マルチモーダル大規模言語モデルの音声推論能力のためのベンチマーク
現在のマルチモーダル大規模言語モデル(MLLM)の音声評価指標は、話者識別や性別判定といった個別のタスクに偏っており、複数の音声情報を組み合わせて論理的に思考する「推論能力」を十分に測定できていない。
TL;DR(結論)
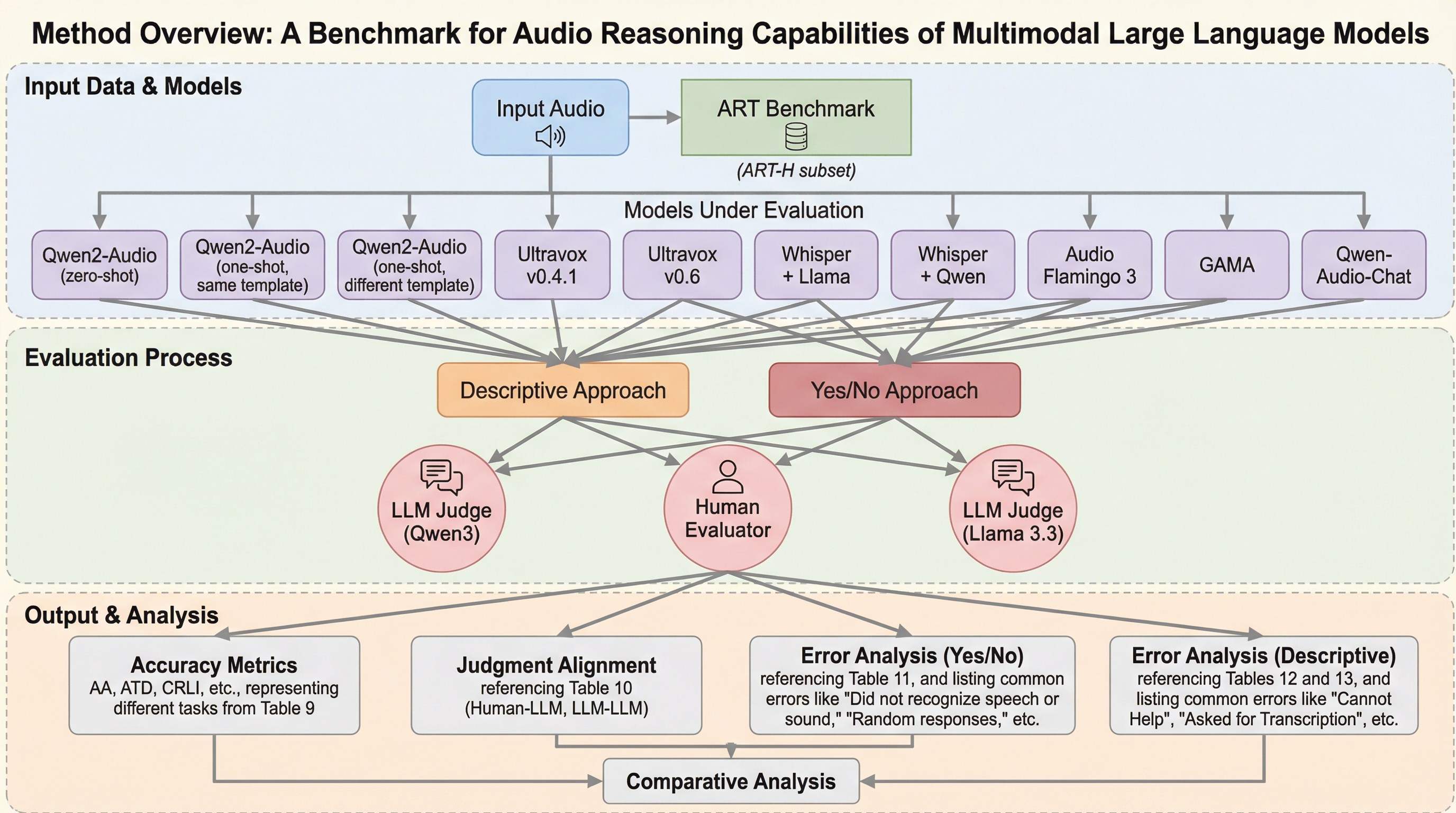
現在のマルチモーダル大規模言語モデル(MLLM)の音声評価指標は、話者識別や性別判定といった個別のタスクに偏っており、複数の音声情報を組み合わせて論理的に思考する「推論能力」を十分に測定できていない。この課題を解決するため、研究チームは音声信号に基づいた複雑な推論を必要とする新しいベンチマーク「Audio Reasoning Tasks(ART)」を開発し、9つのカテゴリにわたる合計9,000個の評価サンプルを構築した。検証の結果、人間には極めて容易なこれらのタスクに対して、最新のマルチモーダルモデルであってもランダム回答に近い精度しか出せないケースが多く、音声理解における統合的な推論能力には依然として大きな乖離があることが判明した。
なぜこの問題か
マルチモーダル大規模言語モデル(MLLM)は、従来のテキストベースのモデルを拡張し、視覚や音声データを処理する能力を備えるよう進化してきた。視覚領域においては、高度な推論スキルを必要とする精緻なベンチマークが既に存在する一方で、音声領域の評価は依然として限定的であるという課題がある。現在の音声評価の主流は、音声認識(ASR)、音響シーン分類、音声キャプション生成といった特定の能力を個別にテストする手法に依存している。しかし、このような個別タスクでモデルが人間を超える性能を示したとしても、異なるカテゴリの音声タスクを組み合わせて推論を行う必要がある複雑な問題を解決できる保証はない。 特に懸念されるのは、多くのMLLMが、別々に事前学習されたテキストコンポーネントと音声コンポーネントを組み合わせて構築されているという現状である。このような構造では、音声信号の背後にある文脈や論理的な繋がりを理解する能力が不足する可能性がある。既存のベンチマークであるASR-GLUEなどは、テキストを音声に変換して頑健性を試すものであり、音声そのものに基づいた推論を評価する設計にはなっていない。…
核心:何を提案したのか
本研究では、マルチモーダルモデルが音声信号をどの程度論理的に処理できるかを評価するための新ベンチマーク「Audio Reasoning Tasks(ART)」を提案した。ARTの設計にあたっては、2つの重要なルールが設定されている。第一のルールは、単一の専門モジュール(例えば音声文字起こしのみを行うモジュール)の出力をテキストモデルに渡すだけでは解決できないタスクであること。これにより、単なる文字起こし以上の音声的特徴の理解が求められる。第二のルールは、専門的な訓練を受けていない人間であれば容易に解決できるタスクであること。これは、モデルの評価結果を人間が直感的に検証できるようにするためである。 ARTは、以下の9つのタスクカテゴリで構成されている。 1.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related