DモデルとEモデル:大規模言語モデルのサンプリング挙動における多様性と安定性のトレードオフ
大規模言語モデル(LLM)の次トークン予測確率は、情報の関連性や商品の購入確率といったタスクレベルの目標分布($P_{task}$)と密接に関連していますが、そのサンプリング挙動には「Dモデル」と「Eモデル」という二極化された特性が存在することが明らかになりました。 Qwen-2.
TL;DR(結論)
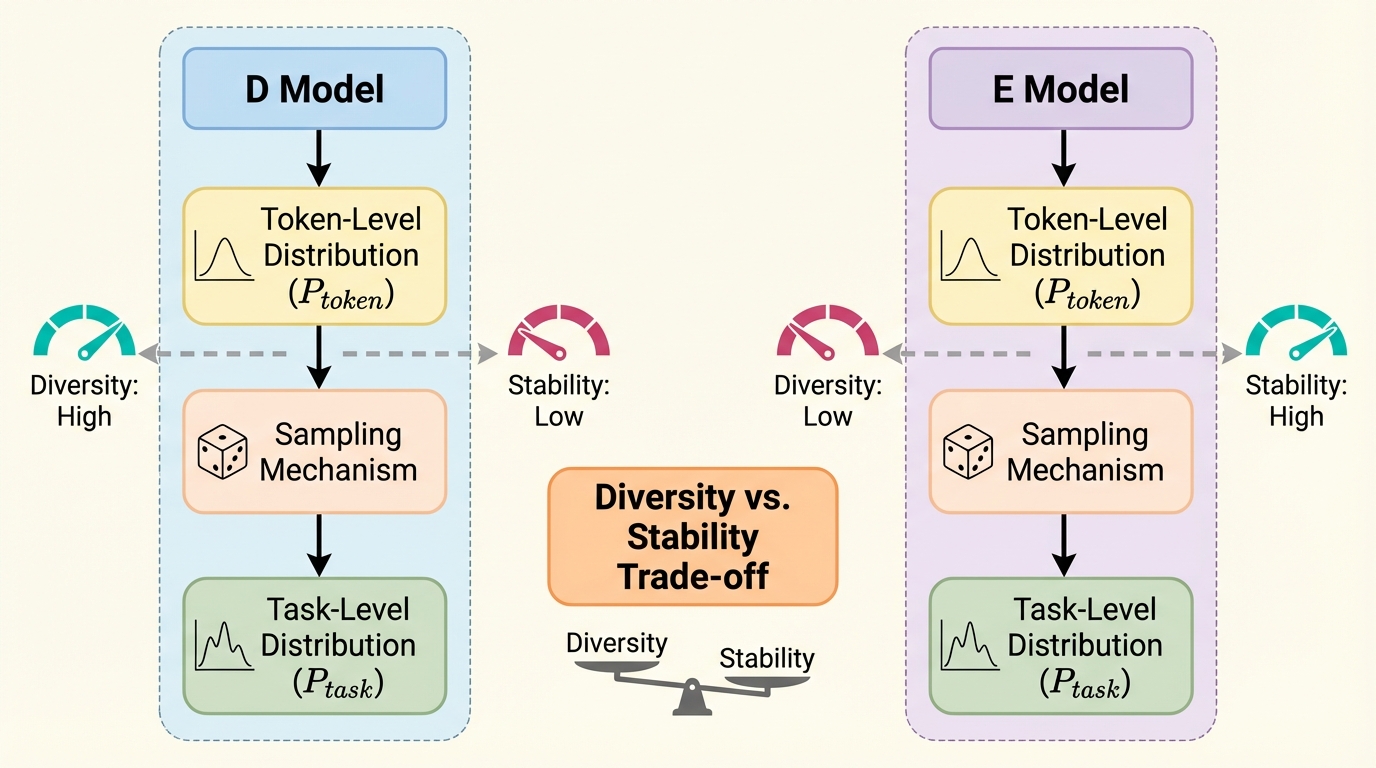
大規模言語モデル(LLM)の次トークン予測確率は、情報の関連性や商品の購入確率といったタスクレベルの目標分布($P_{task}$)と密接に関連していますが、そのサンプリング挙動には「Dモデル」と「Eモデル」という二極化された特性が存在することが明らかになりました。 Qwen-2.5などのDモデル(Deterministic)は、特定のトークンに確率が集中しステップごとの変動が激しい一方で、Mistral-SmallなどのEモデル(Exploratory)は確率分布が安定しており目標分布に対してより忠実なアライメントを示すという特徴を持っています。 これら二つのモデルタイプ間には多様性と安定性の体系的なトレードオフが存在しており、コード生成や推薦システムといった実世界のアプリケーションにおいて、不確実性を管理し信頼性を確保するためのモデル選択と構成に関する重要な指針を提供します。
なぜこの問題か
現代のインターネット環境において、大規模言語モデル(LLM)はコード生成の補助や、検索結果、ニュースフィード、推薦システムにおける情報の露出を制御する役割を急速に担うようになっています。モデルがどのコンテンツを表示し、どの程度の頻度で提示するかを決定する際、実質的には候補アイテムの分布からサンプリングを行っており、これがユーザーの視覚情報、信念、行動を形作ることになります。そのため、このサンプリングプロセスが監査可能であり、説明可能であることを保証することは、責任ある技術開発において極めて重要な側面です。 LLMの能力の根幹は、大規模なテキストデータに含まれる確率分布を学習しモデル化する能力にあります。既存のテキストコンテキストが与えられたとき、モデルは次に続く最も可能性の高いトークンを予測することを学習します。モデルの主要な出力は、語彙全体にわたる確率分布($P{token}$)であり、これは現在の文脈における各トークンの出現しやすさを定量化したものです。しかし、ウェブ上のタスクは本質的に不確実であり、検索や推薦の文脈では、特定のクエリに対して候補アイテムの確率分布($P{task}$)が誘導されます。…
核心:何を提案したのか
本研究では、LLMの確率的サンプリング能力を分析するために、タスクレベルの目標分布($P{task}$)、モデル内部のトークン確率分布($P{token}$)、そして最終的なサンプリング結果の分布($P{result}$)を統合的に評価する枠組みを提案しました。この分析の過程で、LLMの挙動が必ずしも極端な自信に基づいているわけではなく、二つの代表的なパターンに分類できることを発見しました。 第一のパターンは「決定論的なグローバルプランニング」を特徴とする「Dモデル(Deterministic Models)」です。Dモデルは、生成の各ステップにおいて一つのトークンの確率が1.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related