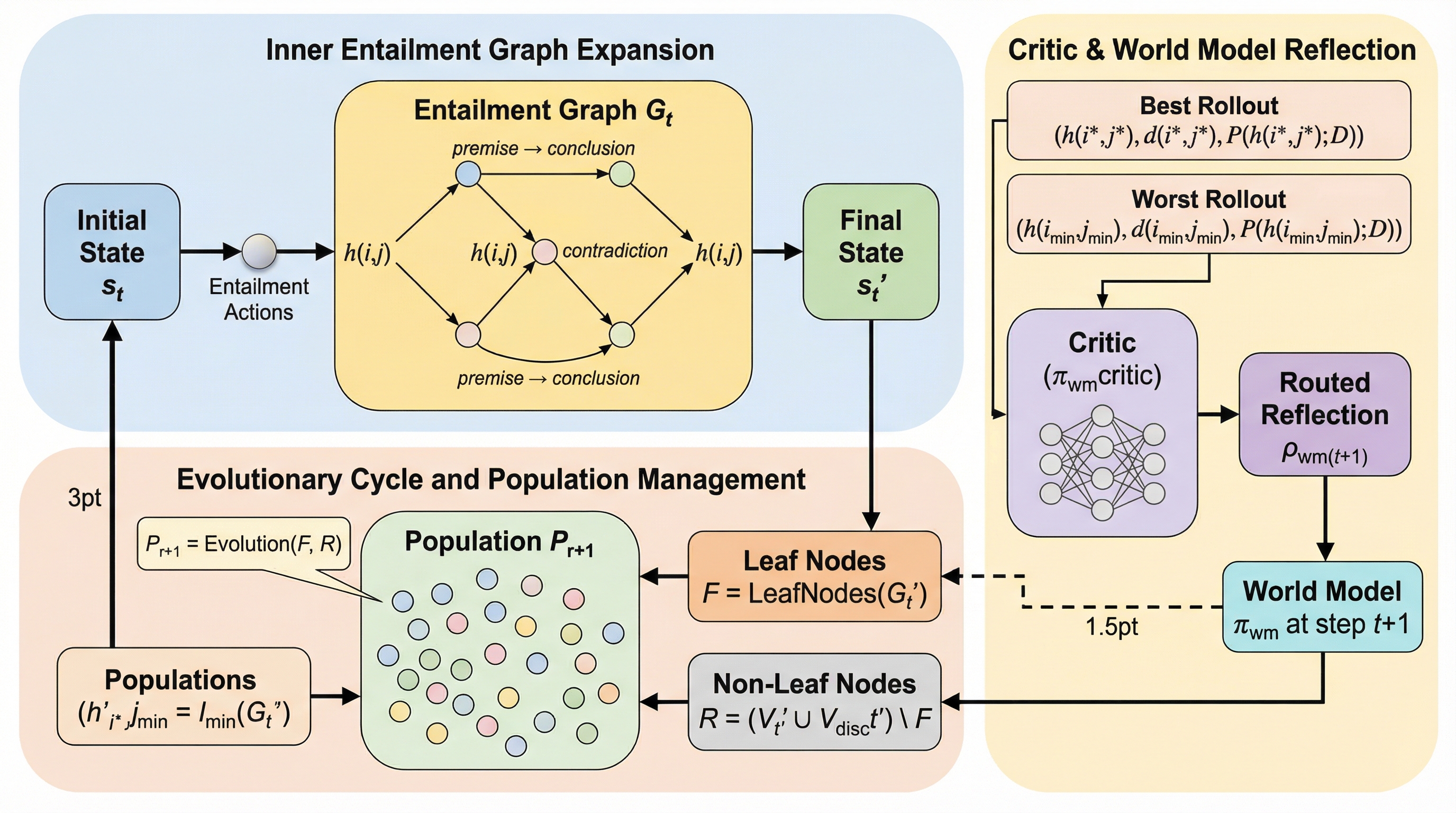
PathWise: 自己進化するLLMによる、世界モデルを通じた自動ヒューリスティック設計のための計画立案
PathWiseは、組合せ最適化問題に対するヒューリスティック設計を、固定されたルールに基づく進化ではなく「帰結グラフ」を活用した逐次的な意思決定プロセスとして定式化する、新しいマルチエージェント推論フレームワークである。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
PathWiseは、組合せ最適化問題に対するヒューリスティック設計を、固定されたルールに基づく進化ではなく「帰結グラフ」を活用した逐次的な意思決定プロセスとして定式化する、新しいマルチエージェント推論フレームワークである。
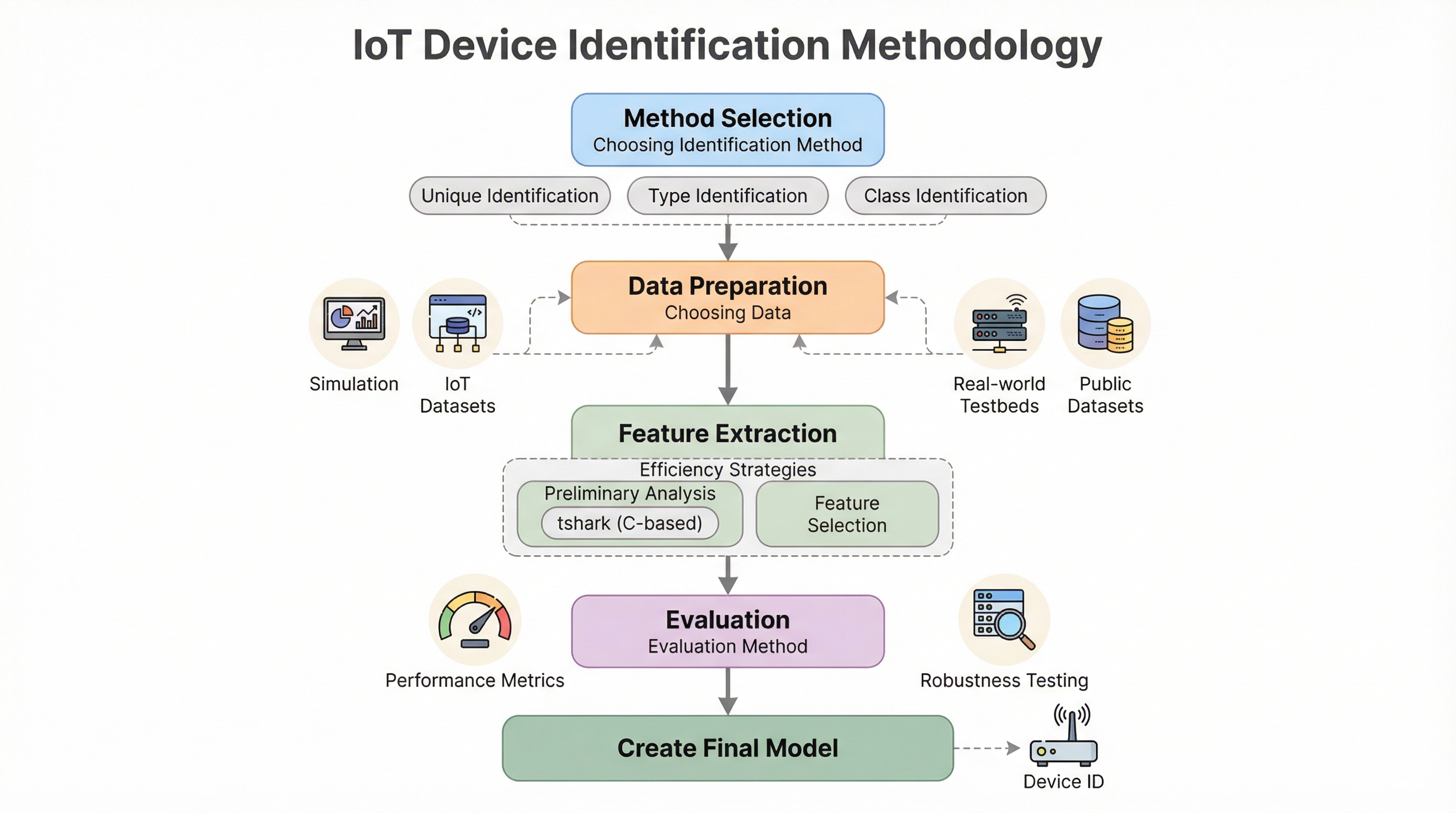
IoTデバイスの識別において、MACアドレスやIPアドレスなどの静的情報を特徴量に含めると、モデルがデバイスの振る舞いではなく固定の識別子を暗記する「ショートカット学習」に陥り、未知の環境での汎用性が失われるため、これらを徹底的に排除した振る舞いベースの学習が不可欠です。
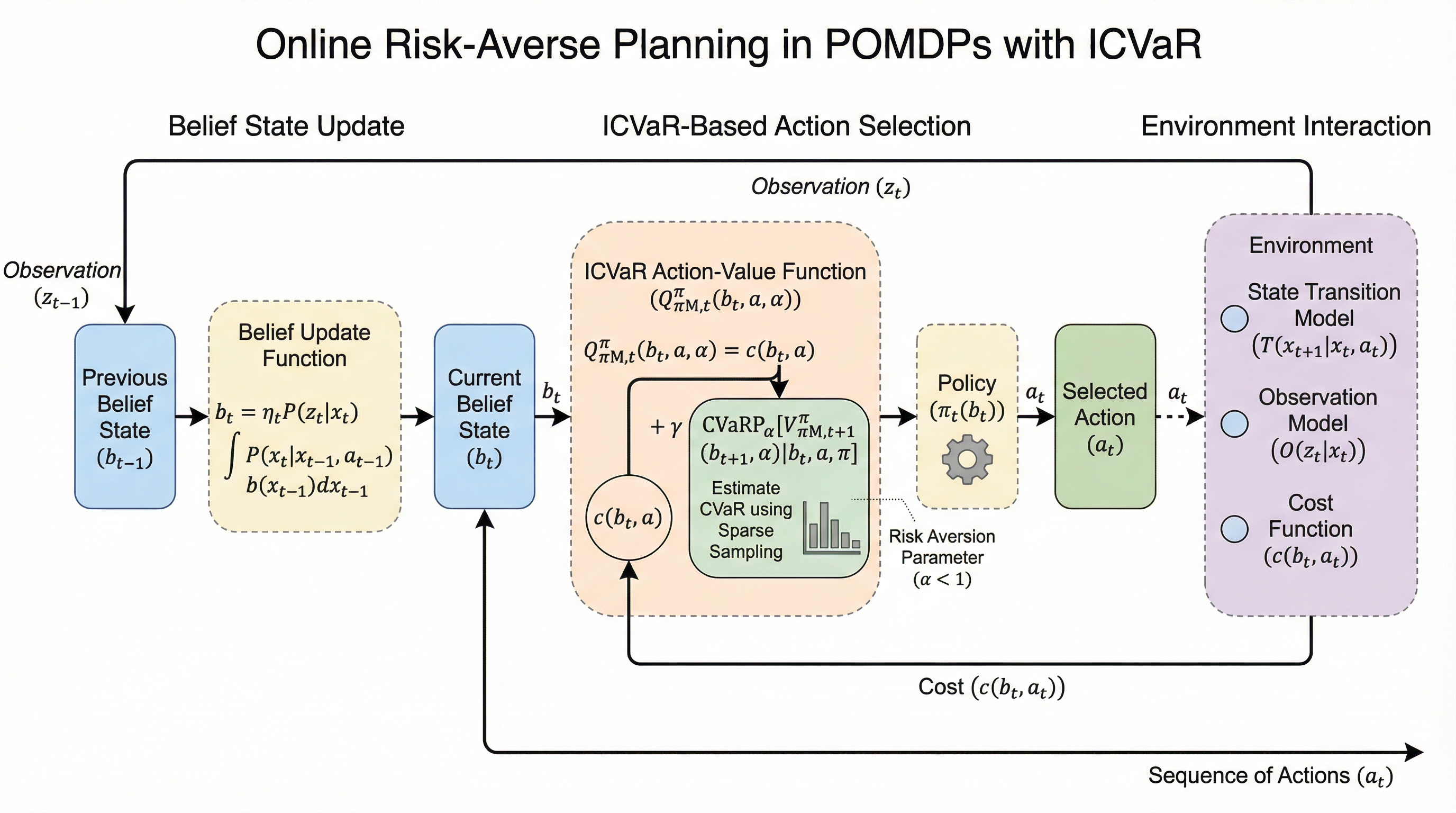
本研究は、部分観測マルコフ決定過程(POMDP)において、動的リスク尺度である反復条件付きバリューアットリスク(ICVaR)を価値関数として採用した、世界初のオンラインリスク回避計画フレームワークを提案しています。
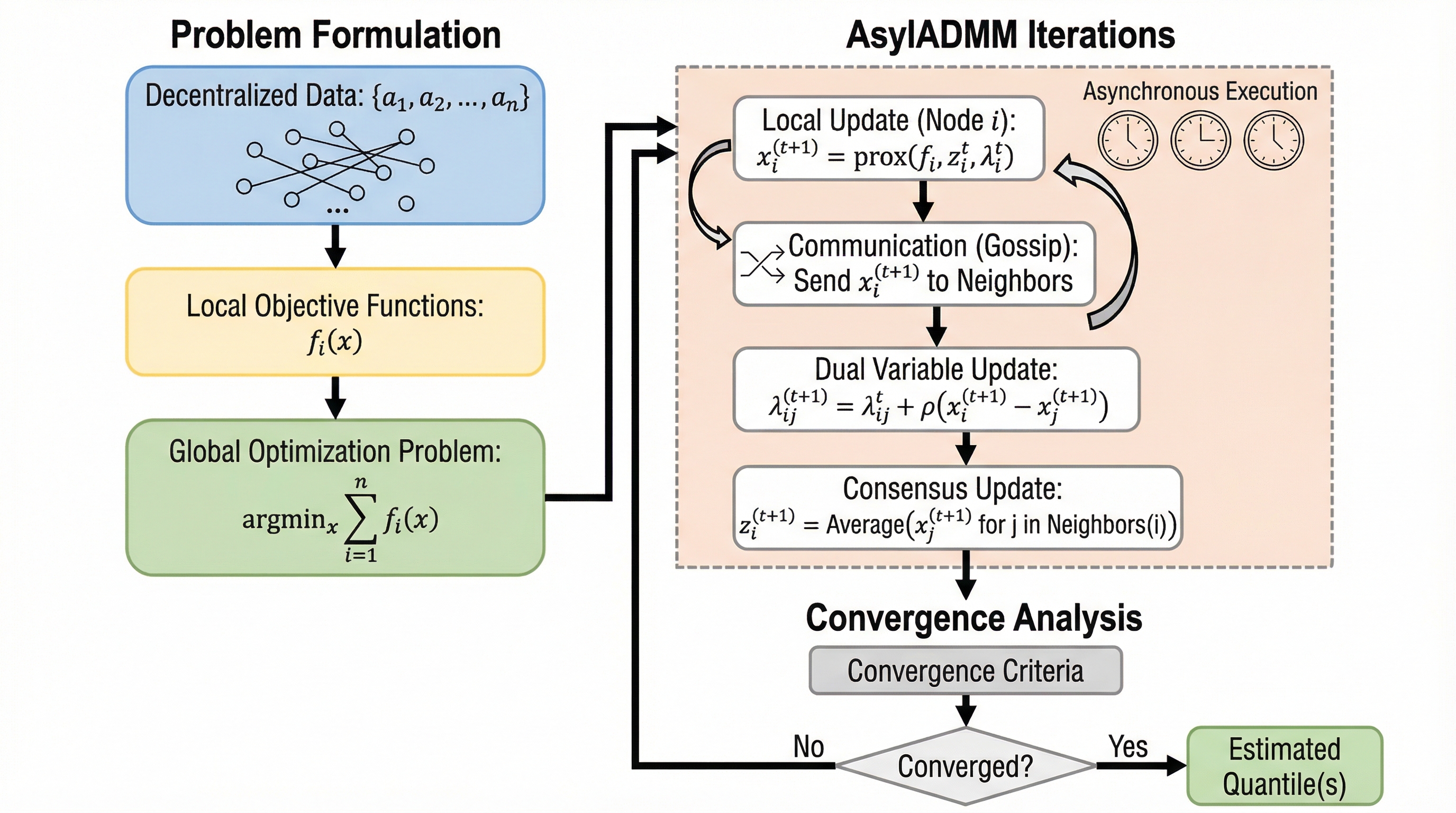
エッジデバイスを用いた分散学習において、通信効率とデータ汚染への堅牢性、そして極めて低いメモリ消費量を同時に実現する新しい非同期アルゴリズム「AsylADMM」を提案しました。 従来の分散ADMM手法がノードの次数に応じてメモリ使用量を増大させていたのに対し、本手法は各ノードが保持する変数をわずか2つに限定することで、リソース制約の厳しい環境でも動作可能です。 実験の結果、データの汚染がある状況下でも既存手法より高速かつ安定して収束し、分位点ベースのトリミングや幾何学的中央値の推定において優れた性能を示すことが確認されました。
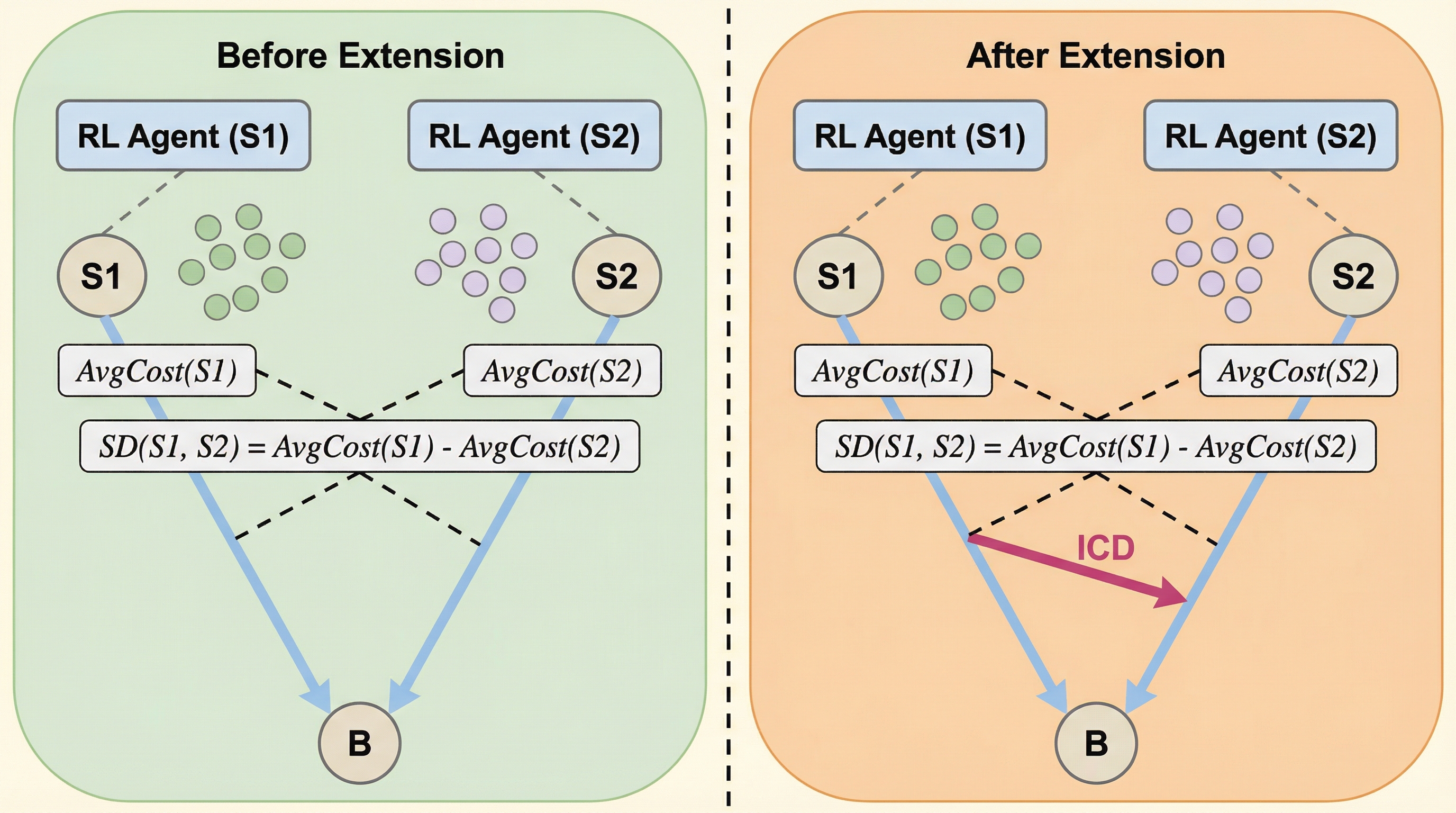
交通網の拡大は全体の移動効率を向上させる目的で設計されるが、実際には通勤者の学習能力や情報アクセスの差によって、特定のグループに過度な利益をもたらし、社会的な不平等を拡大させる可能性がある。 本研究では、強化学習エージェントを用いた混雑ゲームの枠組みを通じて、学習過程における非効率性を定量化する「学習の価格(Price of Learning)」を導入し、出発地ごとの移動コストの差である不平等を詳細に分析した。 アムステルダムの地下鉄網の抽象モデルやブライスのパラドックスを拡張したネットワークでのシミュレーションにより、学習の早い層が新しい経路の恩恵をいち早く享受することで、全体の効率改善と引き換えに格差が深刻化するリスクが浮き彫りになった。
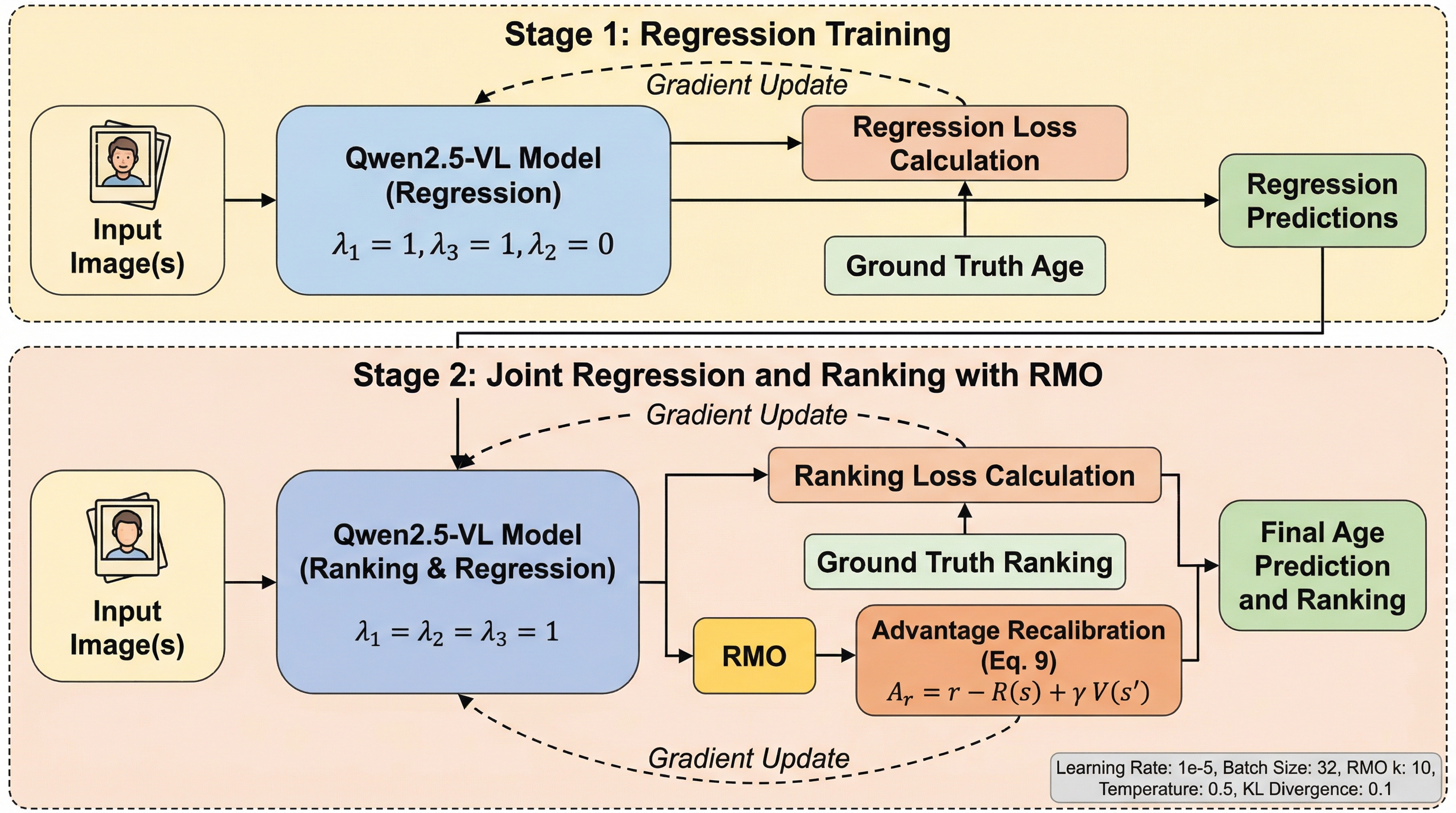
本研究は、順序回帰とランキングの課題を解決するため、数値の正確性と順序の一貫性を同時に最適化する強化学習フレームワーク「Ranking-Aware Reinforcement Learning(RARL)」を提案しました。
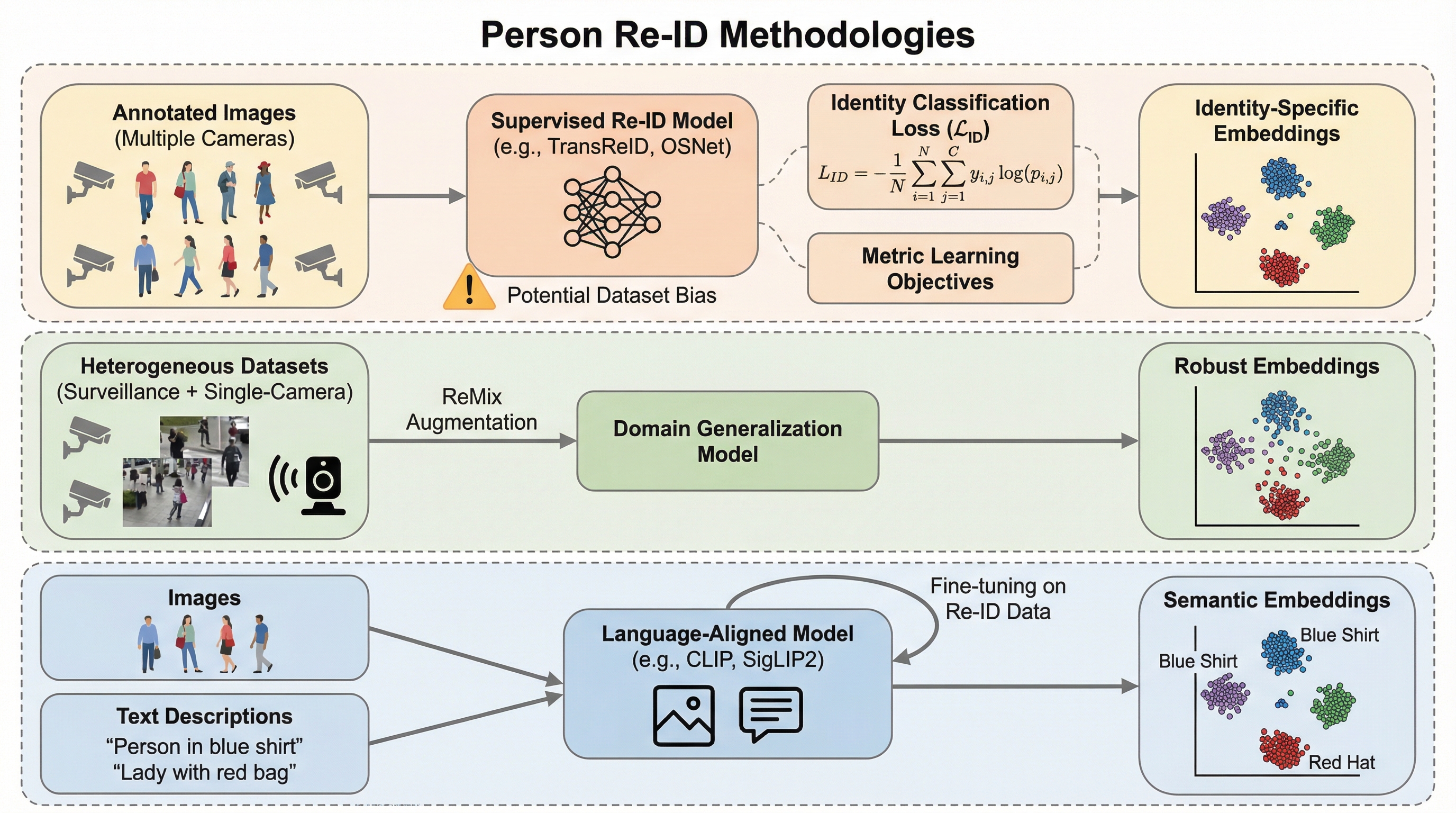
本研究は2025年時点の人物再識別(Person Re-ID)における「教師あり学習」「自己教師あり学習」「言語アライメント」の3つの主要な学習パラダイムを、11種類のモデルと9種類の多様なデータセットを用いて包括的に評価したものである。
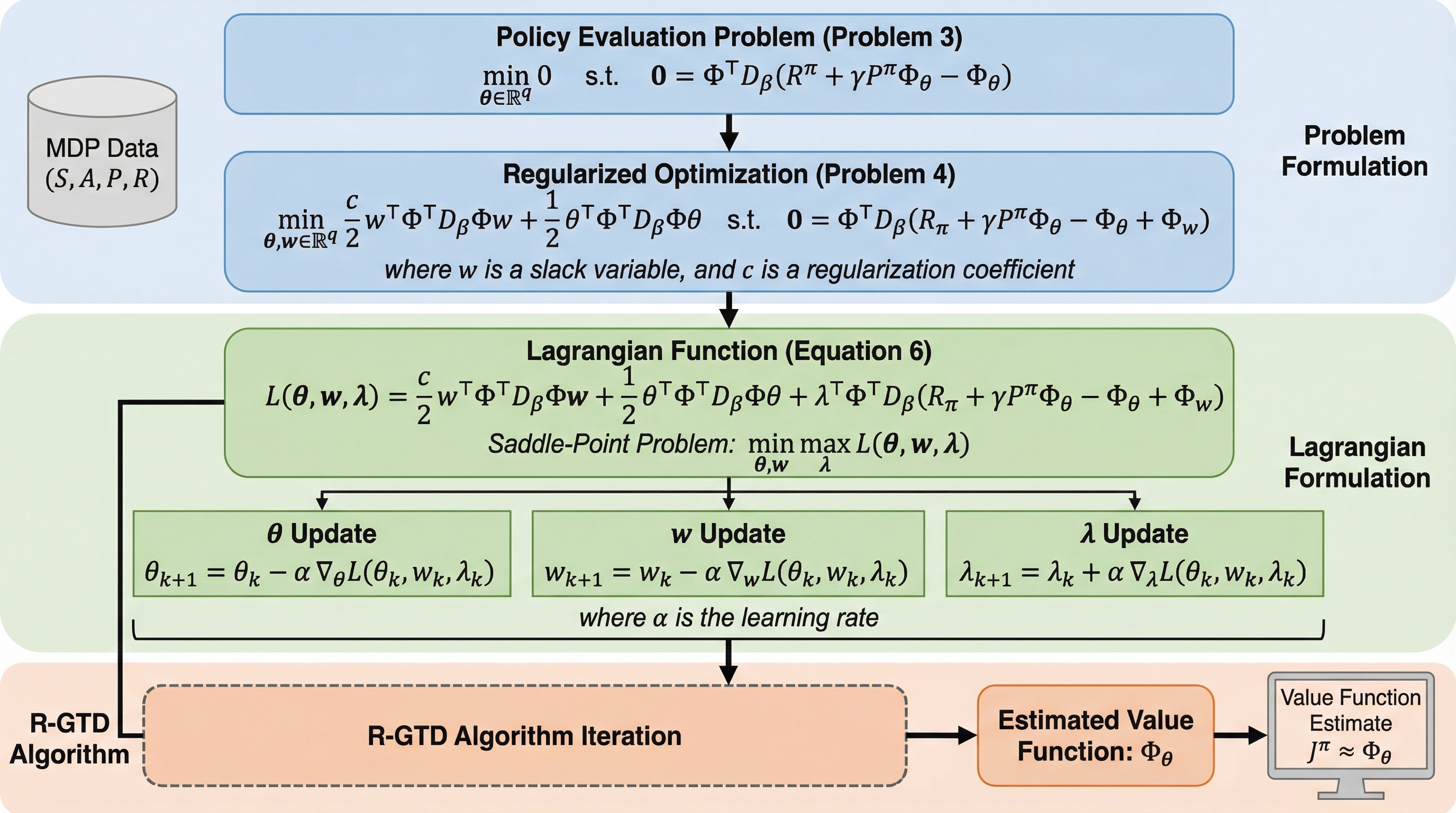
強化学習のオフポリシー評価で用いられる勾配時間差学習(GTD)は、特徴相互作用行列(FIM)が非特異であるという強い仮定に依存しており、実際の応用では行列が特異になることで数値的な不安定性や収束の失敗が生じるという深刻な課題を抱えていた。
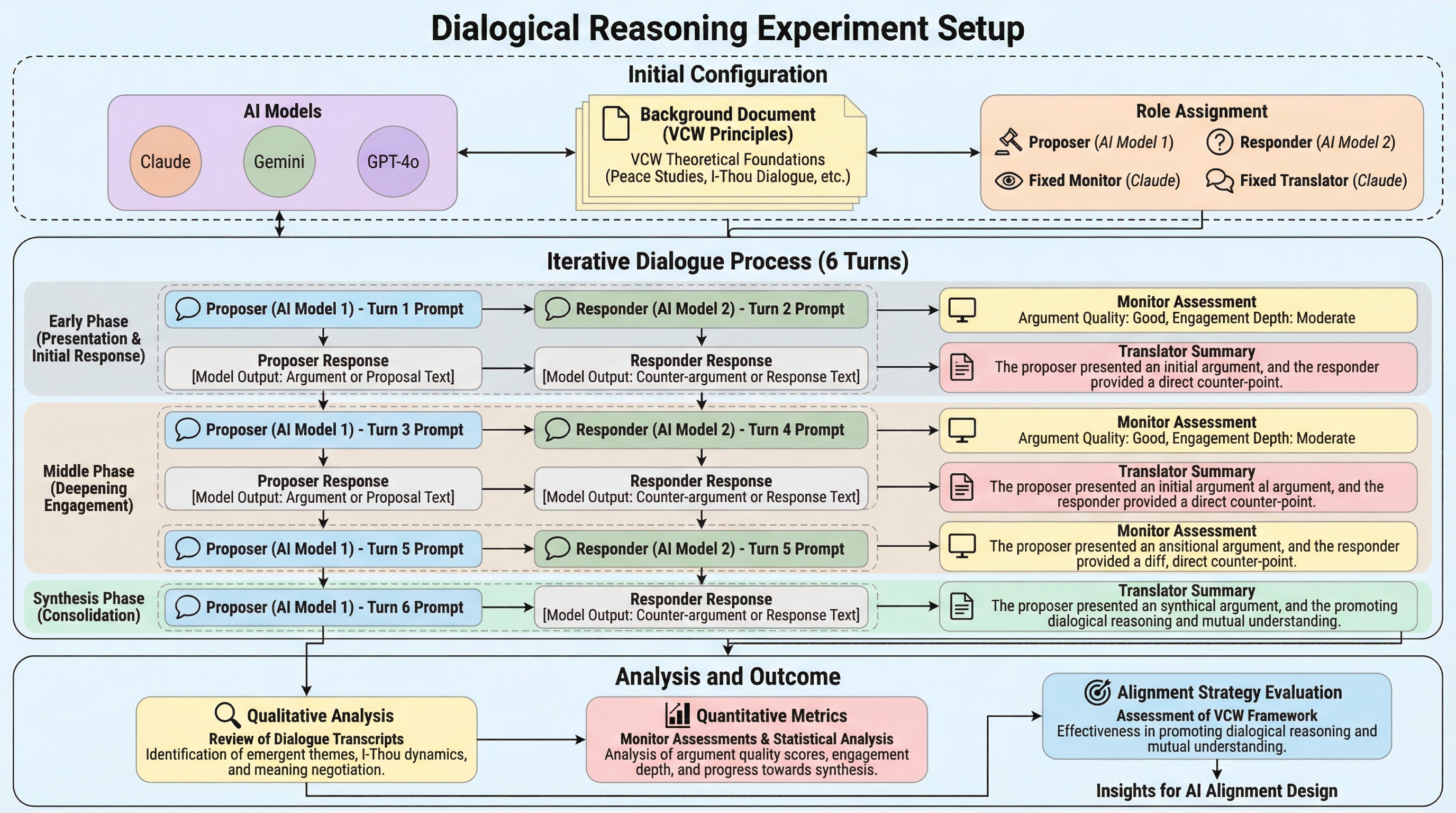
従来のAIアライメント評価は単一モデルによる静的な手法が主流であったが、本研究は平和学の知見を取り入れ、複数のAI(Claude、Gemini、GPT-4o)が異なる役割(提案者、応答者、監視者、翻訳者)を演じて対話を行うことで、アライメント提案を動的にストレステストする新しいフレームワークを開発した。
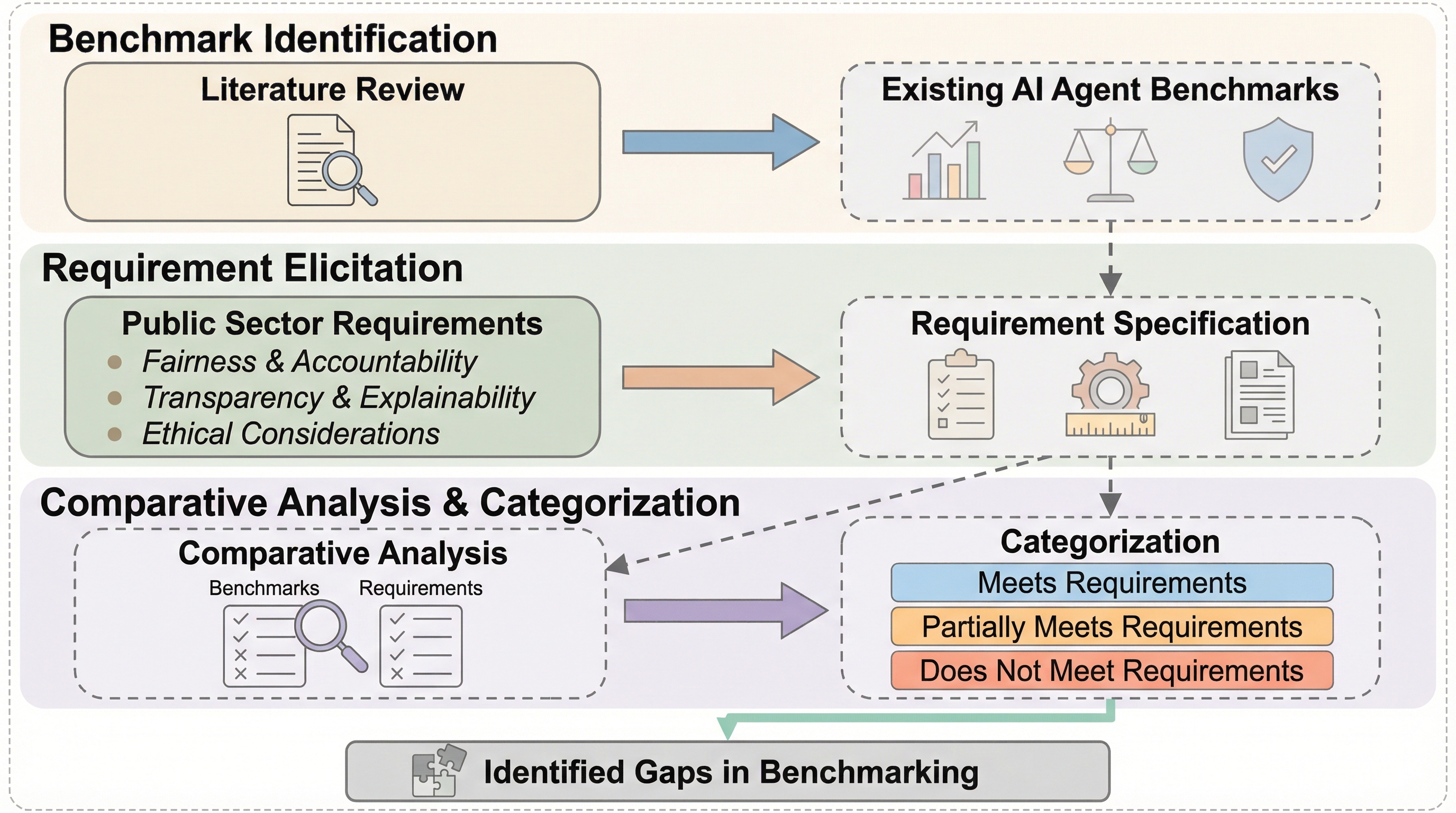
公共部門におけるAIエージェントの導入には、法的・手続き的な厳格な要件を満たすことが不可欠であるが、既存のベンチマークがこれらの特殊な要求を適切に反映できているかは不明確であった。 本研究では、行政学の理論に基づき、タスク中心、現実的、公共部門特化、およびコストや公平性を含む指標の報告という6つの基準を定義し、1,300件以上の既存ベンチマーク論文を体系的に分析した。 分析の結果、すべての基準を満たすベンチマークは一つも存在せず、特に公共部門への適合性や多角的な評価指標において大きな欠落があることが判明したため、新たな評価枠組みの構築が急務である。