DIETA:イタリア語-英語機械翻訳のためのデコーダのみを用いたTransformerベースモデル
DIETAは、イタリア語と英語の双方向翻訳に特化して設計された、5億パラメータという比較的小規模なデコーダ専用Transformerモデルであり、大規模な精選コーパスと逆翻訳データを活用して構築されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
DIETAは、イタリア語と英語の双方向翻訳に特化して設計された、5億パラメータという比較的小規模なデコーダ専用Transformerモデルであり、大規模な精選コーパスと逆翻訳データを活用して構築されました。
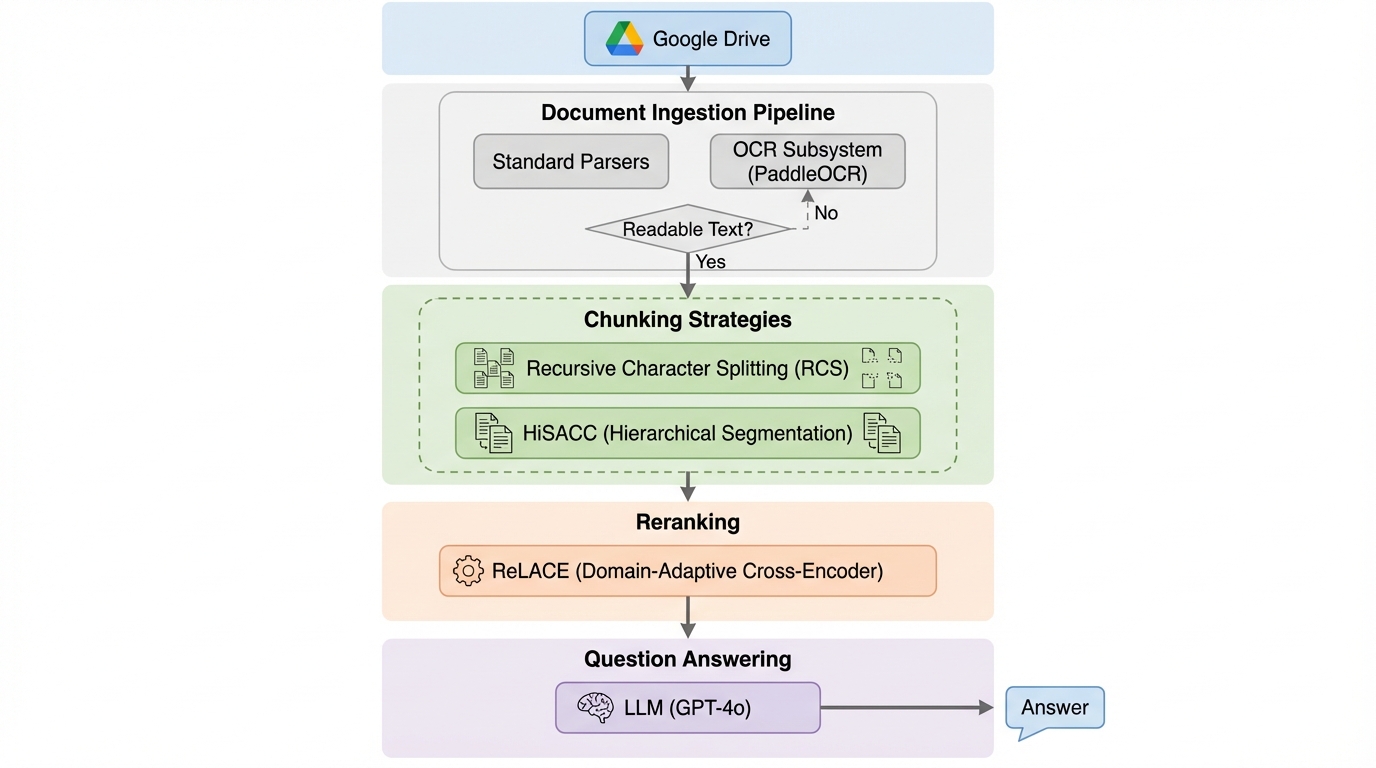
医薬品業界における規制更新の頻繁化と複雑化に伴い、手動でのコンプライアンス確認作業は多大なコストと誤りのリスクを抱えているが、本研究ではこれを自動化するAIアシスタント「RegGuard」を開発した。
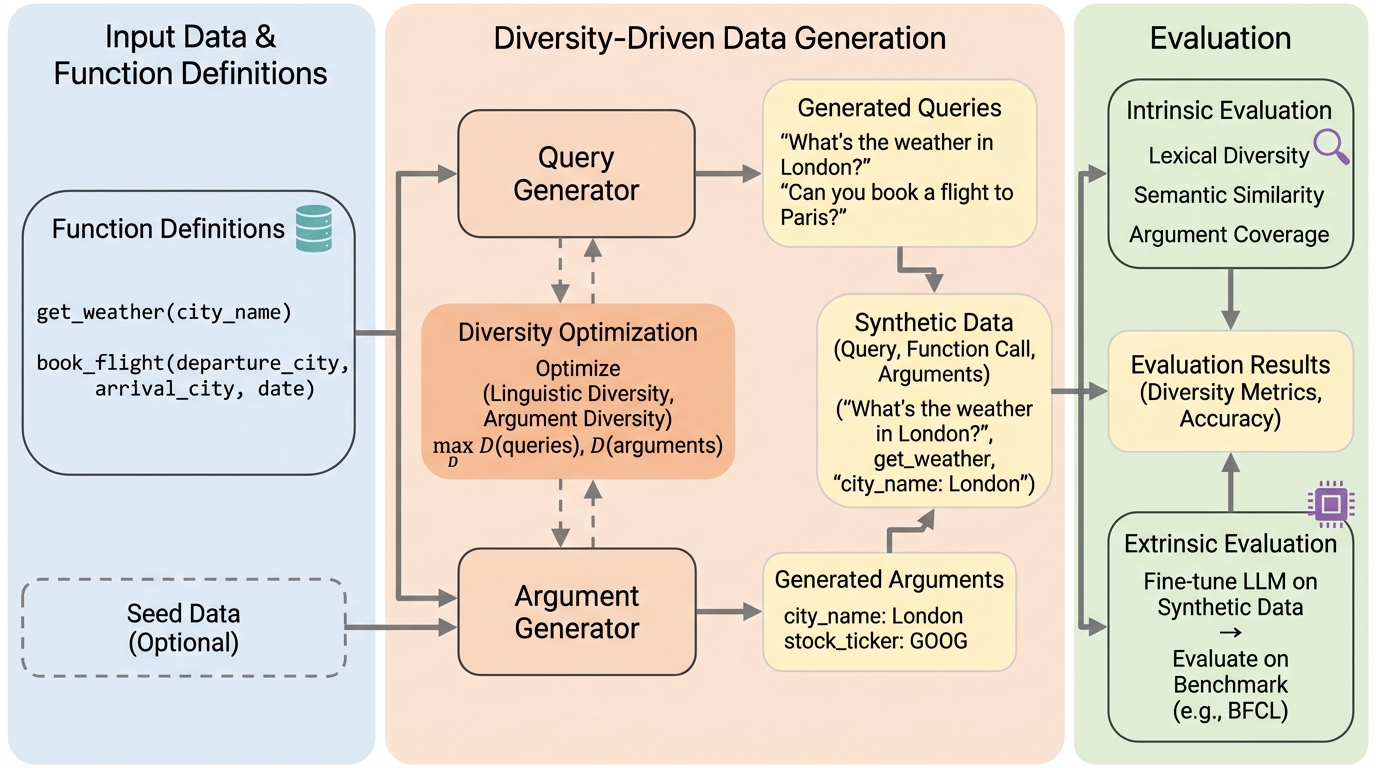
関数呼び出しエージェントの学習には多様なデータが不可欠ですが、既存手法は関数の種類や呼び出しパターンに偏り、ユーザーの言い回しの多様性(言語的多様性)や引数の値の網羅性(引数の多様性)が不足しているという課題がありました。
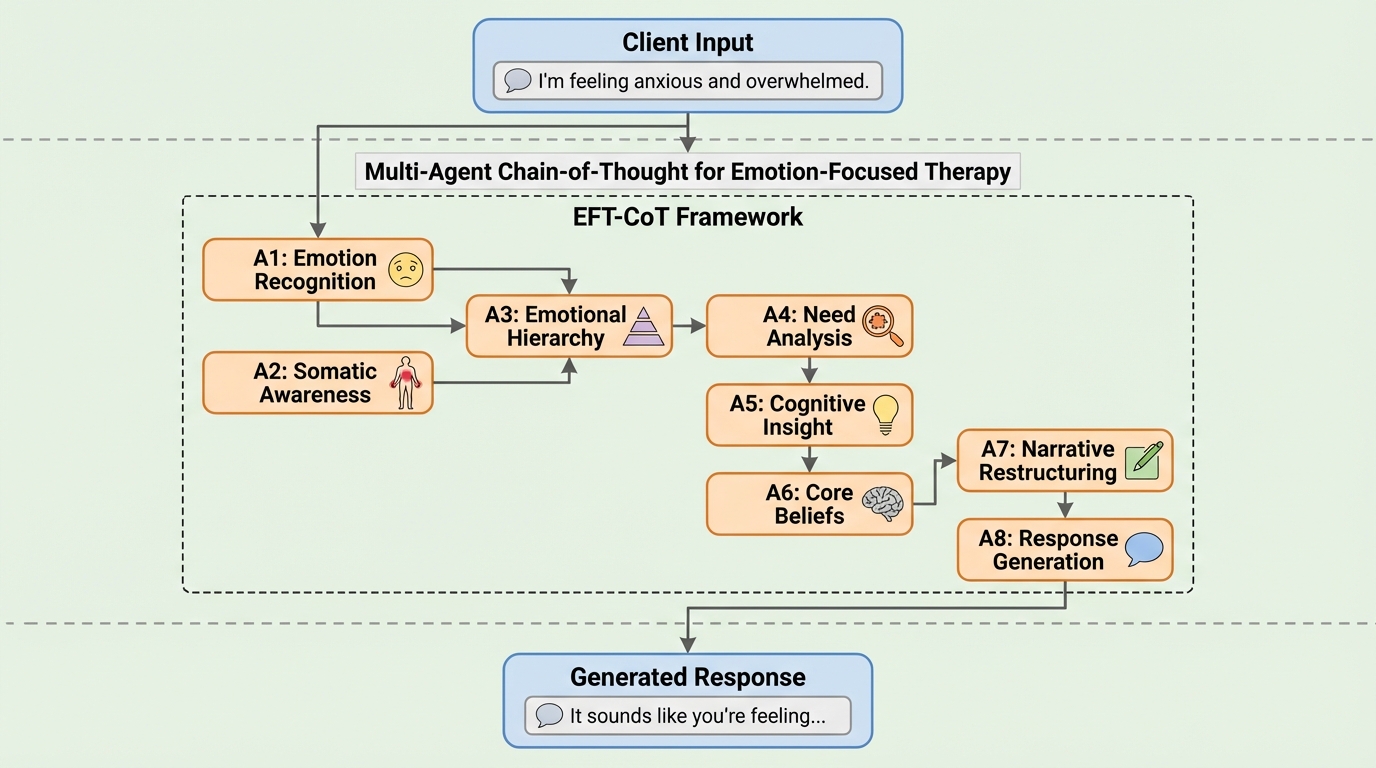
従来の認知行動療法(CBT)に基づくAI心理支援は論理的な書き換えを重視する「トップダウン」型であり、利用者の深い感情や身体的感覚への配慮が不足していたため、本研究では感情焦点化療法(EFT)の理論を取り入れた「ボトムアップ」型の新しいフレームワークであるEFT-CoTを提案した。
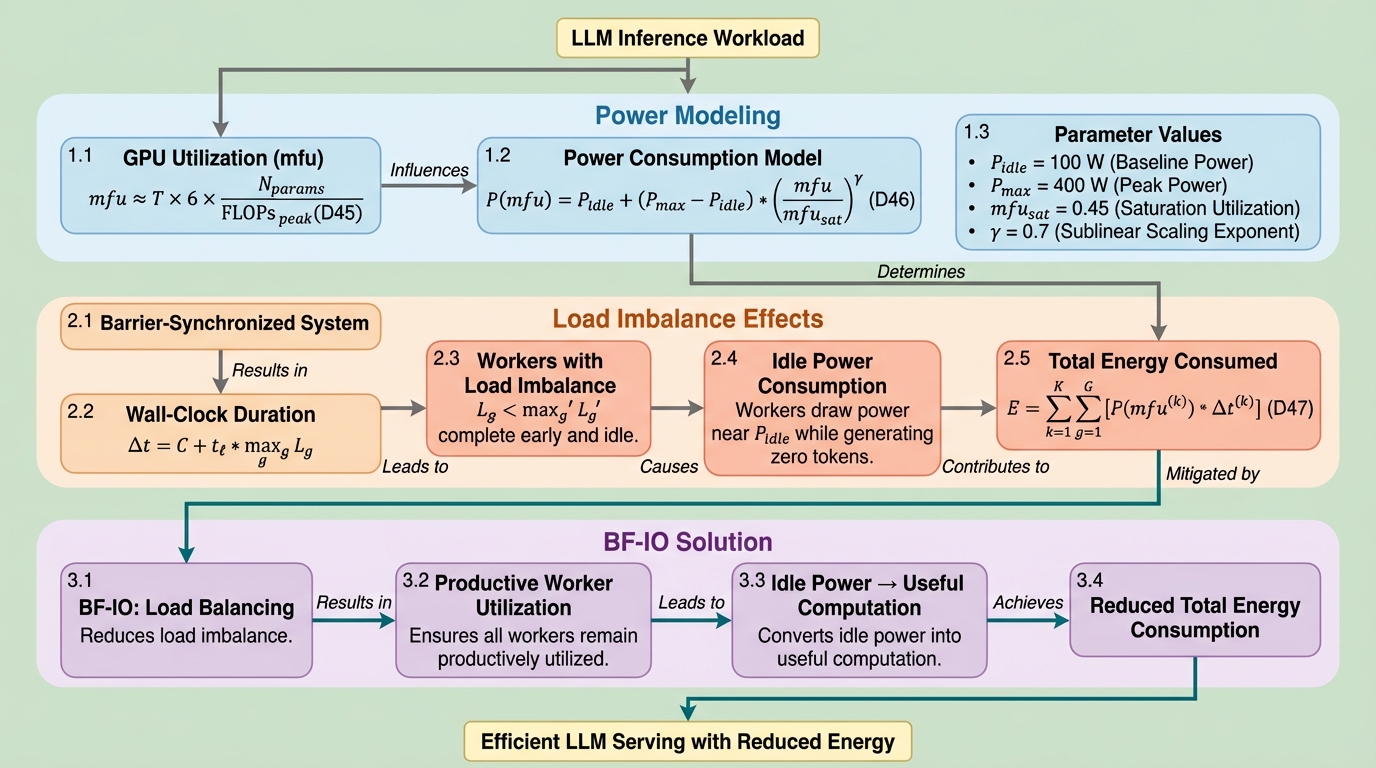
大規模言語モデル(LLM)の推論サービスにおいて、同期バリアによって生じる計算資源の不均衡が深刻なボトルネックとなっており、実際の運用データではデコード工程の40%以上の時間がアイドリング状態で浪費されていることが判明しました。
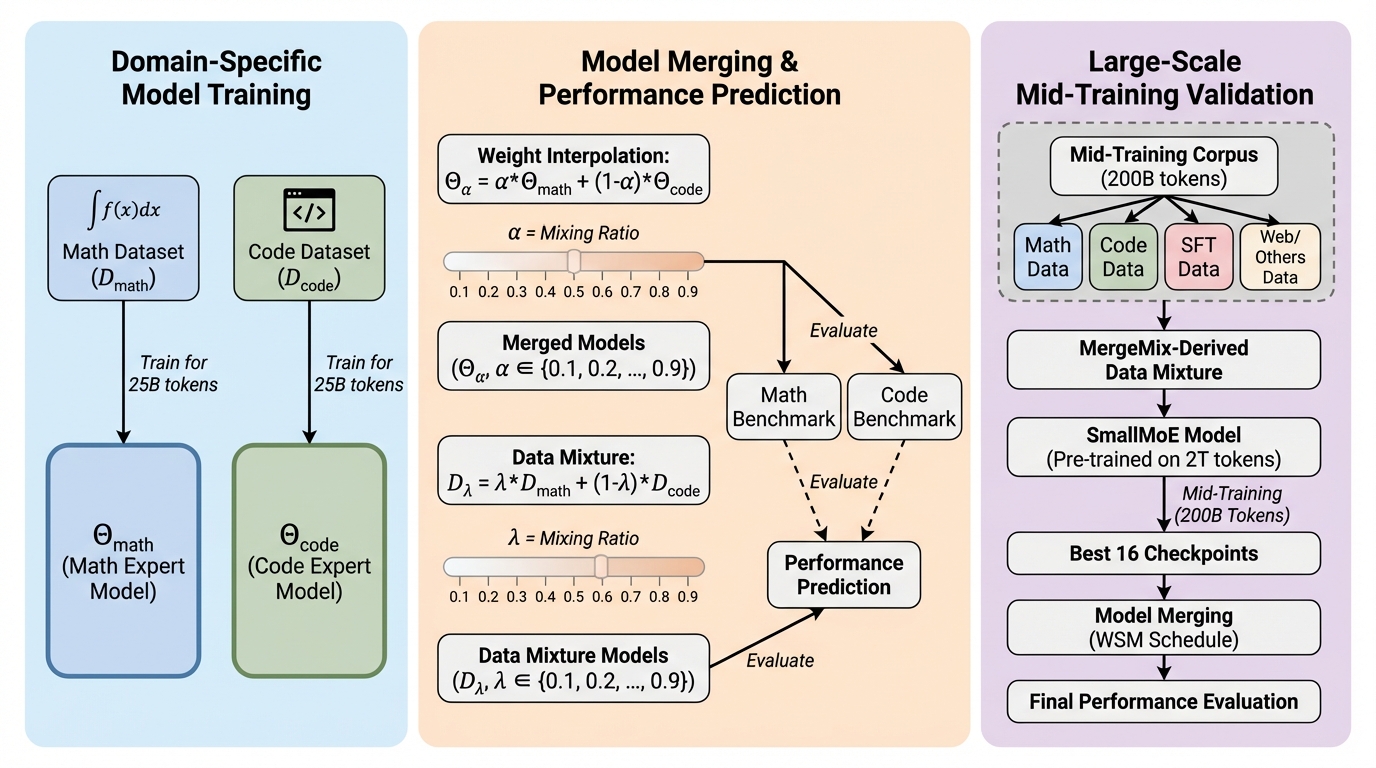
MergeMixは、大規模言語モデル(LLM)の中間学習における最適なデータ混合比を、モデルマージの重みを代理指標(プロキシ)として活用することで効率的に特定する新しい手法である。 従来のデータ混合比の最適化は、膨大な計算コストを伴う試行錯誤やスケーリング則の推定に依存していたが、本手法は少量のトークンで学習したドメイン専門家モデルを線形補間することで、実トレーニングなしに下流タスクの性能を予測する。 実験では8Bおよび16Bのモデルにおいて、手動による網羅的な調整と同等以上の性能を達成しつつ、探索コストを100倍以上削減することに成功しており、高いランク相関とスケールを跨いだ転移性も確認されている。
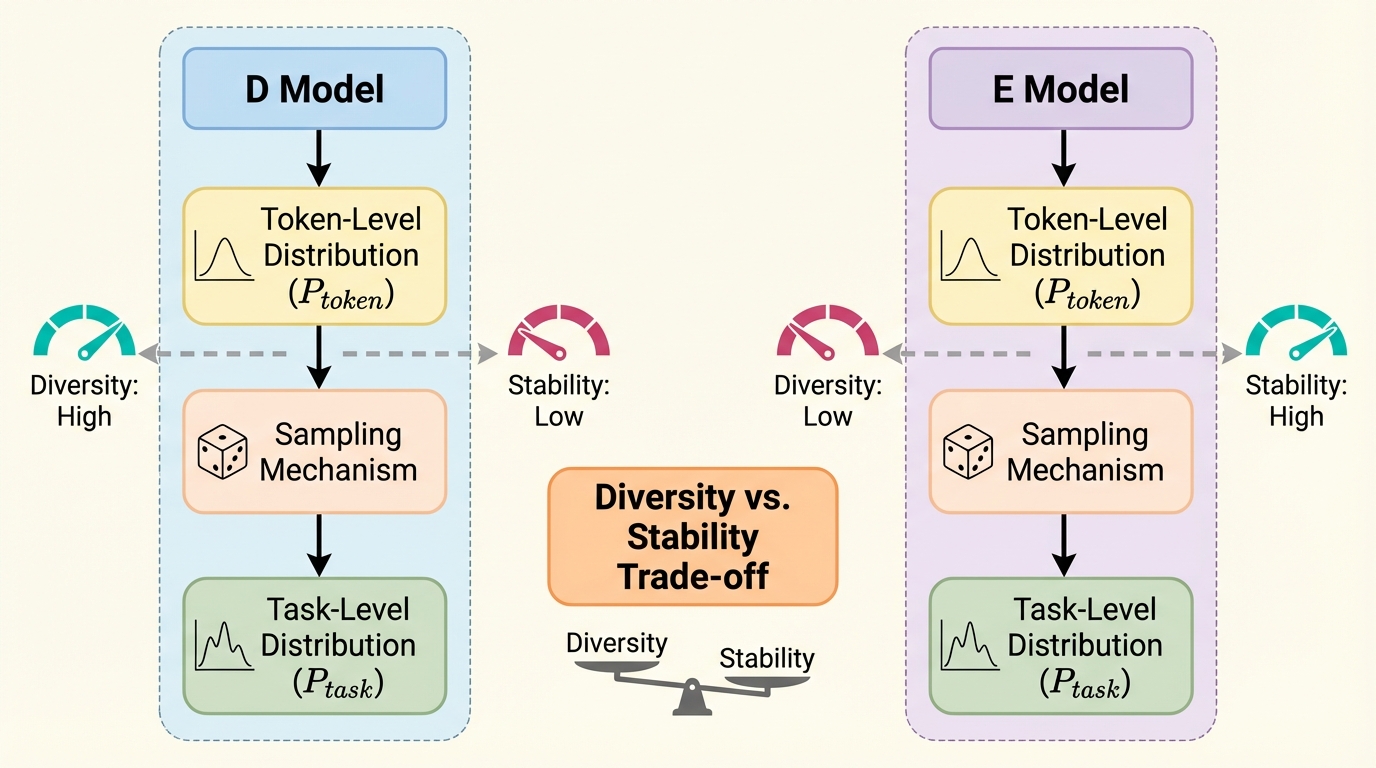
大規模言語モデル(LLM)の次トークン予測確率は、情報の関連性や商品の購入確率といったタスクレベルの目標分布($P_{task}$)と密接に関連していますが、そのサンプリング挙動には「Dモデル」と「Eモデル」という二極化された特性が存在することが明らかになりました。 Qwen-2.
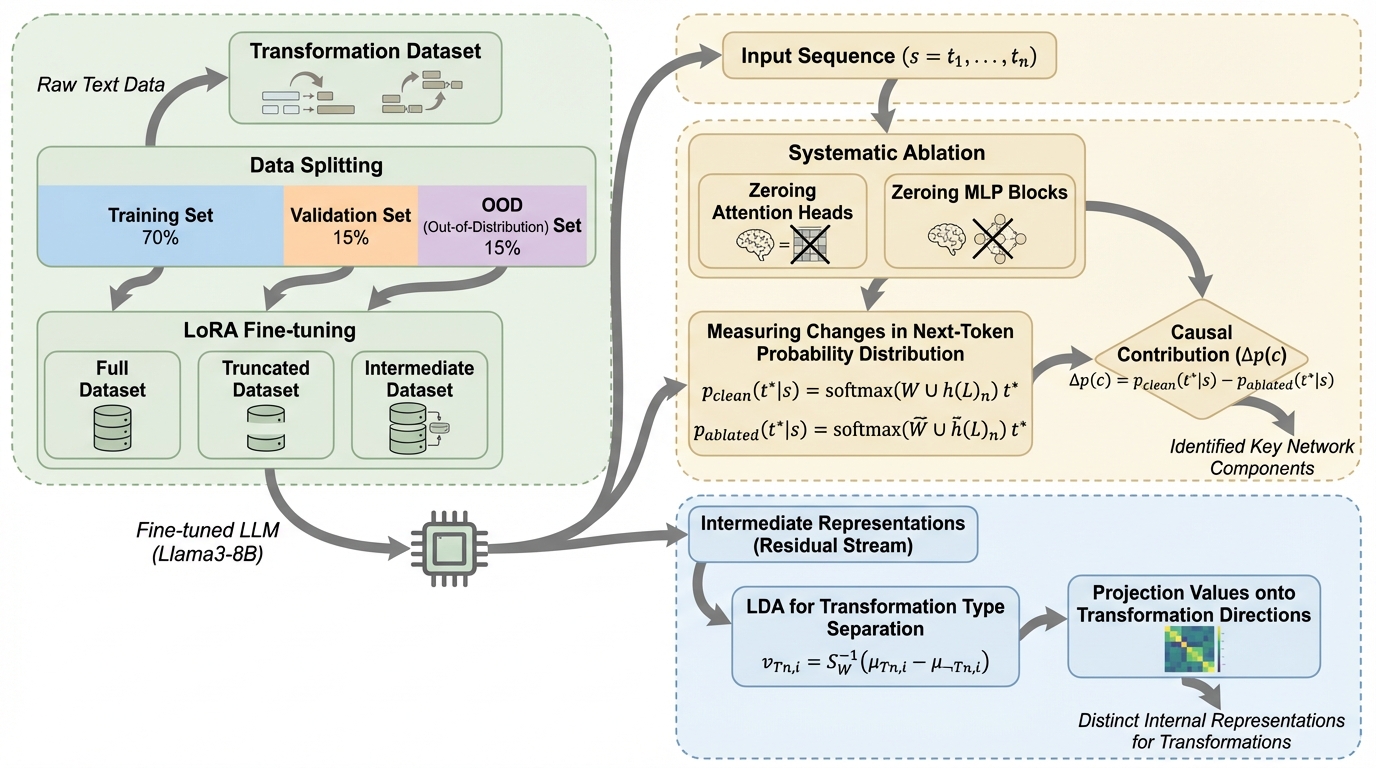
大規模言語モデルが学習データから抽象的な構造情報をどのように獲得し、それを未知の組み合わせの生成(構成的汎用化)に利用できるかを、変形文法に基づく独自の自然言語データセットを用いて検証した。 実験の結果、モデル内部で構造情報の表現が明確になる時期は、単純な次単語予測の精度向上よりも、複雑な推論タスクの性能向上と強く相関しており、学習の進展に伴い構造の区別が急激に明確化する相転移現象が確認された。 しかし、学習時に見たことのない複数の構造を組み合わせる能力は依然として限定的であり、中間的な生成ステップを明示しない限り正確な出力を得ることが困難であることから、現在の学習手法における構成的な知識生成の限界が浮き彫りになった。
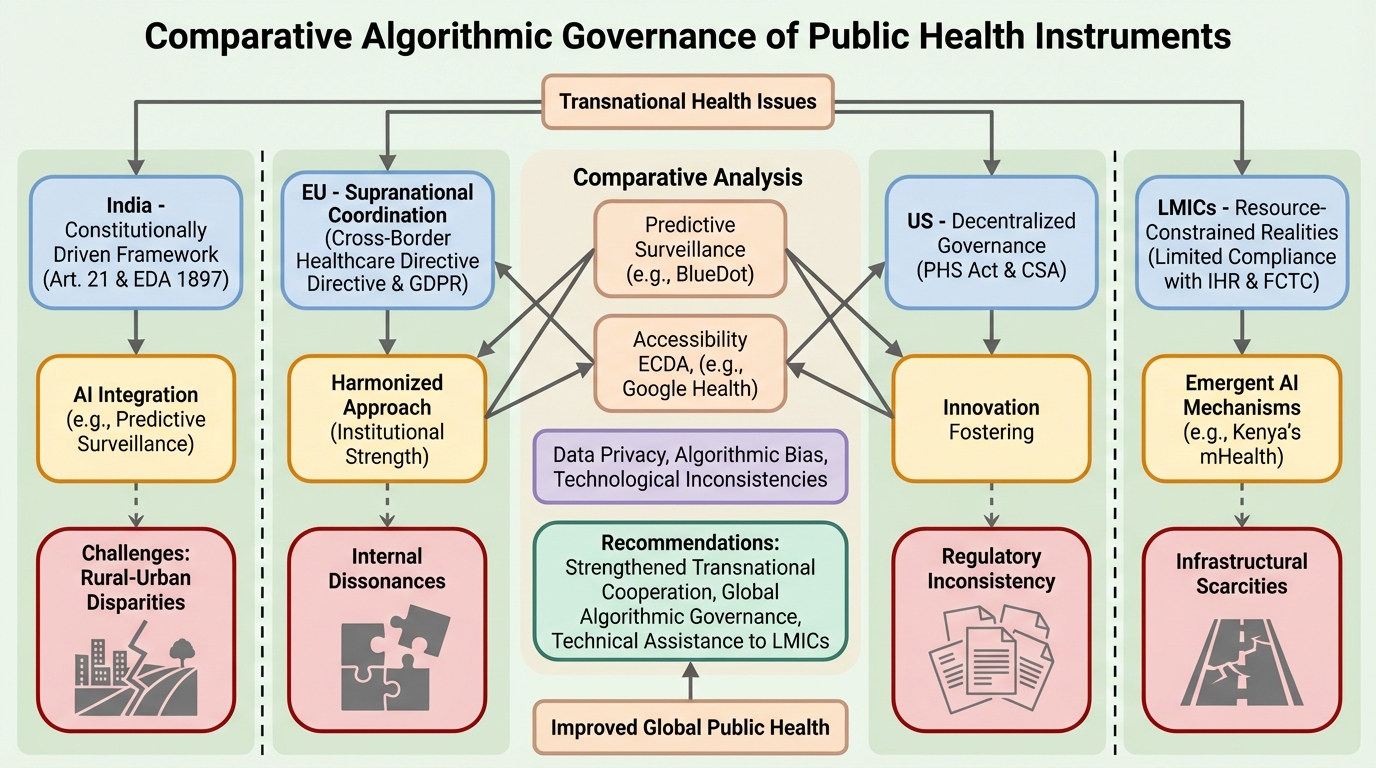
本研究は、人工知能(AI)が国際保健規則(IHR 2005)やWHOタバコ規制枠組条約(FCTC)の実施をいかに強化するかを、インド、EU、米国、および低中所得国(LMICs)の比較を通じて分析したものである。
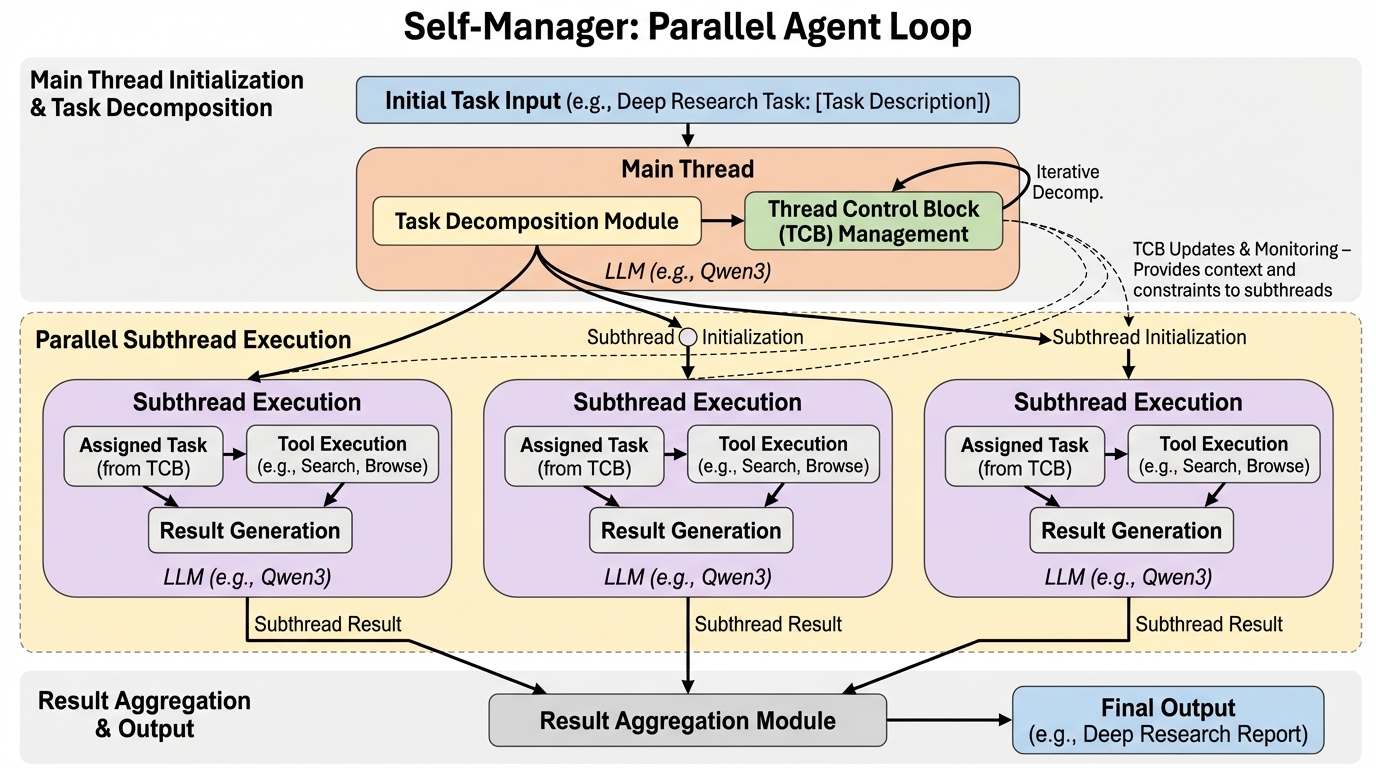
長文の深掘り調査において、従来のエージェントが抱えていた文脈の線形な蓄積による情報の希釈や、逐次実行による処理の停滞という課題を解決するため、非同期かつ並列な実行を可能にする新しいアーキテクチャ「Self-Manager」が提案されました。