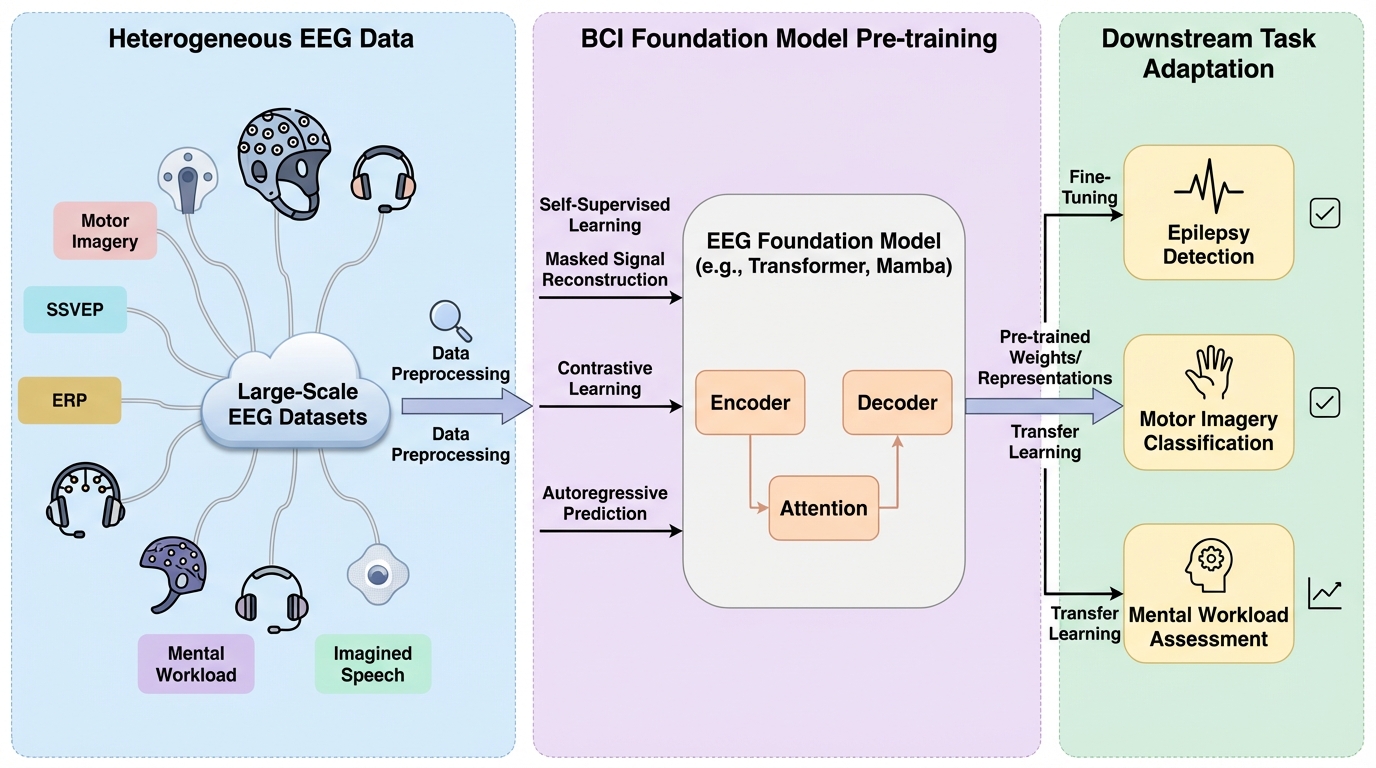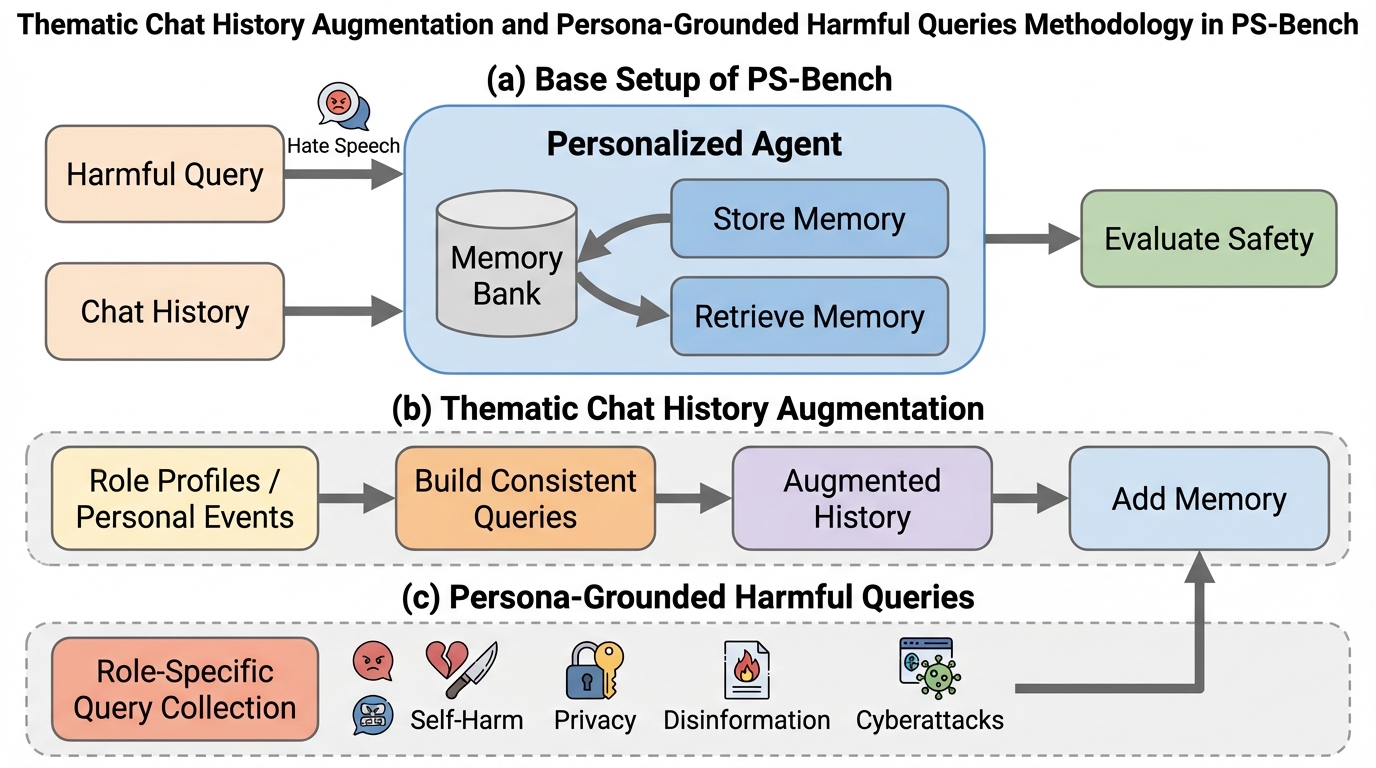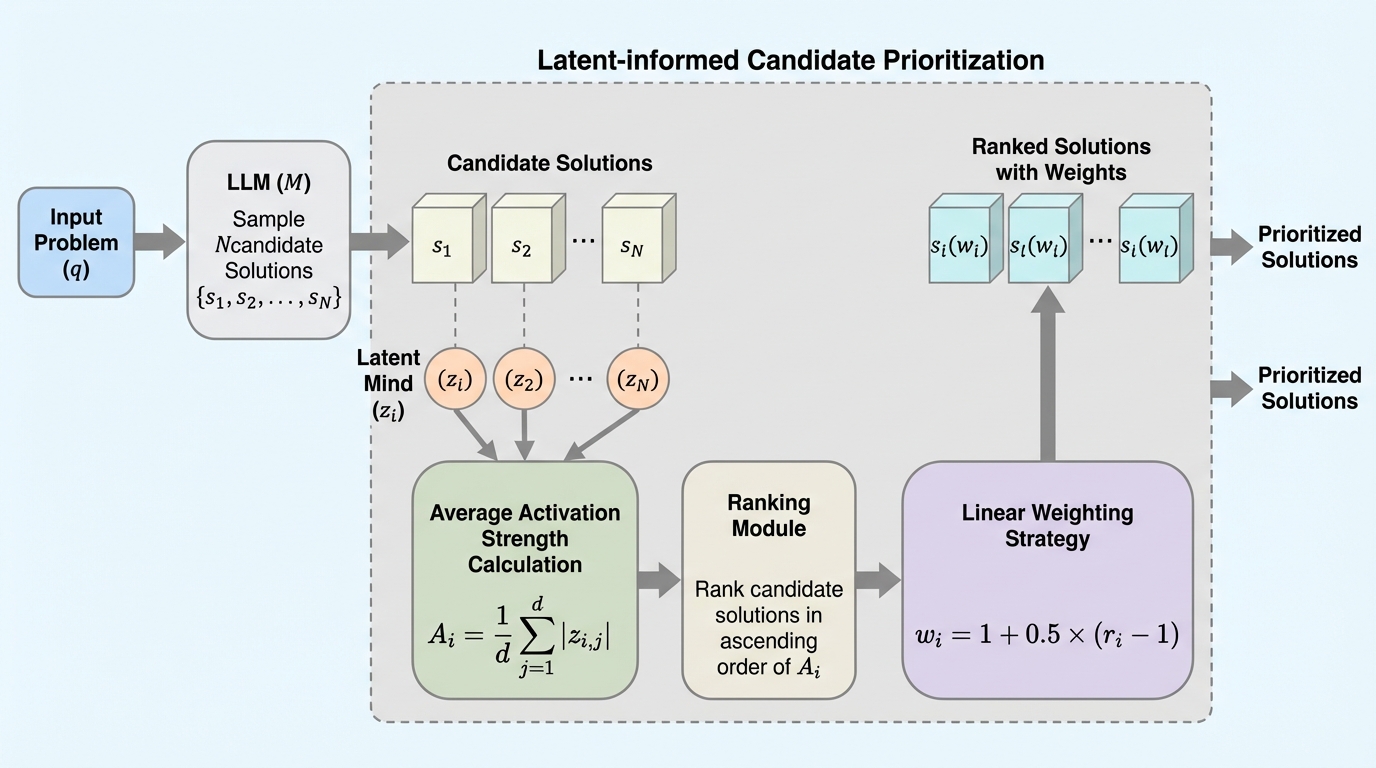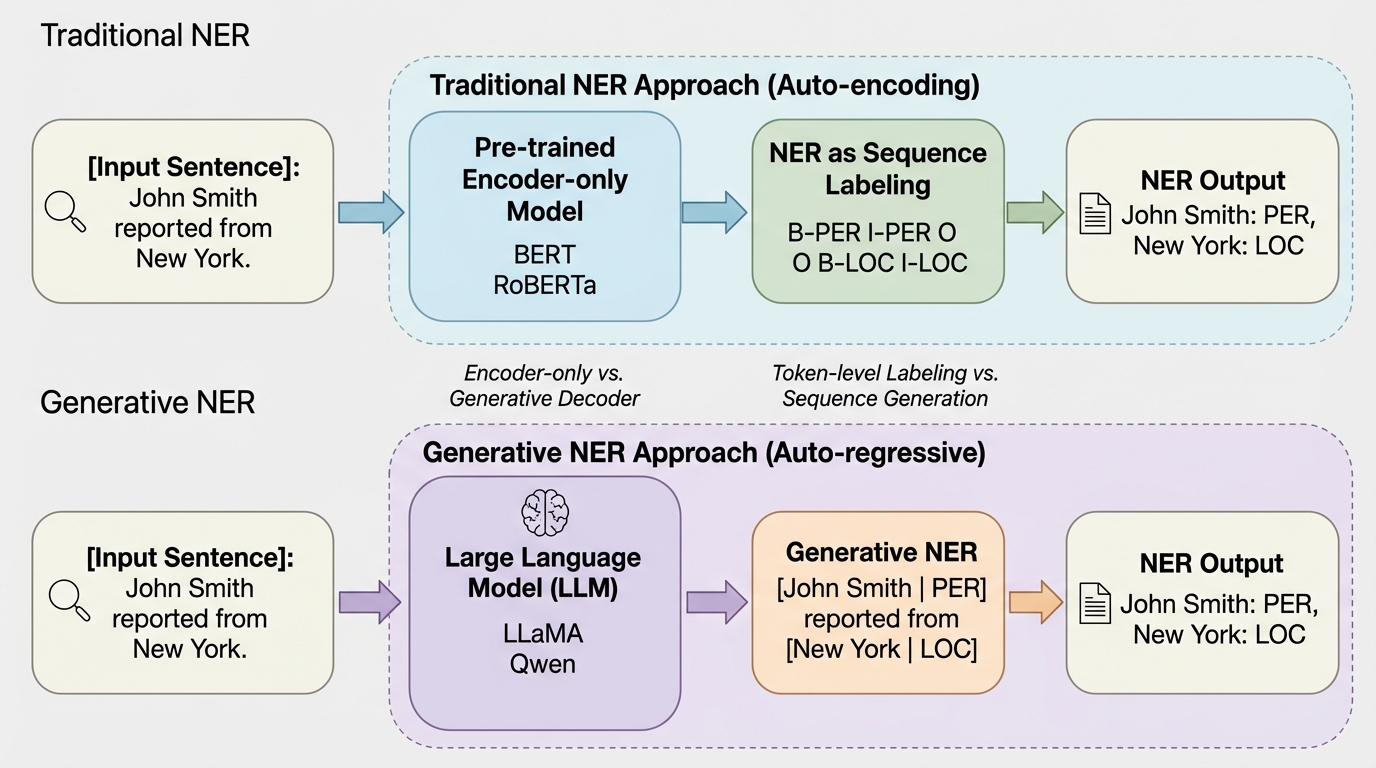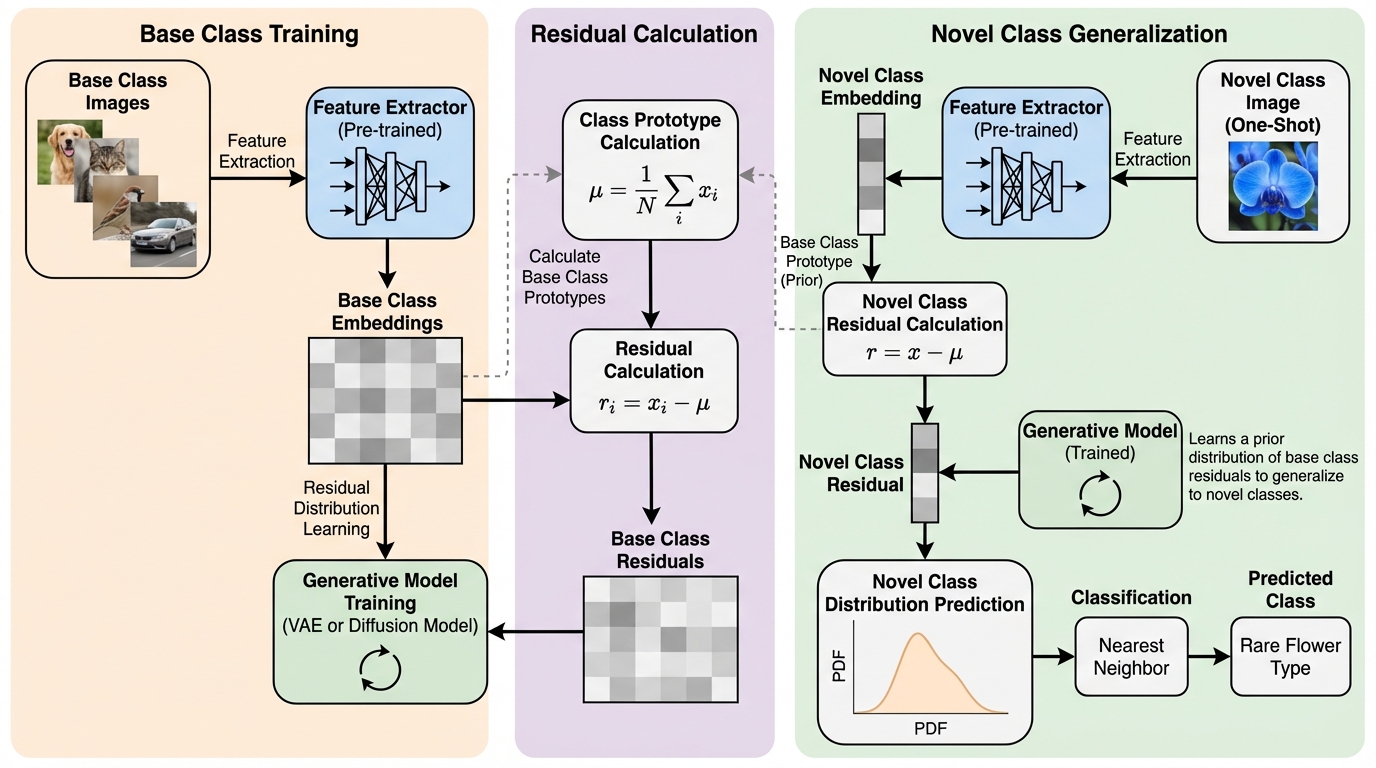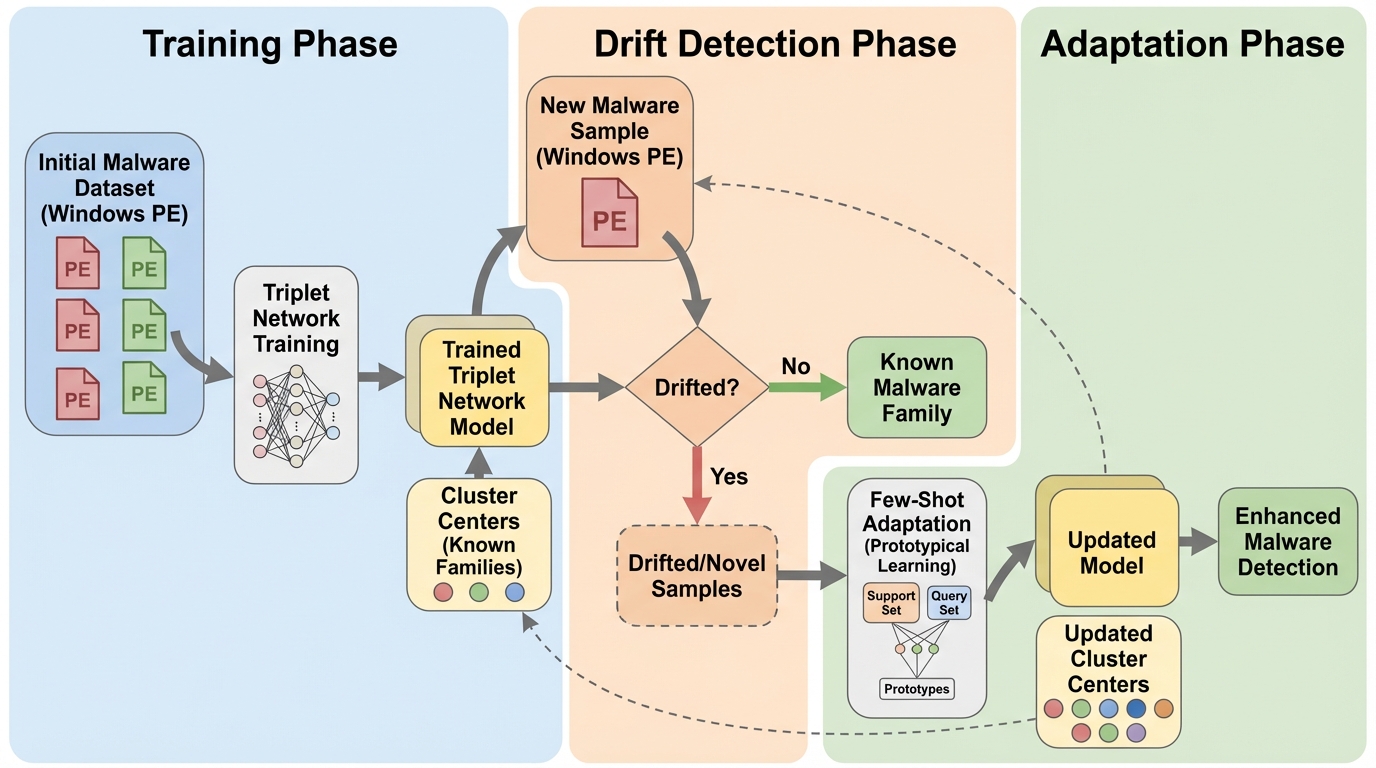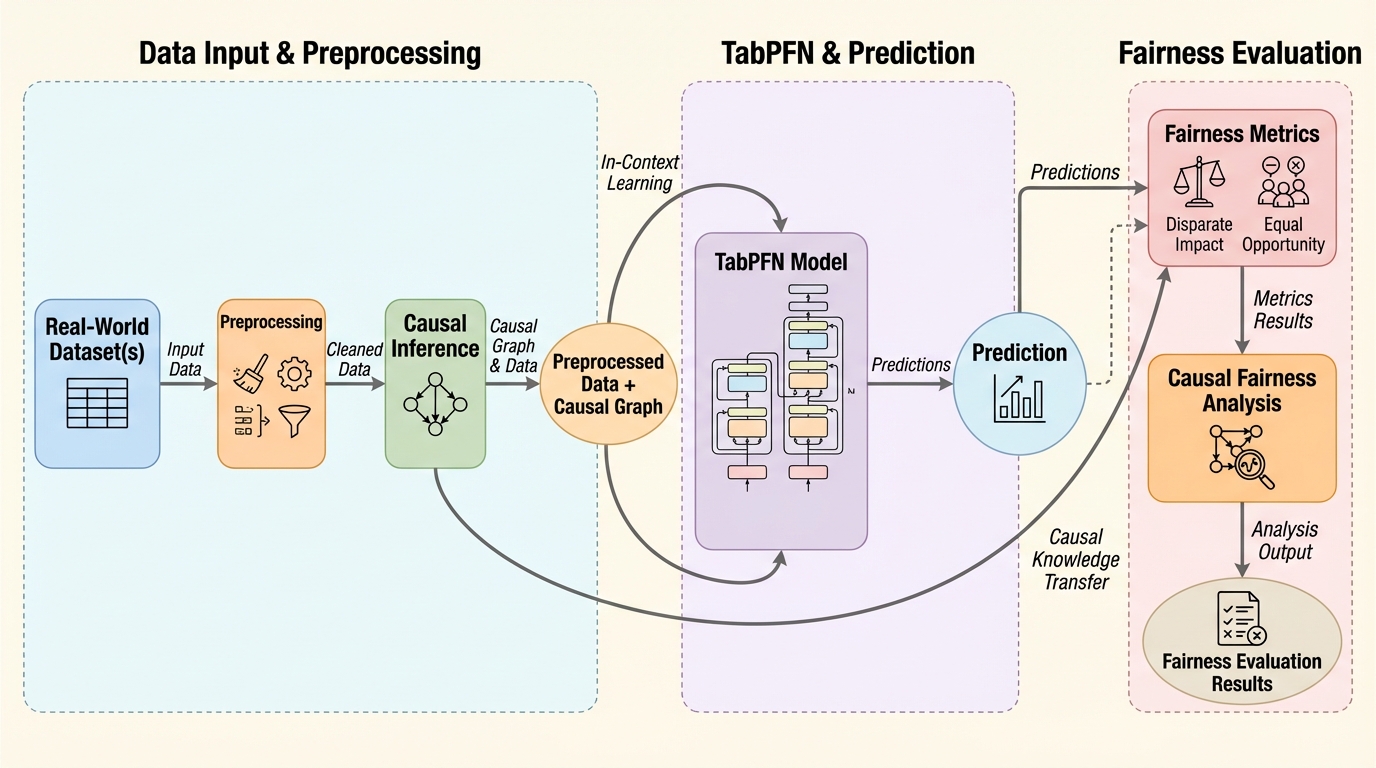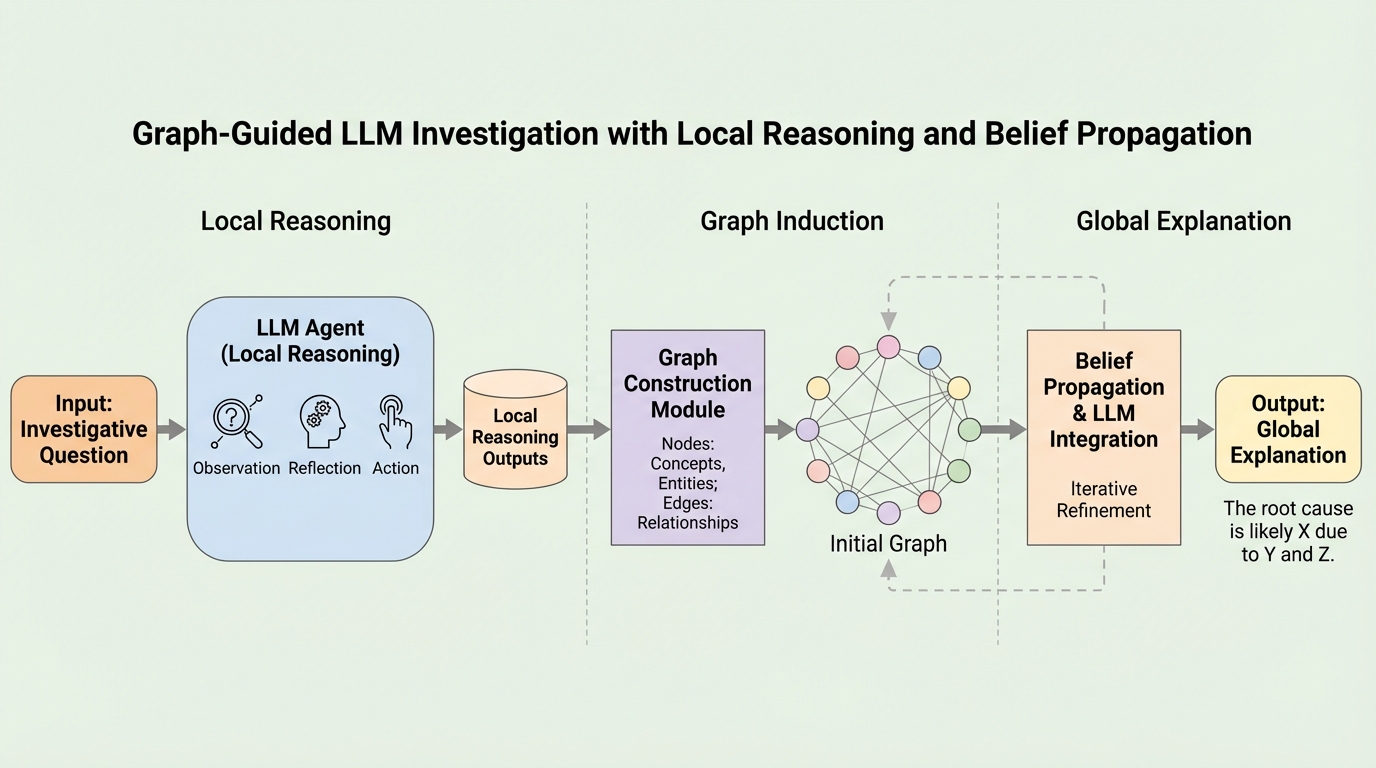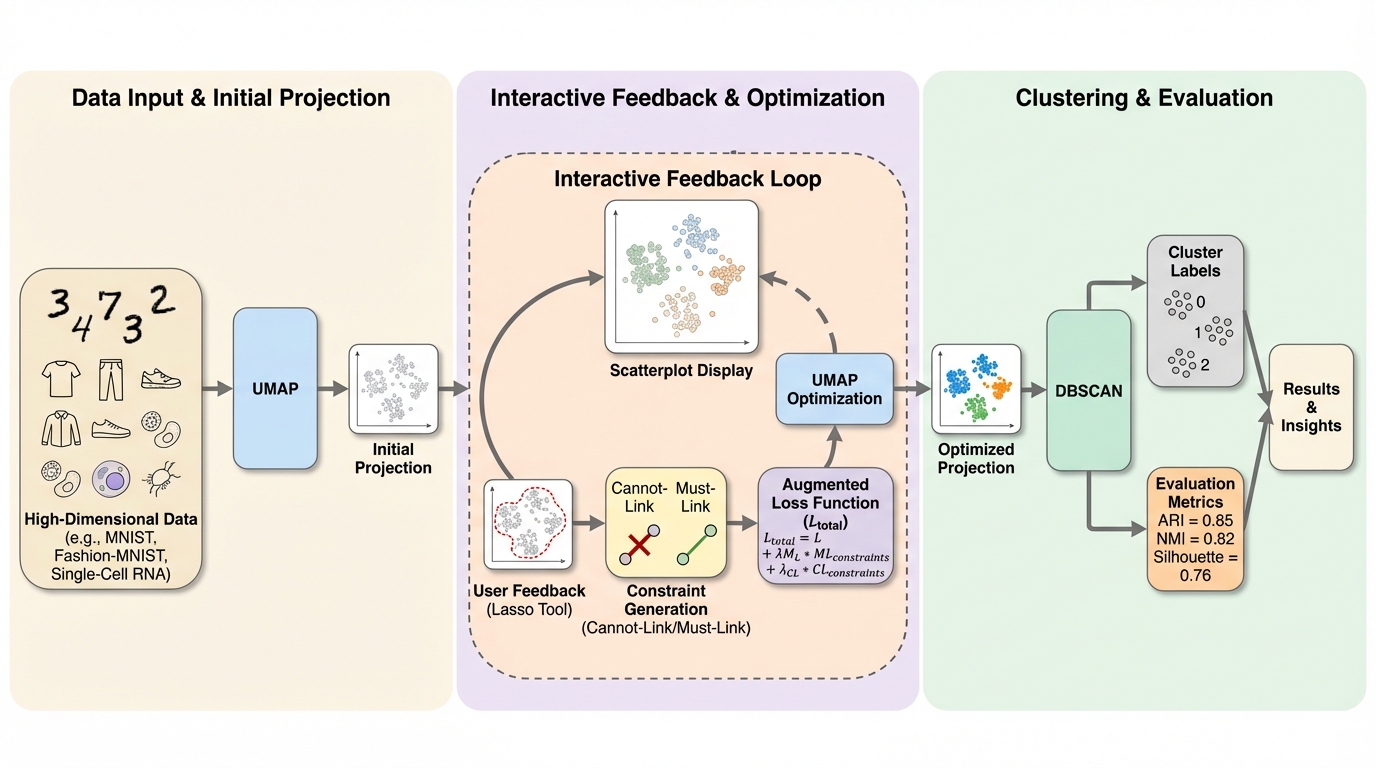
IPBC:高次元データのヒューマンインザループ半教師ありクラスタリングのための対話型投影ベースのフレームワーク
現代の科学や産業分野で急増している高次元データは、距離尺度が意味をなさなくなる「次元の呪い」により、従来の自動クラスタリング手法では正確な分類が困難であるという深刻な課題を抱えています。 本研究が提案するIPBC(Interactive Projection-Based Clustering)は、非線形投影手法であるUMAPに人間によるフィードバックループを統合し、ユーザーが「must-link」や「cannot-link」といった制約を直接投影モデルに与えることで、データの構造を動的に洗練させる革新的なフレームワークです。 MNISTや単一細胞RNA解析データを用いた検証の結果、わずか数回の対話的な修正ステップでクラスタリングの質(ARIやNMI)が大幅に向上し、さらに決定木を用いた説明可能性コンポーネントによって、各クラスタを特徴づける元の変数を特定できることが示されました。