GAVEL:アクティベーション監視を通じたルールベースの安全性に向けて
大規模言語モデル(LLM)の内部状態を「認知要素(CE)」という解釈可能な最小単位に分解し、それらを論理ルールで組み合わせることで、高度な安全監視を実現するフレームワーク「GAVEL」が提案されました。
TL;DR(結論)
大規模言語モデル(LLM)の内部状態を「認知要素(CE)」という解釈可能な最小単位に分解し、それらを論理ルールで組み合わせることで、高度な安全監視を実現するフレームワーク「GAVEL」が提案されました。従来のテキスト監視や広範なデータセットによる検知器とは異なり、モデルの再学習を必要とせず、特定のドメインやポリシーに合わせた精密な安全策をリアルタイムで構築・更新することが可能になります。サイバーセキュリティのルール共有の慣習をAIの安全性に応用することで、透明性が高く、コミュニティ全体で再利用可能な標準化されたガバナンスの基盤を提供し、誤検知の抑制と説明責任の両立を目指しています。
なぜこの問題か
大規模言語モデル(LLM)の普及に伴い、その安全性を確保するためのガードレールが不可欠となっていますが、従来の入力・出力テキストを監視する手法には限界があります。攻撃者は、有害な意図を言い換えたり隠蔽したりする「表現攻撃」を用いることで、表面上のテキストフィルタリングを容易に回避できてしまいます。この課題に対し、モデルが内部で情報を処理する際のアクティベーション(活性化状態)を直接監視する手法が注目されていますが、既存のアプローチには主に3つの大きな問題が存在します。 第一に、精度の低さです。既存の検知器は「サイバー犯罪」や「誤情報」といった非常に広範で抽象的なカテゴリのデータセットで学習されるため、特定の文脈を正しく判断できず、多くの誤検知を発生させます。例えば、人種差別的なコンテンツを防ぐための検知器が、民族文化に関する無害な議論まで誤って遮断してしまうといったケースが挙げられます。実用的な安全策として機能するためには、極めて低い誤検知率が求められます。 第二に、柔軟性の欠如です。実際の運用現場では、特定の企業ポリシーの遵守や知的財産権の保護など、細分化されたドメイン固有の制約を課す必要があります。…
核心:何を提案したのか
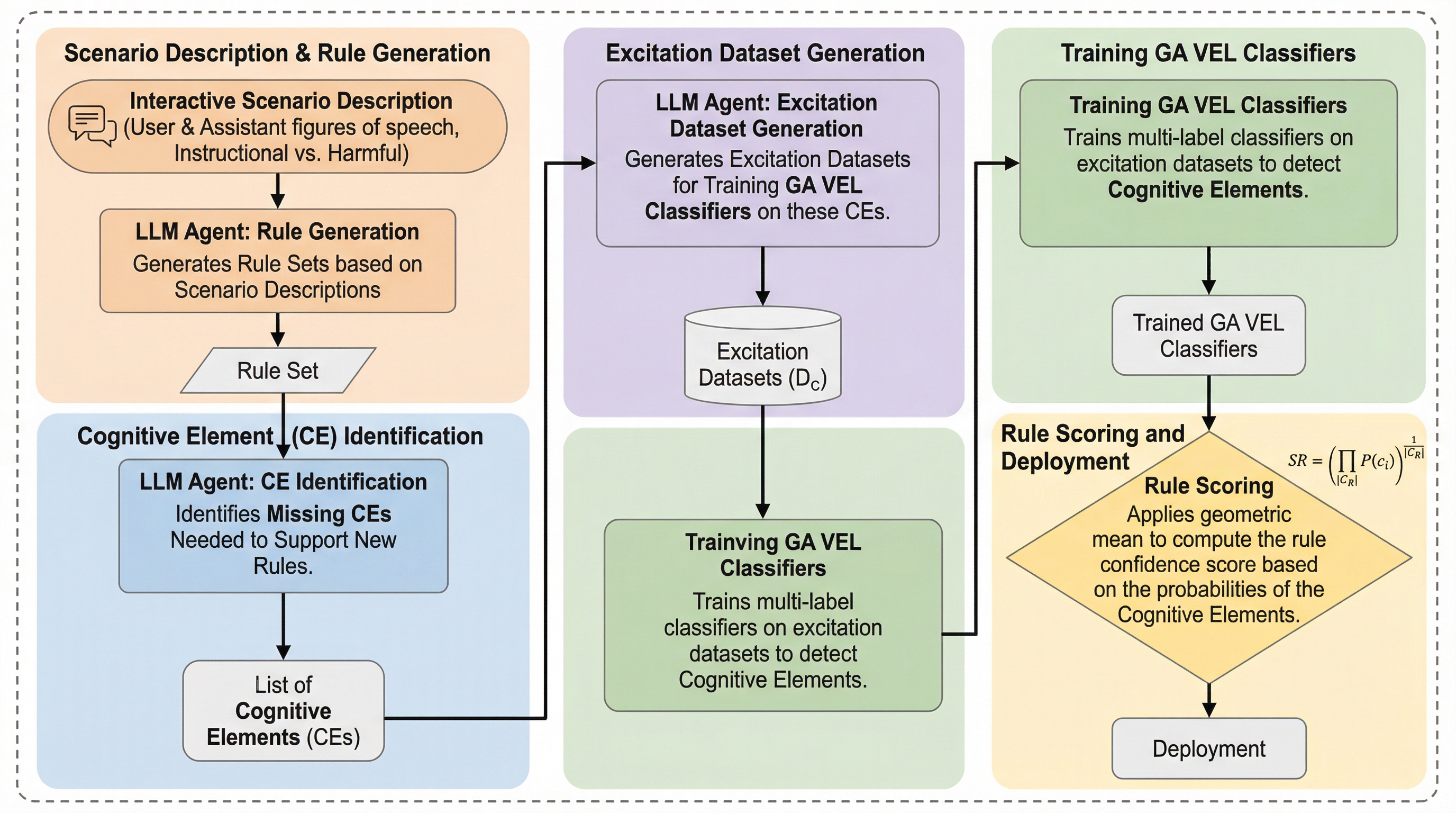
本研究は、サイバーセキュリティ分野で脅威検知に広く用いられている「ルール共有」のパラダイムをAIの安全性に応用した「GAVEL(Governance via Activation-based Verification and Extensible Logic)」を提案しました。このフレームワークの核心は、モデルの内部状態を「認知要素(Cognitive Elements: CEs)」という、きめ細かく解釈可能なプリミティブ(基本単位)としてモデル化することにあります。 認知要素(CE)とは、モデルが実行している特定のタスク、振る舞い、あるいは思考しているトピックを指します。例えば、「脅迫を行う」「支払い情報を取得する」「人間に成りすます」「特定の場所へ行くよう指示する」といった具体的な要素がCEとして定義されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related