理解と生成の両立はなぜ難しいのか:マルチモーダルモデルの最適化ジレンマに対するReason-Reflect-Refine(R3)。
マルチモーダルモデルは、画像の「生成」を伸ばすと「理解」が落ちたり、その逆が起きたりする同時改善の難しさがあり、原因として学習目標の違いがモデル容量の競合を生みうる点が整理されています。 / この論文は単発の画像生成を、意図を推論して下書きを作り、出来栄えを自己評価し、修正指示で編集していく多段の手続きへ組み替えるReason-Reflect-Refine(R3)を提案しています。 / 最終画像の品質に基づく結果志向の報酬で一連のループを学習させ、GenEval++で生成指示追従を強化しつつ、生成内容に結び付いた理解評価(例としてカウントなど)も改善したと報告されています。
TL;DR(結論)
- マルチモーダルモデルは、画像の「生成」を伸ばすと「理解」が落ちたり、その逆が起きたりする同時改善の難しさがあり、原因として学習目標の違いがモデル容量の競合を生みうる点が整理されています。
- この論文は単発の画像生成を、意図を推論して下書きを作り、出来栄えを自己評価し、修正指示で編集していく多段の手続きへ組み替えるReason-Reflect-Refine(R3)を提案しています。
- 最終画像の品質に基づく結果志向の報酬で一連のループを学習させ、GenEval++で生成指示追従を強化しつつ、生成内容に結び付いた理解評価(例としてカウントなど)も改善したと報告されています。
なぜこの問題か
統一的なマルチモーダルモデルには、画像を見て理解するだけでなく、指示に従って画像を生成する能力も同時に期待されています。ところが近年の大規模マルチモーダル学習では、理解と生成が同時に伸びにくいというジレンマが中心課題として扱われています。論文では例として、高忠実度の画像合成に寄せたモデルは、物体数のカウントや空間的推論のように精密さが必要な視覚理解タスクで苦戦しやすい点が挙げられています。逆方向として、視覚質問応答(VQA)や密なキャプション付けのような理解中心タスクに最適化したモデルは、生成中心のモデルに比べて創造的な生成性能が弱くなりやすいとも述べられています。 この緊張関係を解く既存の方向性としては、タスクごとに別々のトークナイザが必要だという見方から統一トークン化を進める流れや、理解と生成に別々の容量を割り当てる新しいアーキテクチャ設計が紹介されています。ただし本論文は、部分的な成功がありつつも根本原因は学習目標の違いにあると主張しています。生成の目標はデータ分布下のサンプル尤度最大化になりやすく、理解が弱くても最適化自体は進んでしまうためです。…
核心:何を提案したのか
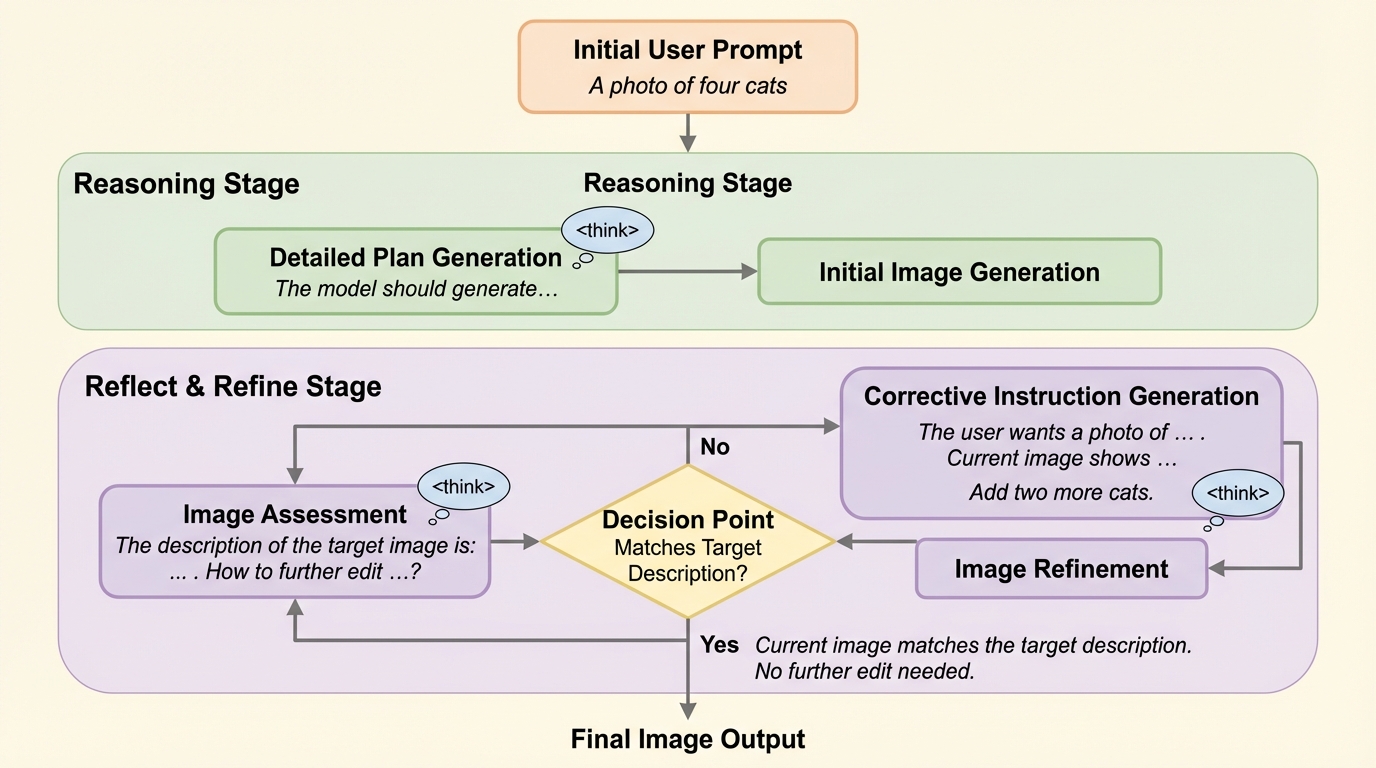
提案はReason-Reflect-Refine(R3)という枠組みで、単発の生成を「生成して理解し、再生成する」多段過程へ再定式化します。重要なのは、理解と生成を別々の目的として並列に最適化するのではなく、生成ループの内部に理解を明示的に組み込む点です。具体的には、まずユーザーの要求を推論して目標像を言語的に具体化し、その計画に沿って初期画像を作ります。次に、その画像が要求を満たしているかをモデル自身が点検し、足りない場合はどこがずれているかを言語化して編集指示を作ります。最後に、その編集指示に基づいて画像を編集し、より良い結果へ更新します。 この設計により、理解は「生成結果を後から採点する」受動的な役割ではなく、「次の生成をどう直すかを決める」能動的な構成要素になります。論文ではこの段階分離を、画家が構想を立て、自己評価し、手直しを重ねる制作過程になぞらえています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related