R^3:LLMの強化学習のためのリプレイ、リフレクション、およびランキング報酬
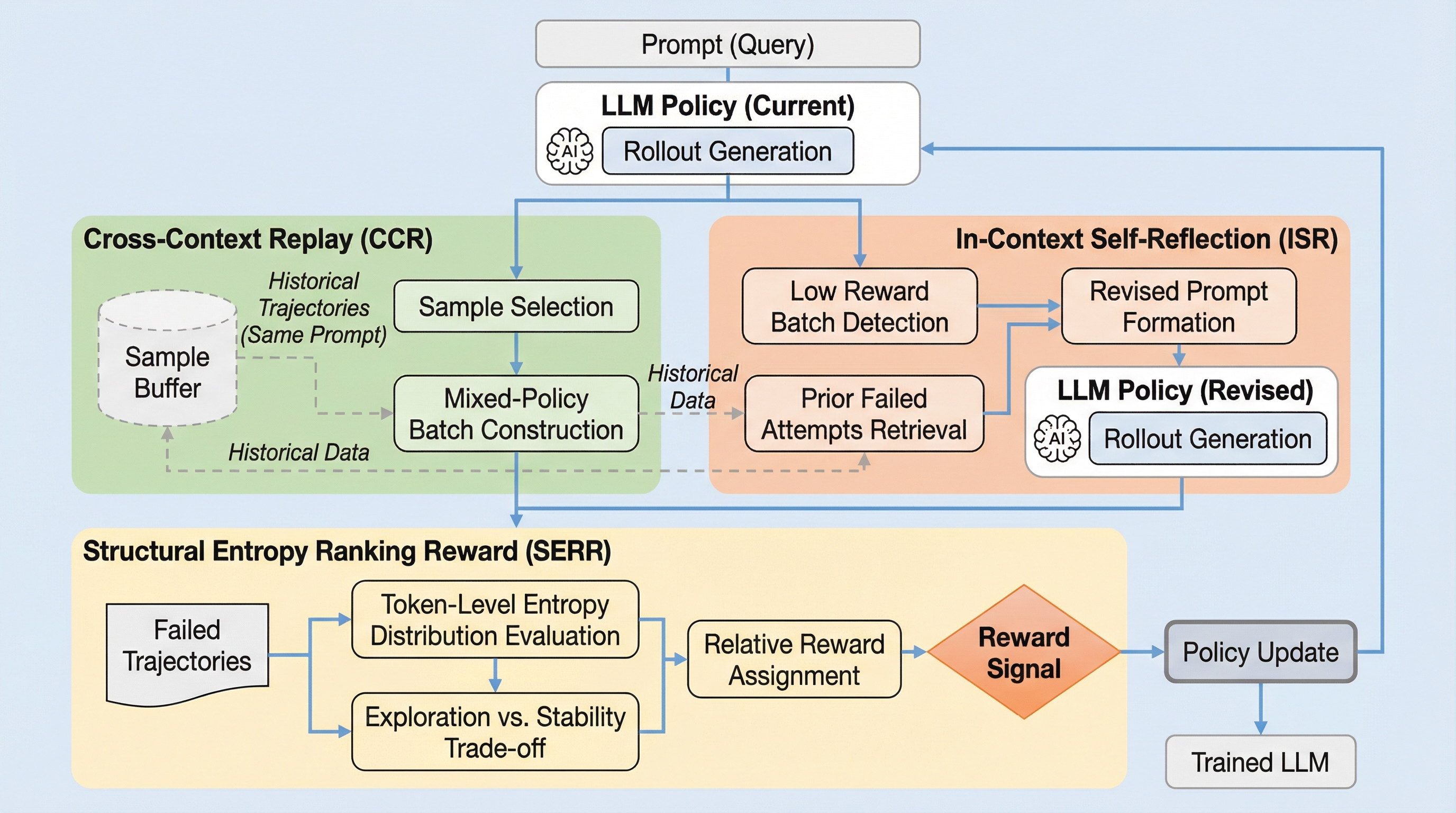
大規模推論モデルの学習において、グループ内の報酬差が消失し学習が停滞する「アドバンテージの崩壊」を防ぐため、過去の履歴を活用するクロスコンテキスト・リプレイ(CCR)、失敗から学ぶインコンテキスト自己内省(ISR)、およびトークン単位のエントロピーに基づく構造的エントロピー・ランキング報酬(SERR)を統合した強化学習メカニズム「R^3」が提案されました。 DeepSeek-R1-Distill-Qwen-1.5Bおよび7Bをベースに数学ドメインで訓練した結果、1.5Bという小規模なモデルでありながらAIME 2024などの難関ベンチマークで従来の7Bクラスのモデルを凌駕する最先端の性能を達成し、同時に推論に必要なトークン数の削減にも成功しています。 本手法は、プロセスレベルの注釈に頼ることなく、外部的な介入と内部的な自己最適化を組み合わせることで、困難なタスクにおいても安定した学習信号を維持し、モデルが自身の過去の誤りから自律的に推論プロセスを洗練させることを可能にした画期的なフレームワークです。
TL;DR(結論)
大規模推論モデルの学習において、グループ内の報酬差が消失し学習が停滞する「アドバンテージの崩壊」を防ぐため、過去の履歴を活用するクロスコンテキスト・リプレイ(CCR)、失敗から学ぶインコンテキスト自己内省(ISR)、およびトークン単位のエントロピーに基づく構造的エントロピー・ランキング報酬(SERR)を統合した強化学習メカニズム「R^3」が提案されました。 DeepSeek-R1-Distill-Qwen-1.5Bおよび7Bをベースに数学ドメインで訓練した結果、1.5Bという小規模なモデルでありながらAIME 2024などの難関ベンチマークで従来の7Bクラスのモデルを凌駕する最先端の性能を達成し、同時に推論に必要なトークン数の削減にも成功しています。 本手法は、プロセスレベルの注釈に頼ることなく、外部的な介入と内部的な自己最適化を組み合わせることで、困難なタスクにおいても安定した学習信号を維持し、モデルが自身の過去の誤りから自律的に推論プロセスを洗練させることを可能にした画期的なフレームワークです。
なぜこの問題か
大規模推論モデル(LRM)は、複雑な問題を解決するために構造化された思考プロセスを構築することを目指していますが、その学習を安定させることは容易ではありません。近年、プロセスレベルの注釈を必要とせずに方策を最適化できる手法として、グループ内での相対的な報酬を評価するGRPO(Group Relative Policy Optimization)などが注目されています。しかし、これらの手法は本質的に、同じバッチ内で生成された複数の回答の間に品質の差が存在することを前提としています。この「アドバンテージの差」が、モデルがどの方向へ改善すべきかを示す重要な学習信号となります。 特に数学のような高度な論理的思考を要するタスクでは、モデルが生成する回答の報酬分布を適切に制御することが困難です。理想的な状況では、グループ内に正解と不正解が混在し、相対的な優劣が明確になることで正確なアドバンテージ推定が可能になります。しかし、実際には、生成されたすべての回答が完全に誤っていたり、内容が極めて似通っていたり、あるいは最大トークン長の制限によって途中で切断されたりすることが頻繁に起こります。…
核心:何を提案したのか
本研究では、上述のアドバンテージ崩壊という根本的な課題を解決するために、「R^3(Replay, Reflection, and Ranking Rewards)」と名付けられた新しい強化学習メカニズムを提案しています。このフレームワークの最大の特徴は、外部的な介入と内部的な自己最適化を巧みに組み合わせることで、どのような困難な状況下でもグループ内のアドバンテージを明示的に維持し、学習を継続させる点にあります。R^3は、主に3つの革新的なアプローチで構成されています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related