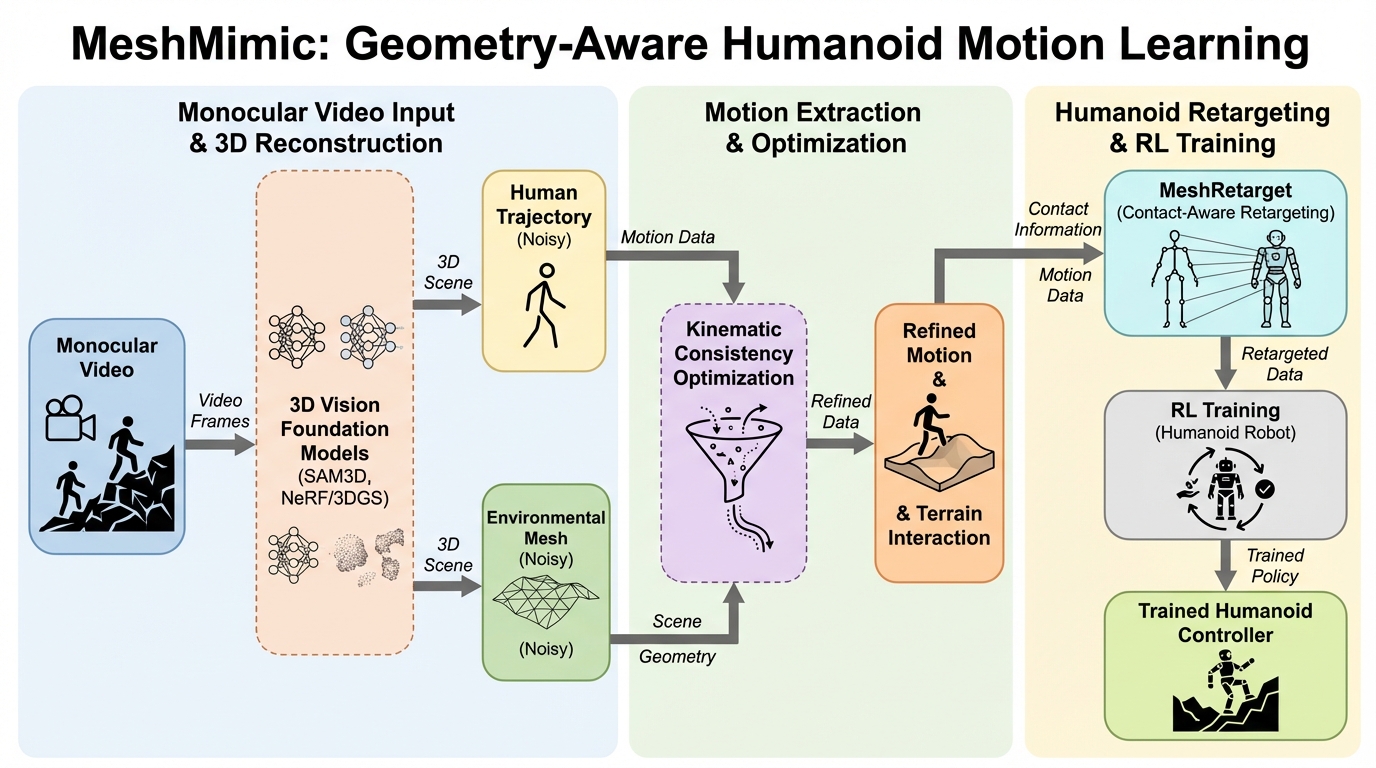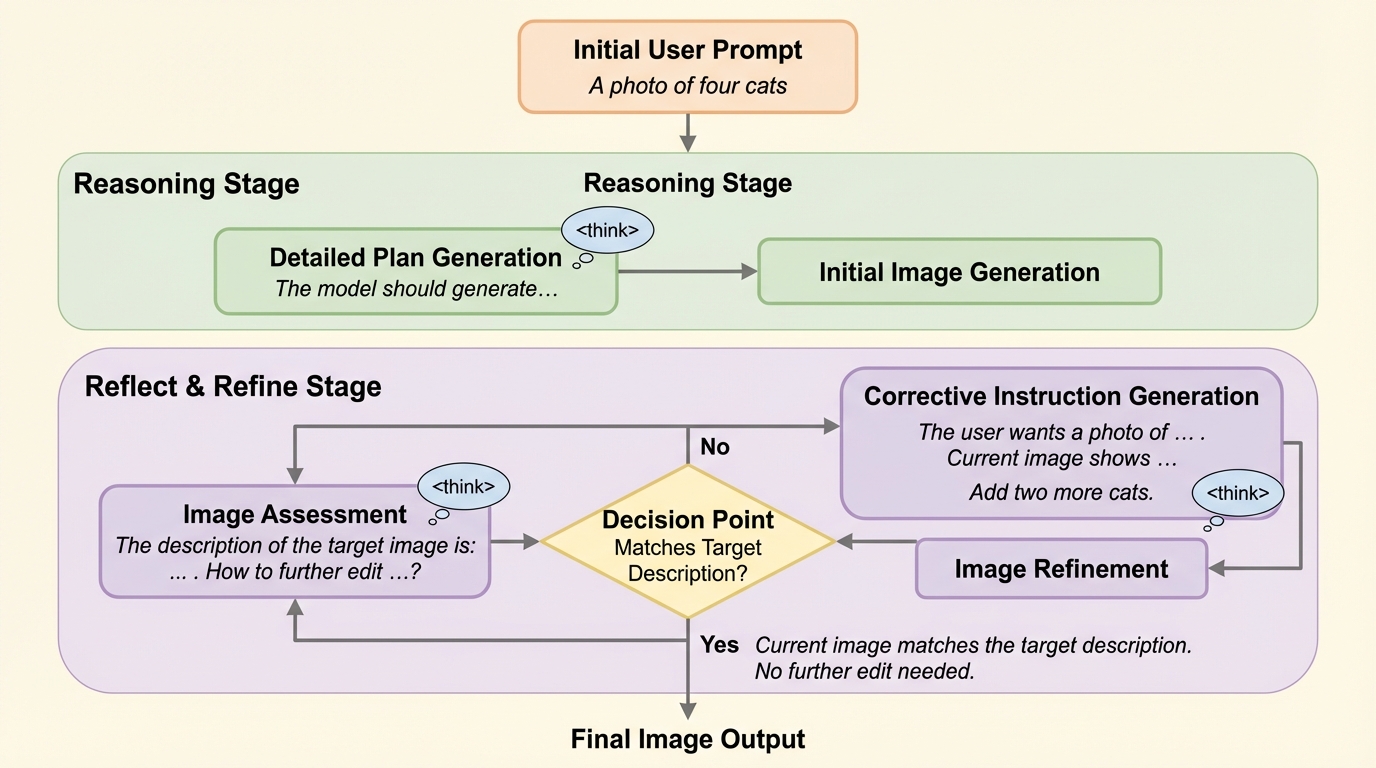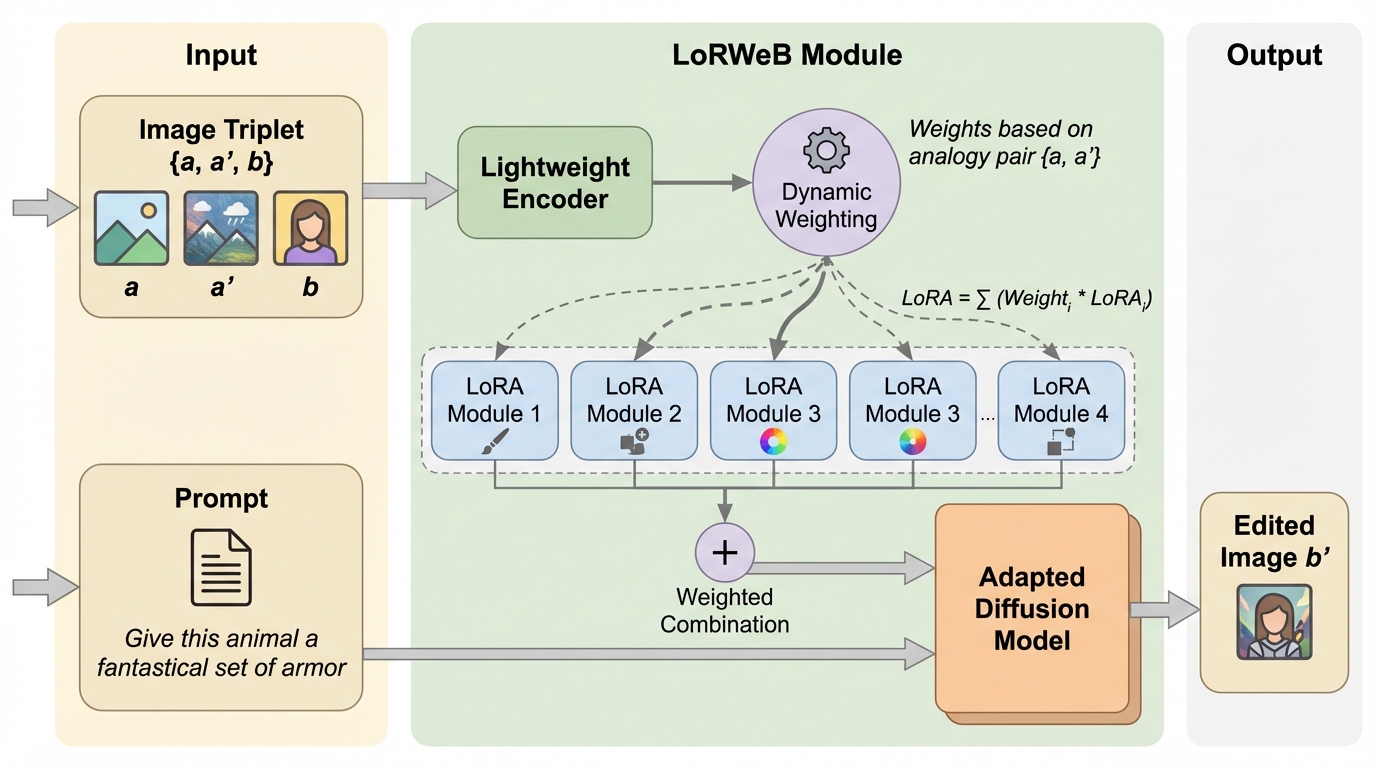
LoRAの重み基底で視覚アナロジー空間を張る:LoRWeBによる例示ベース画像編集
言葉では説明しにくい編集でも、見本の「前→後」画像から変換を読み取り別画像へ移す視覚アナロジーは有用ですが、単一のLoRAに多様な変換を詰め込む設計は未知の変換への一般化を妨げやすいです。 / LoRWeBは、複数のLoRAを「変換の部品」として学習可能な基底にしておき、入力された三つ組(a, a′, b)を手がかりに軽量エンコーダが混合係数を推定して、推論時に1つのMixed LoRAとして動的に合成して注入します。 / 包括的な評価により最先端の性能が示され、学習時に見ていない視覚変換への一般化も大きく改善したと報告されており、LoRAを基底分解して混ぜる方針が柔軟な例示ベース編集に有望だと示唆されます。