RvB:反復的なレッド・ブルー・ゲームによるAIシステム堅牢化の自動化
RvBは、大規模言語モデルの安全性を飛躍的に高めるために開発された、学習や微調整を一切必要としない革新的な自動堅牢化フレームワークであり、攻撃を担うレッドチームと防御を担うブルーチームが対話的に試行錯誤を繰り返す「不完全情報ゲーム」として設計されている。
TL;DR(結論)
RvBは、大規模言語モデルの安全性を飛躍的に高めるために開発された、学習や微調整を一切必要としない革新的な自動堅牢化フレームワークであり、攻撃を担うレッドチームと防御を担うブルーチームが対話的に試行錯誤を繰り返す「不完全情報ゲーム」として設計されている。 この手法は、モデルの内部パラメータを更新する代わりに、外部メモリとしてのシステム状態を更新することで、未知の脆弱性に対する適応能力を継続的に向上させ、特定の攻撃手法に過剰適合しない汎用的な防御策を自律的に構築することを可能にする。 実際の検証において、コードの脆弱性修正で90%、プロンプト注入対策で45%という高い防御成功率を達成し、誤検知をほぼゼロに抑えつつ、既存の協調型システムを上回る圧倒的な性能とリソース効率、そして未知の脅威に対する高い一般化能力を実証した。
なぜこの問題か
大規模言語モデル(LLM)の急速な発展は、サイバーセキュリティの領域に「攻撃」と「防御」の双方向で強力な進化をもたらしたが、それゆえに新たな課題も浮き彫りになっている。LLMは自律的なペネトレーションテストを実行したり、複雑なジェイルブレイク攻撃を仕掛けたりする攻撃的なツールとして機能する一方で、脆弱性へのパッチ適用を自動化したり、有害コンテンツの生成を防ぐ動的なガードレールとして機能したりする防御的な盾としての役割も期待されている。しかし、現状ではこれら攻撃と防御の研究は互いに分断されており、統一された枠組みが存在しないという深刻な問題がある。従来の防御フレームワークの多くは、静的なベンチマークや事後的な分析に過度に依存しており、日々刻々と出現する未知の攻撃ベクトルを予測し、先回りして防御を固める能力には限界がある。対照的に、攻撃側のエージェントは応答性の高い敵対者が存在しない環境で動作することが多く、最悪のシナリオにおけるターゲットシステムの真の回復力や堅牢性を正確に評価することができていない。このような孤立した状況は、攻撃と防御が互いに影響を与え合いながら進化していく、ゲーム理論的なダイナミズムの欠如を意味している。…
核心:何を提案したのか
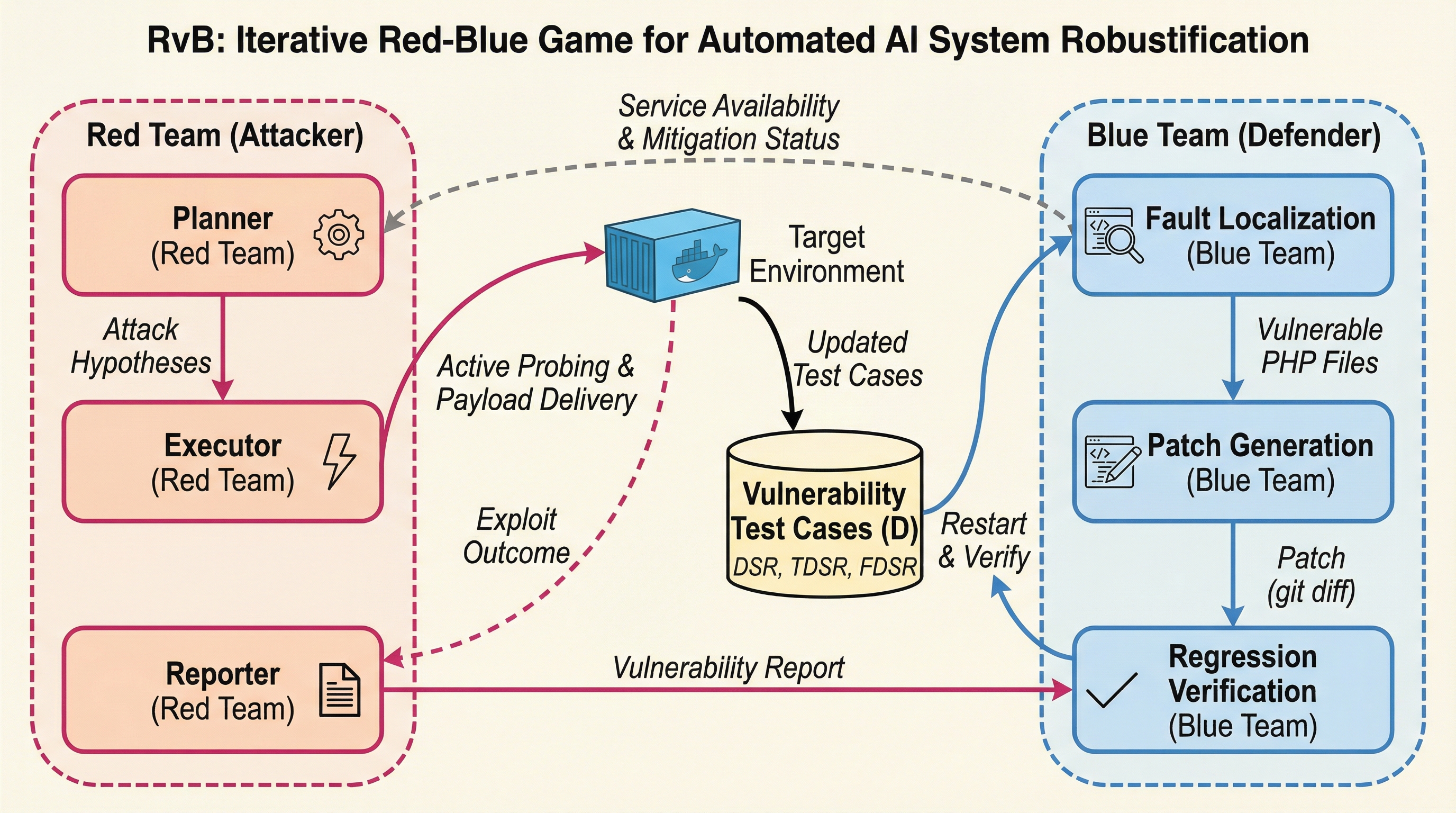
本研究では、AIシステムの堅牢化を自動化するための全く新しいパラダイムとして「Red Team vs. Blue Team(RvB)」フレームワークを提案している。このフレームワークの最も際立った特徴は、高価なモデルの微調整や膨大な学習データを必要とする従来の強化学習の手法とは異なり、トレーニングを一切必要としない「学習不要(training-free)」な設計を採用している点にある。RvBは、数学的には逐次的な不完全情報ゲームとして定式化されており、エージェントの内部パラメータを直接更新する代わりに、外部化されたメモリとしてのシステム状態を更新していくことで能力を向上させる。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related