Pinterestにおける意思決定品質評価フレームワーク
Pinterestは、コンテンツ安全性ポリシーに基づく人手とLLMのモデレーション判断を、主観ではなく再現可能なデータと指標で継続評価する枠組みを提示しています。 / 中心は、SMEがキュレーションして作る高信頼のGolden Set(GDS)を「正解基準」として固定し、propensity scoreを用いた自動サンプリングで限られたSMEコストをカバレッジ拡張に集中させる設計です。 / この基盤により、複数エージェントの比較、プロンプト最適化の反復、ポリシーの版管理、prevalence指標の継続検証を同じ評価サイクルに載せ、判断品質の劣化や分布変化を見える化できます。
TL;DR(結論)
- Pinterestは、コンテンツ安全性ポリシーに基づく人手とLLMのモデレーション判断を、主観ではなく再現可能なデータと指標で継続評価する枠組みを提示しています。
- 中心は、SMEがキュレーションして作る高信頼のGolden Set(GDS)を「正解基準」として固定し、propensity scoreを用いた自動サンプリングで限られたSMEコストをカバレッジ拡張に集中させる設計です。
- この基盤により、複数エージェントの比較、プロンプト最適化の反復、ポリシーの版管理、prevalence指標の継続検証を同じ評価サイクルに載せ、判断品質の劣化や分布変化を見える化できます。
なぜこの問題か
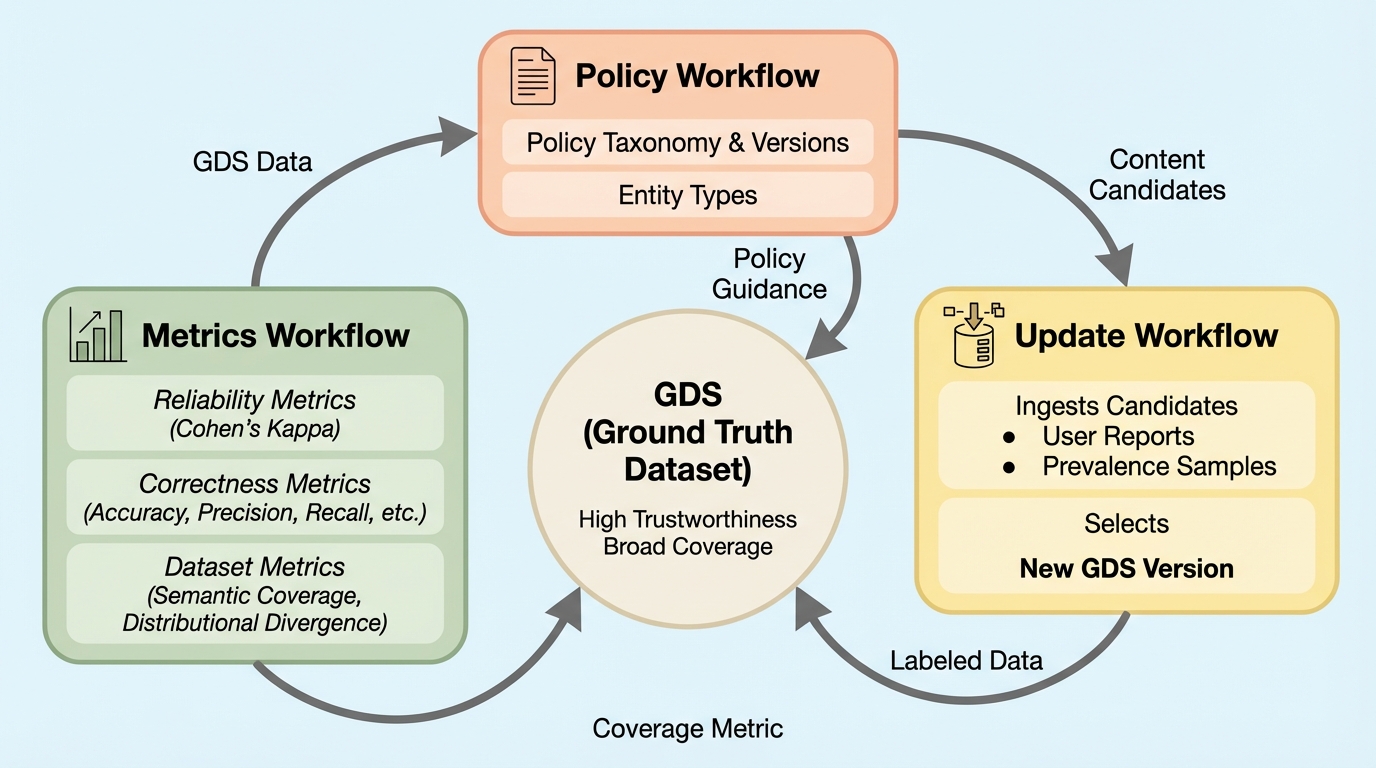
オンラインプラットフォームがコンテンツ安全性ポリシーを大規模に執行するには、機械学習モデル、スケーラブルな人手ラベリング、そしてLLMを組み合わせた運用が必要になります。ここで致命的になりやすいのが、「判断が正しいか」を測る評価の不安定さです。ポリシーは曖昧さや複雑さを含みやすく、人手でも自動でも解釈の揺れが起き、同じ対象でも異なる結論になり得ます。さらに、ポリシーは運用しながら更新されるため、いつの版の解釈で付けたラベルなのかが曖昧になると、経時比較自体が崩れます。加えて、問題となるコンテンツが極端に希少である点も評価を難しくします。ランダムに集めたデータでは重要なエッジケースが十分に入らず、オフライン評価で良く見えても本番で崩れる状況が起き得ます。 論文はこの状況を、信頼性とスケールのトレードオフとして「Pyramid of Truth」に整理しています。頂点のSMEは最も信頼できる一方で高コストかつ供給が限られ、底辺のスケーラブルなエージェント(大規模な人手チーム、LLM、MLモデルなど)は量を出せても信頼性が下がります。…
核心:何を提案したのか
論文が提示するのは、Pinterestで開発・展開したDecision Quality Evaluation Frameworkです。中核の発想は、正解を統計的推定に委ねるのではなく、SMEが「安定した正解基準」となるデータセットを明示的にキュレーションして固定する点にあります。この役割を担うのがGolden Set(GDS)であり、SMEが作成・裁定した高信頼ラベル群として、他のあらゆる判断主体(スケーラブルな人手チーム、LLM、MLモデルなど)を同一基準で評価するベンチマークになります。 ただしGDSは高コストで大規模化しにくいため、フレームワークは「どのデータをSMEに回すとカバレッジが最も伸びるか」を自動で選ぶ仕組みも含みます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related