に活かせていない懸念も挙げられています。…
核心:何を提案したのか
著者らが提案するのは、データセットとベンチマークを対象に、スケール可能で高品質な翻訳を実現する完全自動フレームワークです。目的は、翻訳後も元のタスク構造と言語的ニュアンスを保ったままローカライズし、多言語評価が翻訳品質に引きずられて不安定になる問題を抑えることです。抽象(要旨)では、テスト時の計算量スケーリング戦略を翻訳に適用し、従来の翻訳パイプラインに比べて品質が大きく向上することを示す、とまとめられています。中核となる具体策が、Universal Self-Improvement(USI)と、著者らが新たに提案する多ラウンドのランキング法T-RANKです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related