大規模言語モデルにおける構造情報の創発とテスト時の利用について
大規模言語モデルが学習データから抽象的な構造情報をどのように獲得し、それを未知の組み合わせの生成(構成的汎用化)に利用できるかを、変形文法に基づく独自の自然言語データセットを用いて検証した。 実験の結果、モデル内部で構造情報の表現が明確になる時期は、単純な次単語予測の精度向上よりも、複雑な推論タスクの性能向上と強く相関しており、学習の進展に伴い構造の区別が急激に明確化する相転移現象が確認された。 しかし、学習時に見たことのない複数の構造を組み合わせる能力は依然として限定的であり、中間的な生成ステップを明示しない限り正確な出力を得ることが困難であることから、現在の学習手法における構成的な知識生成の限界が浮き彫りになった。
TL;DR(結論)
大規模言語モデルが学習データから抽象的な構造情報をどのように獲得し、それを未知の組み合わせの生成(構成的汎用化)に利用できるかを、変形文法に基づく独自の自然言語データセットを用いて検証した。 実験の結果、モデル内部で構造情報の表現が明確になる時期は、単純な次単語予測の精度向上よりも、複雑な推論タスクの性能向上と強く相関しており、学習の進展に伴い構造の区別が急激に明確化する相転移現象が確認された。 しかし、学習時に見たことのない複数の構造を組み合わせる能力は依然として限定的であり、中間的な生成ステップを明示しない限り正確な出力を得ることが困難であることから、現在の学習手法における構成的な知識生成の限界が浮き彫りになった。
なぜこの問題か
自然界や科学的発見のプロセスは、階層的な抽象構造の組み合わせによって成り立っている。人間は、既知の構成要素であるプリミティブを理解し、それらを新しい方法で再編成することで、一度も見たことがない概念や事象を把握する「構成的汎用化」の能力を持っている。人工知能が真の意味で新しい知識を生成し、学習データに含まれない未知の状況に適応するためには、単なる統計的なパターンマッチングを超えて、こうした抽象的な構造情報を学習し、自在に操作できる必要がある。既存の大規模言語モデルは、膨大なテキストデータから驚異的な予測精度を実現しているが、その内部で言語の階層的な構造や変換規則を真に理解しているのか、あるいは単に表面的な単語の並びを模倣しているだけなのかという点は、依然として議論の的となっている。特に、分布外のデータに対する堅牢性や、科学的なメカニズムの理解といった高度なタスクにおいて、モデルが内部的にどのような構造表現を構築し、それをテスト時にどう利用しているかを解明することは、次世代のAI開発において極めて重要な課題である。…
核心:何を提案したのか
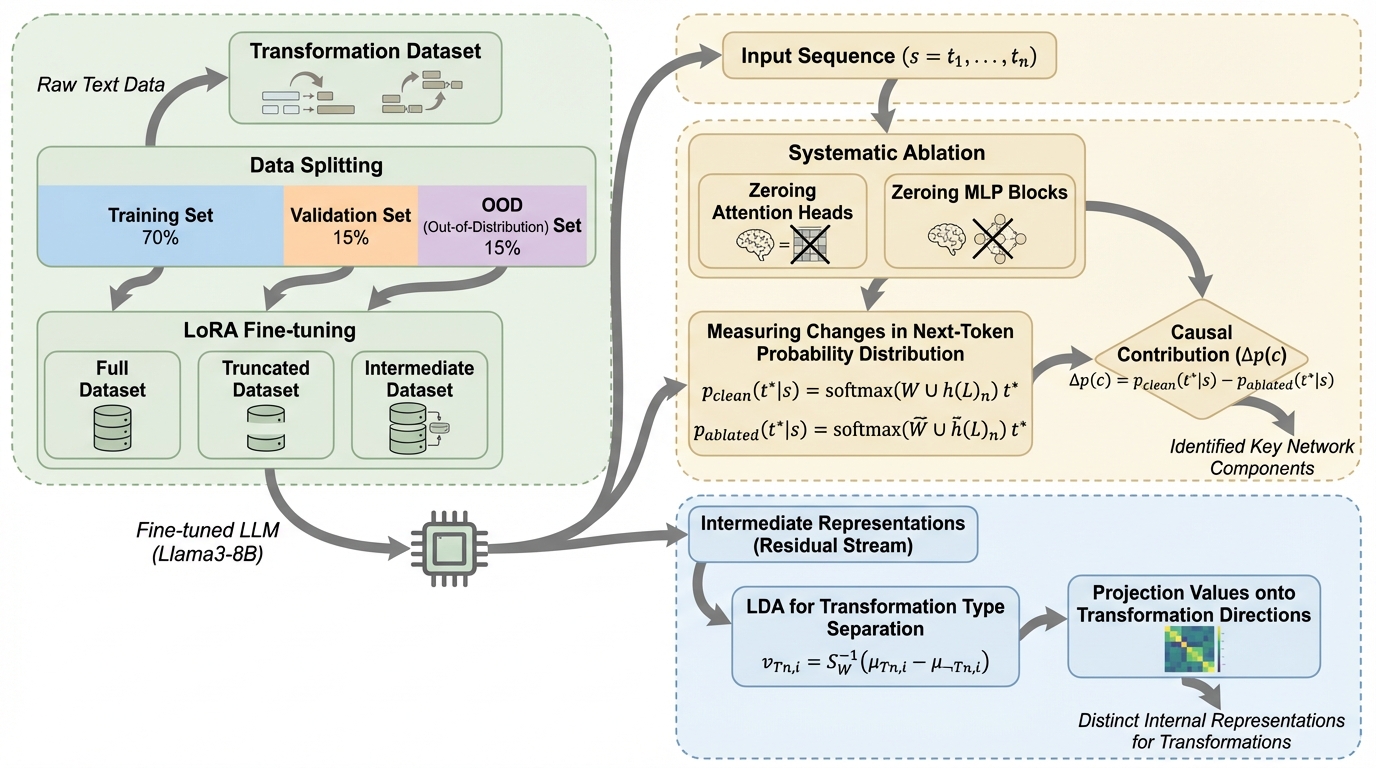
本研究の核心は、チョムスキーの変形文法(Transformational Grammar)に基づいた、モデルの構造的理解を精密に測定するための新しい自然言語データセットの提案である。変形文法では、文には意味的な核心をなす「深層構造」と、実際に発話される形式である「表層構造」が存在すると考える。研究チームは、この理論を応用し、入力文(深層構造に相当)に対して特定の変換規則を適用して出力文(表層構造に相当)を導き出すタスクを定義した。具体的には、外置(Extraposition)、疑問文形成(I-Movement)、受動態化(NP Passive)、主語の繰り上げ(NP Raising)、動詞移動(V-Movement)という5つの主要な構文カテゴリにわたる10種類の変換タイプを導入した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related