関数呼び出しエージェントのための合成データにおける言語的および引数の多様性
関数呼び出しエージェントの学習には多様なデータが不可欠ですが、既存手法は関数の種類や呼び出しパターンに偏り、ユーザーの言い回しの多様性(言語的多様性)や引数の値の網羅性(引数の多様性)が不足しているという課題がありました。
TL;DR(結論)
関数呼び出しエージェントの学習には多様なデータが不可欠ですが、既存手法は関数の種類や呼び出しパターンに偏り、ユーザーの言い回しの多様性(言語的多様性)や引数の値の網羅性(引数の多様性)が不足しているという課題がありました。 本研究は、手動のルールや分類学に頼らず、言語的・意味的・構文的な多様性指標を直接最適化することで、クエリと引数の両方で高い多様性を持つ合成データを自動生成する、ロバストで汎用的な強欲(Greedy)生成手法を提案しました。 実証実験の結果、提案手法で作成したデータは既存のToolAceやAPIGenよりも多様性が高く、これを用いて学習したモデルはBFCLベンチマークで精度が7.4%向上し、未知のデータに対する高い汎化性能(OOD性能)を示すことが確認されました。
なぜこの問題か
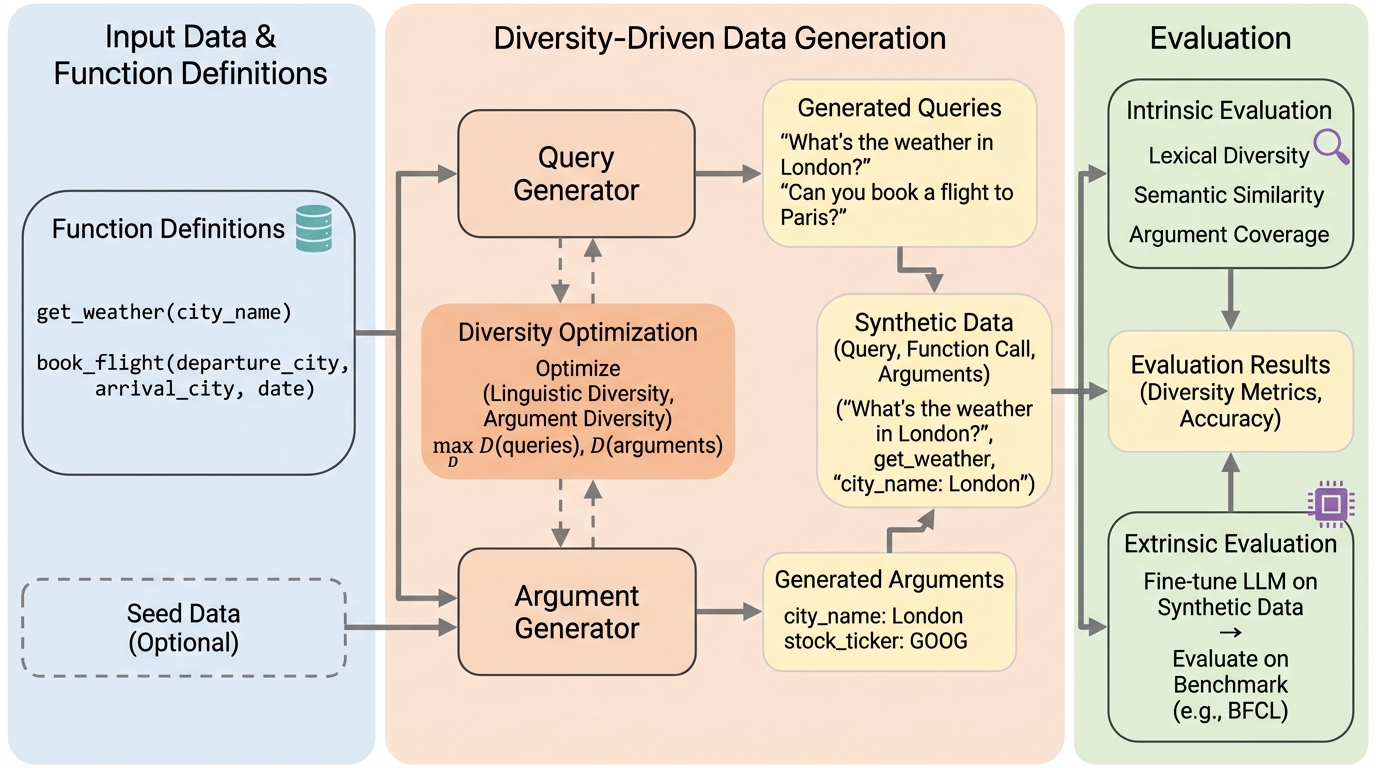
現代のLLMベースのシステムにおいて、外部のAPIやツール、サービスと構造化された呼び出しを通じて対話する関数呼び出しエージェントは、モデルの能力を拡張するための中心的な役割を担っています。しかし、このようなエージェントを構築する上での大きな障壁は、高品質で多様性に富んだ訓練データおよび評価データを入手することが極めて困難であるという点にあります。これまでの研究では、手動でキュレーションされたベンチマークの導入や、合成データを自動生成する手法が提案されてきましたが、それらの多くは特定の側面の多様性にのみ焦点を当てていました。具体的には、呼び出される関数の種類の多さやドメインの広さ、単一関数か複数関数かといった呼び出し構造、あるいは単一ターンか複数ターンかといった対話の形式に主眼が置かれてきました。 本研究では、これまでのアプローチにおいて「言語的な表現の多様性」と「引数の値の多様性」という2つの重要な次元が十分に探索されていないことを指摘しています。第一の次元である言語的多様性は、ユーザーがリクエストを発する際の言語的な形式や言い回しのバリエーションを指します。…
核心:何を提案したのか
本研究の核心的な貢献は、手書きのルールや事前に定義された分類学(タクソノミー)に依存することなく、多様なアイテムの集合を自動的に生成する新しいコンポーネントを提案したことです。従来の手法では、ユーザーのペルソナを明示的に列挙したり、バリエーションを促すために言語的な特性を手動で指定したりすることが一般的でした。しかし、本手法は汎用的な多様性指標を直接最適化することでアイテムを生成するため、特定のドメインや設定に縛られないロバスト性を備えています。このアプローチの大きな利点は、新しいドメインや設定に対しても自動的に適応できることであり、手動で定義されたプロンプトやペルソナのプールを個別のトピックに合わせて調整する手間を省くことができます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related