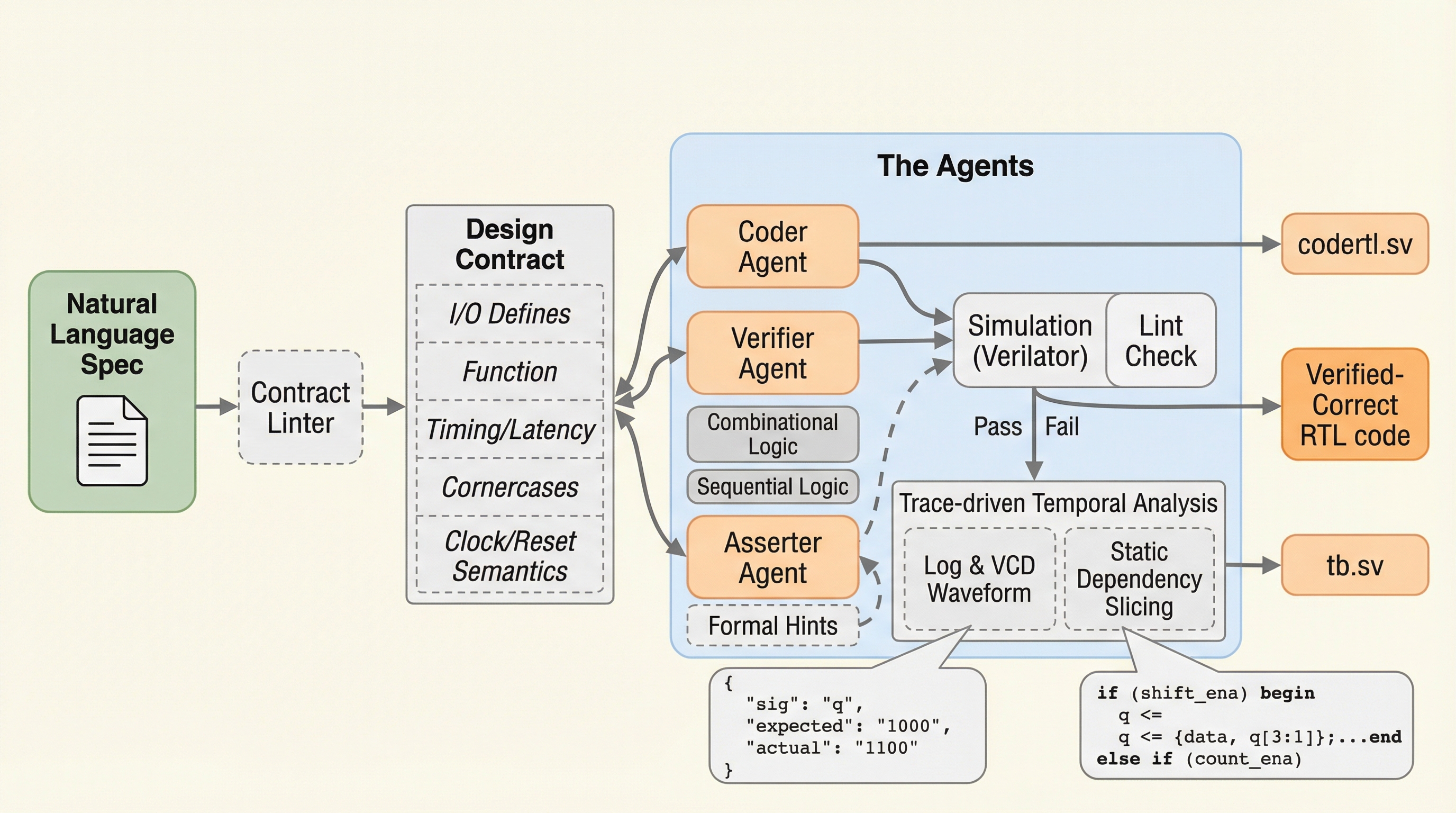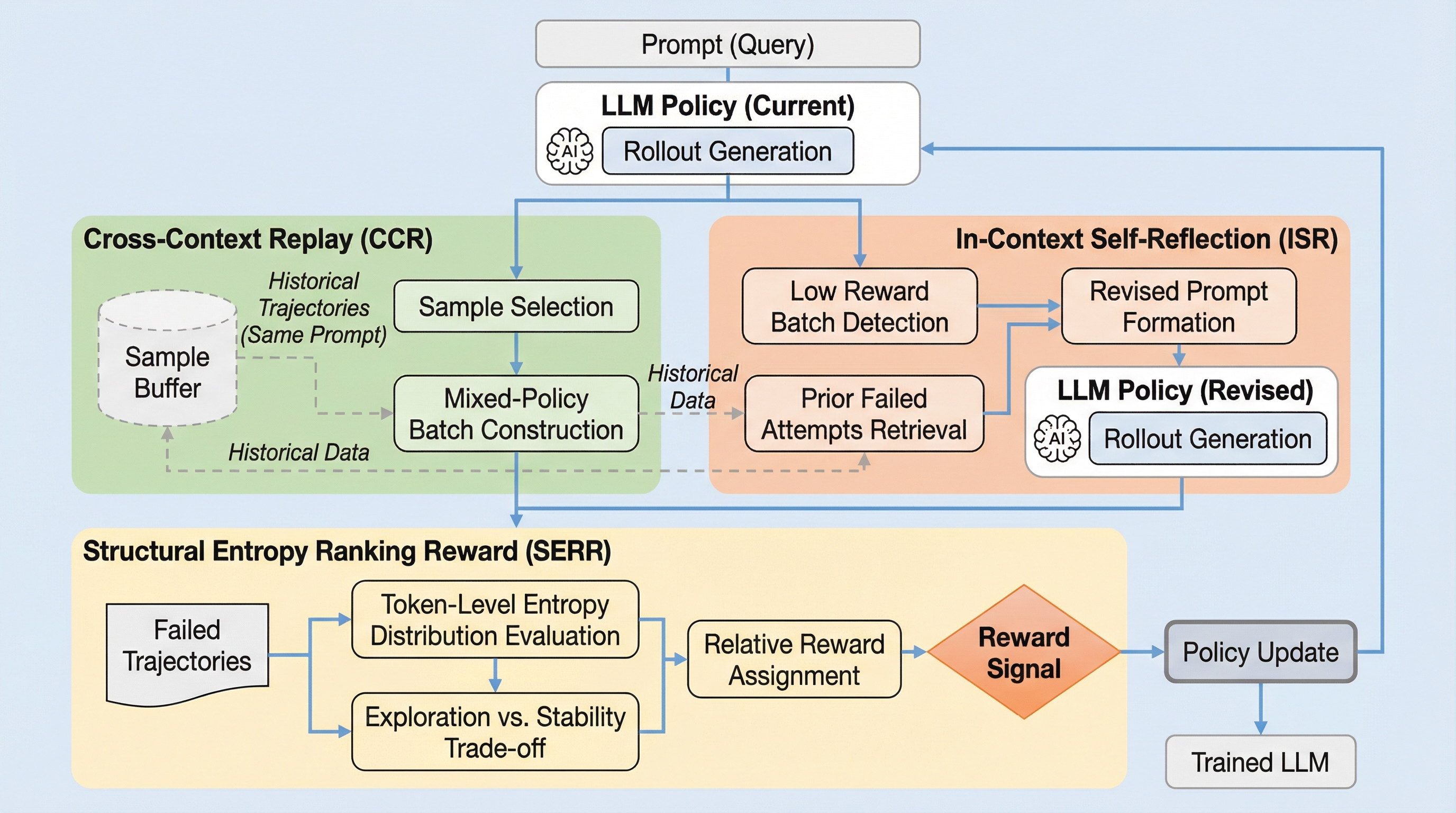
R^3:LLMの強化学習のためのリプレイ、リフレクション、およびランキング報酬
大規模推論モデルの学習において、グループ内の報酬差が消失し学習が停滞する「アドバンテージの崩壊」を防ぐため、過去の履歴を活用するクロスコンテキスト・リプレイ(CCR)、失敗から学ぶインコンテキスト自己内省(ISR)、およびトークン単位のエントロピーに基づく構造的エントロピー・ランキング報酬(SERR)を統合した強化学習メカニズム「R^3」が提案されました。 DeepSeek-R1-Distill-Qwen-1.5Bおよび7Bをベースに数学ドメインで訓練した結果、1.5Bという小規模なモデルでありながらAIME 2024などの難関ベンチマークで従来の7Bクラスのモデルを凌駕する最先端の性能を達成し、同時に推論に必要なトークン数の削減にも成功しています。 本手法は、プロセスレベルの注釈に頼ることなく、外部的な介入と内部的な自己最適化を組み合わせることで、困難なタスクにおいても安定した学習信号を維持し、モデルが自身の過去の誤りから自律的に推論プロセスを洗練させることを可能にした画期的なフレームワークです。