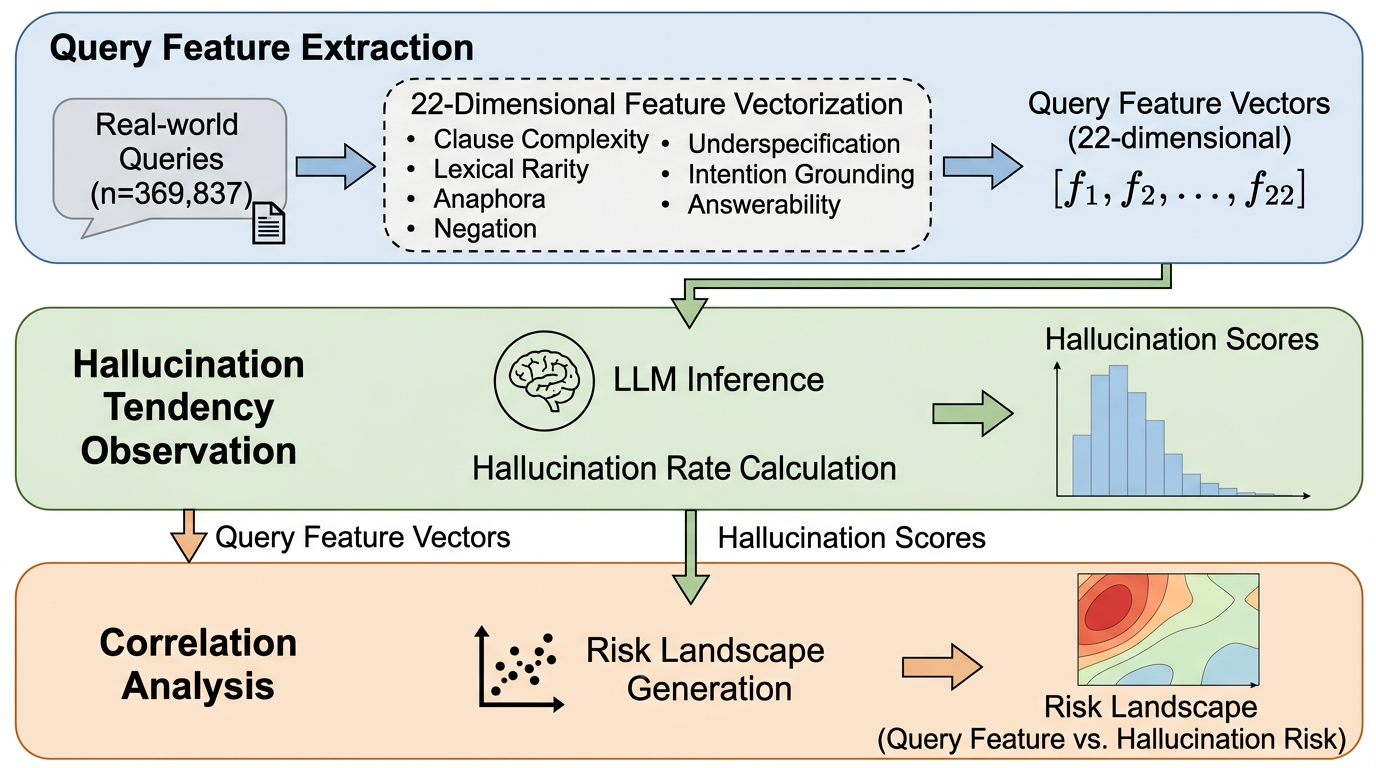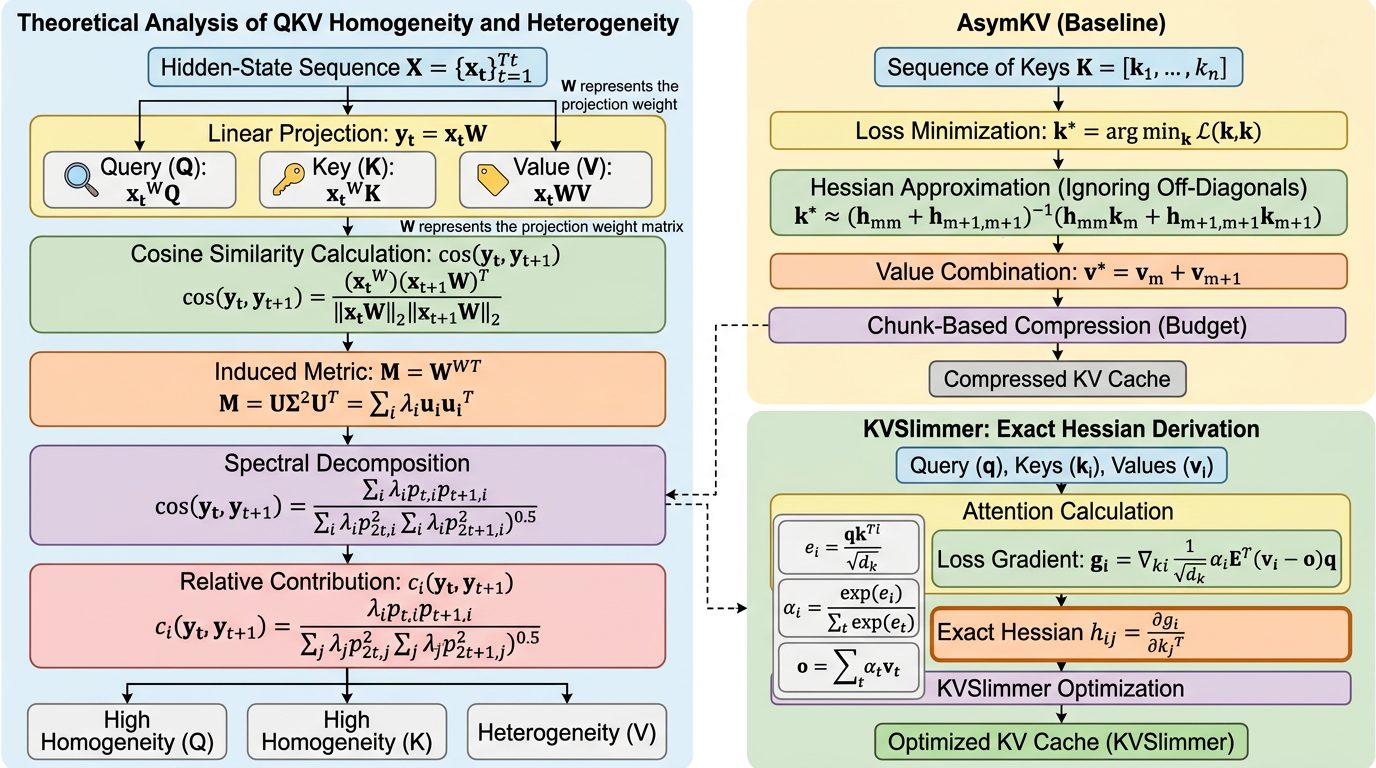
KVSlimmer:非対称KVマージを理論化し、長文脈推論のメモリ負荷を下げる
KVSlimmer は、KV キャッシュ圧縮で経験則として語られてきた「Key は似やすく、Value は似にくい」という非対称性を、投影重みのスペクトルエネルギー分布から理論的に説明し、その性質に沿って圧縮を行う手法です。 既存法のような勾配ベース近似ではなく、前向き計算だけから exact Hessian を扱える閉形式へ落とし込み、gradient-free でメモリ効率と速度の両方を改善します。 Llama3.1-8B-Instruct では LongBench 平均を 0.92 改善しつつ、メモリ 29%、レイテンシ 28% を削減しており、KV キャッシュ削減が「安くなる代わりに性能が落ちる」という固定観念をかなり崩しています。