MergeMix: 学習可能なモデルマージによる学習途中データ混合比の最適化
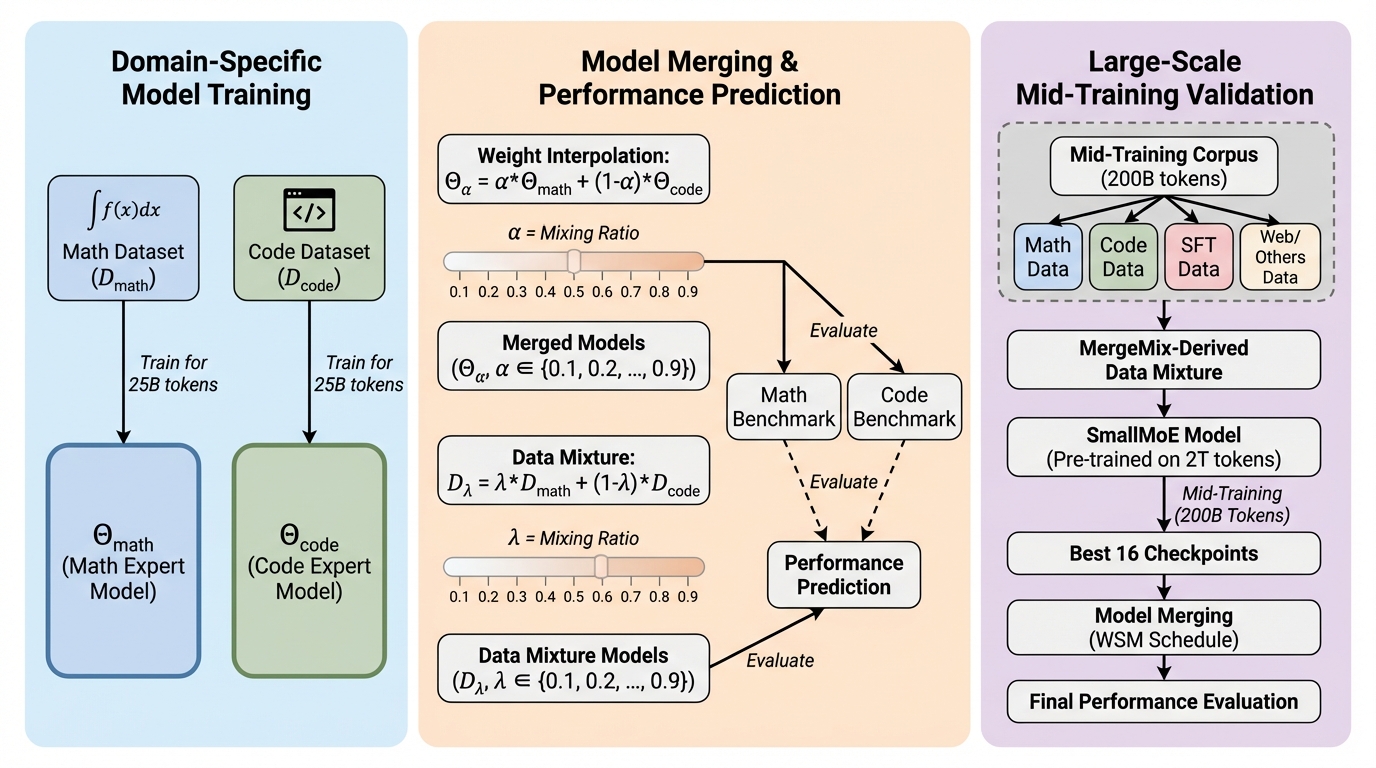
MergeMixは、大規模言語モデル(LLM)の中間学習における最適なデータ混合比を、モデルマージの重みを代理指標(プロキシ)として活用することで効率的に特定する新しい手法である。 従来のデータ混合比の最適化は、膨大な計算コストを伴う試行錯誤やスケーリング則の推定に依存していたが、本手法は少量のトークンで学習したドメイン専門家モデルを線形補間することで、実トレーニングなしに下流タスクの性能を予測する。 実験では8Bおよび16Bのモデルにおいて、手動による網羅的な調整と同等以上の性能を達成しつつ、探索コストを100倍以上削減することに成功しており、高いランク相関とスケールを跨いだ転移性も確認されている。
TL;DR(結論)
MergeMixは、大規模言語モデル(LLM)の中間学習における最適なデータ混合比を、モデルマージの重みを代理指標(プロキシ)として活用することで効率的に特定する新しい手法である。 従来のデータ混合比の最適化は、膨大な計算コストを伴う試行錯誤やスケーリング則の推定に依存していたが、本手法は少量のトークンで学習したドメイン専門家モデルを線形補間することで、実トレーニングなしに下流タスクの性能を予測する。 実験では8Bおよび16Bのモデルにおいて、手動による網羅的な調整と同等以上の性能を達成しつつ、探索コストを100倍以上削減することに成功しており、高いランク相関とスケールを跨いだ転移性も確認されている。
なぜこの問題か
大規模言語モデル(LLM)の性能を最大限に引き出すためには、学習データの混合比を最適化することが極めて重要である。学習のライフサイクルにおいて、データはモデルの能力を形成する根本的な燃料であり、その戦略的な選別は事前学習、中間学習、事後学習の各段階で不可欠な役割を果たす。特に中間学習(mid-training)の段階では、推論能力やコーディング能力といった特定の能力を強化するために、厳選されたデータセットが導入される。しかし、どのデータをどの程度の割合で混ぜるべきかを判断するための既存の手法には、いくつかの重大な課題が存在している。 現在、産業界で行われている一般的な手法は、人間の直感に基づいたヒューリスティックな試行錯誤に大きく依存しており、最適な候補を特定するために、膨大な計算資源を投じてフルスケールのトレーニングを何度も繰り返す必要がある。最近ではこのプロセスを自動化しようとする研究も進んでいるが、依然として課題は多い。第一に、スケーリング則のフィッティングや混合回帰モデルの学習、あるいは反復的なチューニングのために、数十から数百回の代理トレーニングを実行する必要があり、依然として多大な計算コストが発生する。…
核心:何を提案したのか
本研究では、データ混合比の最適化問題を「モデルマージ」のタスクとして再定義する新しいフレームワーク「MergeMix」を提案している。この手法の核心的な洞察は、中間学習の段階において、特定のドメインに特化した専門家モデルの重みを線形補間することが、実際にデータを混合して学習した結果の極めて忠実な代理指標(プロキシ)になるという点にある。つまり、あらゆる混合比の候補に対して高コストなトレーニングを繰り返す代わりに、最小限のデータで学習した少数の専門家モデルを用意し、そのマージ重みを最適化することで、最適なデータ構成を導き出すのである。 MergeMixは、モデルのトレーニングにかかる膨大なコストを、モデルマージと推論という無視できるほど小さなコストに変換する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related