大規模言語モデル時代における生成的固有表現認識の評価
本研究は、LLaMAやQwenといった8つのオープンソース大規模言語モデル(LLM)を用い、生成的固有表現認識(NER)の性能を4つの標準データセットで系統的に評価しました。 検証の結果、LoRAによる効率的な微調整と、文章内に直接ラベルを埋め込む「Inline Bracketed」や「XML」形式を組み合わせることで、オープンソースLLMは従来のBERT系専門モデルに匹敵し、GPT-3などの巨大なクローズドモデルを上回る性能を達成できることが明らかになりました。 また、LLMのNER能力は単なるエンティティの記憶ではなく指示に従う生成能力に由来しており、特定のNERタスクに特化した微調整を行ってもモデルの汎用的な知識や推論能力は損なわれず、むしろ読解タスクなどで性能が向上する場合があることも確認されました。
TL;DR(結論)
本研究は、LLaMAやQwenといった8つのオープンソース大規模言語モデル(LLM)を用い、生成的固有表現認識(NER)の性能を4つの標準データセットで系統的に評価しました。 検証の結果、LoRAによる効率的な微調整と、文章内に直接ラベルを埋め込む「Inline Bracketed」や「XML」形式を組み合わせることで、オープンソースLLMは従来のBERT系専門モデルに匹敵し、GPT-3などの巨大なクローズドモデルを上回る性能を達成できることが明らかになりました。 また、LLMのNER能力は単なるエンティティの記憶ではなく指示に従う生成能力に由来しており、特定のNERタスクに特化した微調整を行ってもモデルの汎用的な知識や推論能力は損なわれず、むしろ読解タスクなどで性能が向上する場合があることも確認されました。
なぜこの問題か
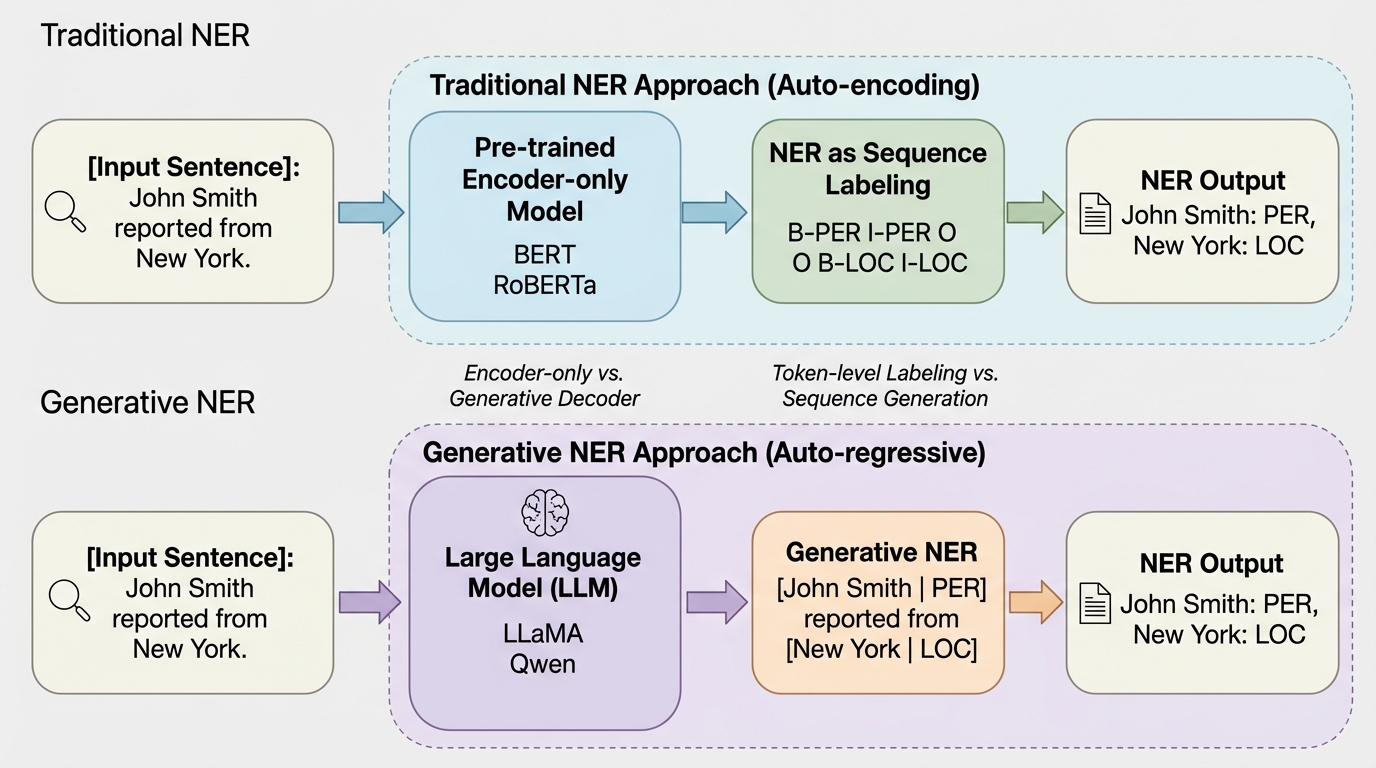
固有表現認識(NER)は、自然言語処理における極めて重要な基礎タスクであり、関係抽出、知識グラフの構築、情報検索、質問応答システムといった幅広い下流アプリケーションの基盤となっています。従来、このタスクはテキスト内の各単語にラベルを割り当てる「シーケンスラベリング」として扱われ、BERTに代表される自己符号化型の事前学習モデルが主流となってきました。しかし、大規模言語モデル(LLM)の台頭により、NERのパラダイムはテキストを逐次的に生成する「生成的アプローチ」へと大きく移行しつつあります。この移行期において、研究コミュニティにはいくつかの重要な疑問が浮上していました。 第一に、ChatGPTのようなクローズドソースのモデルを用いたゼロショット性能の研究は進んでいますが、LLaMAやQwenといった最新のオープンソースLLMを特定のデータセットで微調整した場合、従来の専門的なNERモデルと比較してどの程度信頼できる性能を発揮するのかという点です。特に、単純な形式の「フラットNER」だけでなく、エンティティが重なり合う「ネストNER」において、どの程度の性能差があるのかは十分に解明されていませんでした。…
核心:何を提案したのか
本研究では、オープンソースLLMを用いた生成的NERの能力を多角的に測定するための、包括的な評価フレームワークを提案しました。具体的には、モデルの規模やバージョンが異なる8つのLLMを選定しました。これには、LLaMA3.1-8B、LLaMA3.2-3Bおよび1B、Qwen2.5-7B、3B、1.5B、そしてQwen3-4B、1.7Bが含まれます。これらのモデルに対して、パラメータ効率の良い微調整手法であるLoRA(Low-Rank Adaptation)を適用し、NERタスクへの最適化を行いました。 評価の対象としたのは、ドメインや構造が異なる4つの標準的なデータセットです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related