TokenSeek: インスタンスごとのトークン破棄によるメモリ効率の高いファインチューニング
大規模言語モデルのファインチューニングにおいて、メモリ消費の最大87%を占めるアクティベーションの課題を解決するため、各データの文脈と勾配情報から重要なトークンのみを選択して学習する「TOKENSEEK」が提案されました。 この手法は、Llama3.2 1Bにおいて元のメモリのわずか14.8%(2.
TL;DR(結論)
大規模言語モデルのファインチューニングにおいて、メモリ消費の最大87%を占めるアクティベーションの課題を解決するため、各データの文脈と勾配情報から重要なトークンのみを選択して学習する「TOKENSEEK」が提案されました。 この手法は、Llama3.2 1Bにおいて元のメモリのわずか14.8%(2.8GB)という極めて低い消費量で、フルパラメータチューニングと同等、あるいはそれを上回る性能を達成し、学習の安定性と効率性の両立を実現しています。 アーキテクチャに依存しない汎用的なプラグインとして設計されており、QwenやLlamaといった異なるモデルや、LoHa、QLoRAなどの既存の軽量化技術ともシームレスに統合して、パラメータとメモリの両面で高い効率性を発揮することが可能です。
なぜこの問題か
大規模言語モデル(LLM)を特定のタスクに適応させるファインチューニングは、事前学習で得た知識を活用するための標準的な手法ですが、その過程で発生する膨大なメモリ消費が大きな障壁となっています。メモリ消費の内訳を詳細に分析すると、モデルのパラメータ、勾配、オプティマイザの状態、そして中間層のアクティベーションという主要な要素が存在します。Llama3 8Bの例では、バッチサイズが1の場合でもアクティベーションがメモリ消費全体の87%を占めており、これが学習における最大のボトルネックとなっていることが明らかです。既存のメモリ節約手法には、学習パラメータ数を減らすPEFTや、勾配更新を効率化する手法がありますが、アクティベーションそのものを削減する手法が最も直接的で効果的な解決策とされています。 しかし、従来のアクティベーション最適化手法には大きな欠点がありました。それは、入力されるデータの個別の内容や特徴を考慮せず、すべてのインスタンスに対して一律の削減戦略を適用する「データに依存しない(data-agnostic)」性質です。…
核心:何を提案したのか
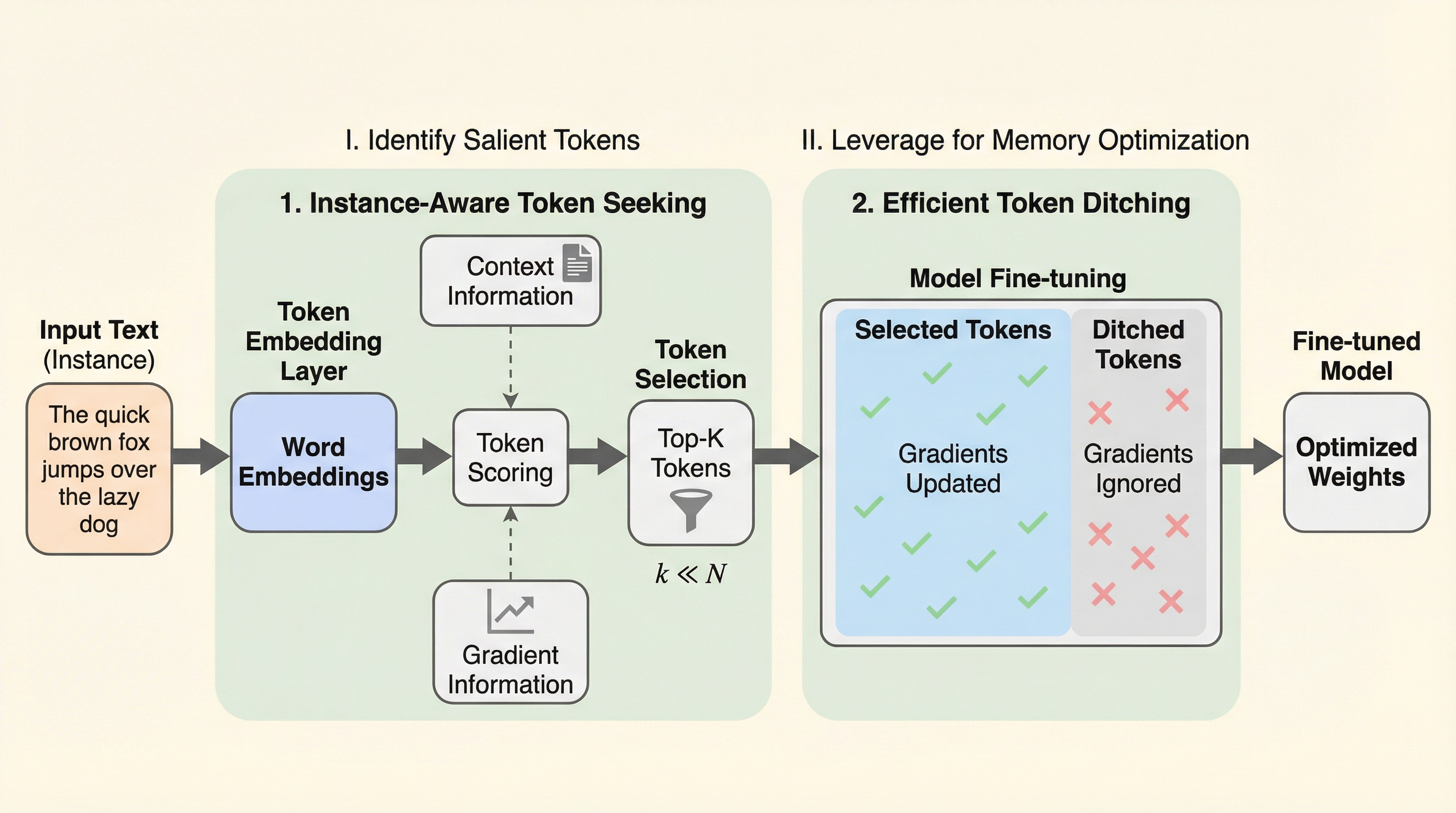
本研究では、大規模言語モデルのファインチューニングにおけるメモリ効率と性能のトレードオフを解消するために、新しいプラグイン手法である「TOKENSEEK」を提案しました。この手法の核心は、学習プロセスにおいて「どのトークンが重要か」をインスタンスごとに動的に評価し、重要度の低いトークンのアクティベーションを戦略的に破棄(ditching)することにあります。これにより、モデルのアーキテクチャを変更することなく、大幅なメモリ削減と高い学習性能を同時に達成することを目指しています。 TOKENSEEKは、大きく分けて2つの主要なプロセスで構成されています。第一のプロセスは「インスタンスを考慮したトークンの探索(Instance-Aware Token Seeking)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related