正則化勾配時間差学習
強化学習のオフポリシー評価で用いられる勾配時間差学習(GTD)は、特徴相互作用行列(FIM)が非特異であるという強い仮定に依存しており、実際の応用では行列が特異になることで数値的な不安定性や収束の失敗が生じるという深刻な課題を抱えていた。
TL;DR(結論)
強化学習のオフポリシー評価で用いられる勾配時間差学習(GTD)は、特徴相互作用行列(FIM)が非特異であるという強い仮定に依存しており、実際の応用では行列が特異になることで数値的な不安定性や収束の失敗が生じるという深刻な課題を抱えていた。 本研究が提案する正則化勾配時間差学習(R-GTD)は、平均二乗射影ベルマン誤差(MSPBE)の最小化問題を、正則化項と補助変数を導入した新たな凸凹サドルポイント問題として再定義することで、行列が特異な状況下でも一意の解への収束を理論的に保証する。 実験の結果、従来のGTD2が不安定になり収束に失敗するような特異な設定においても、R-GTDは極めて安定した挙動を示し、明示的な誤差境界内で正確な価値関数推定を維持できることが確認され、特徴量の設計に左右されない堅牢な学習アルゴリズムの基盤が構築された。
なぜこの問題か
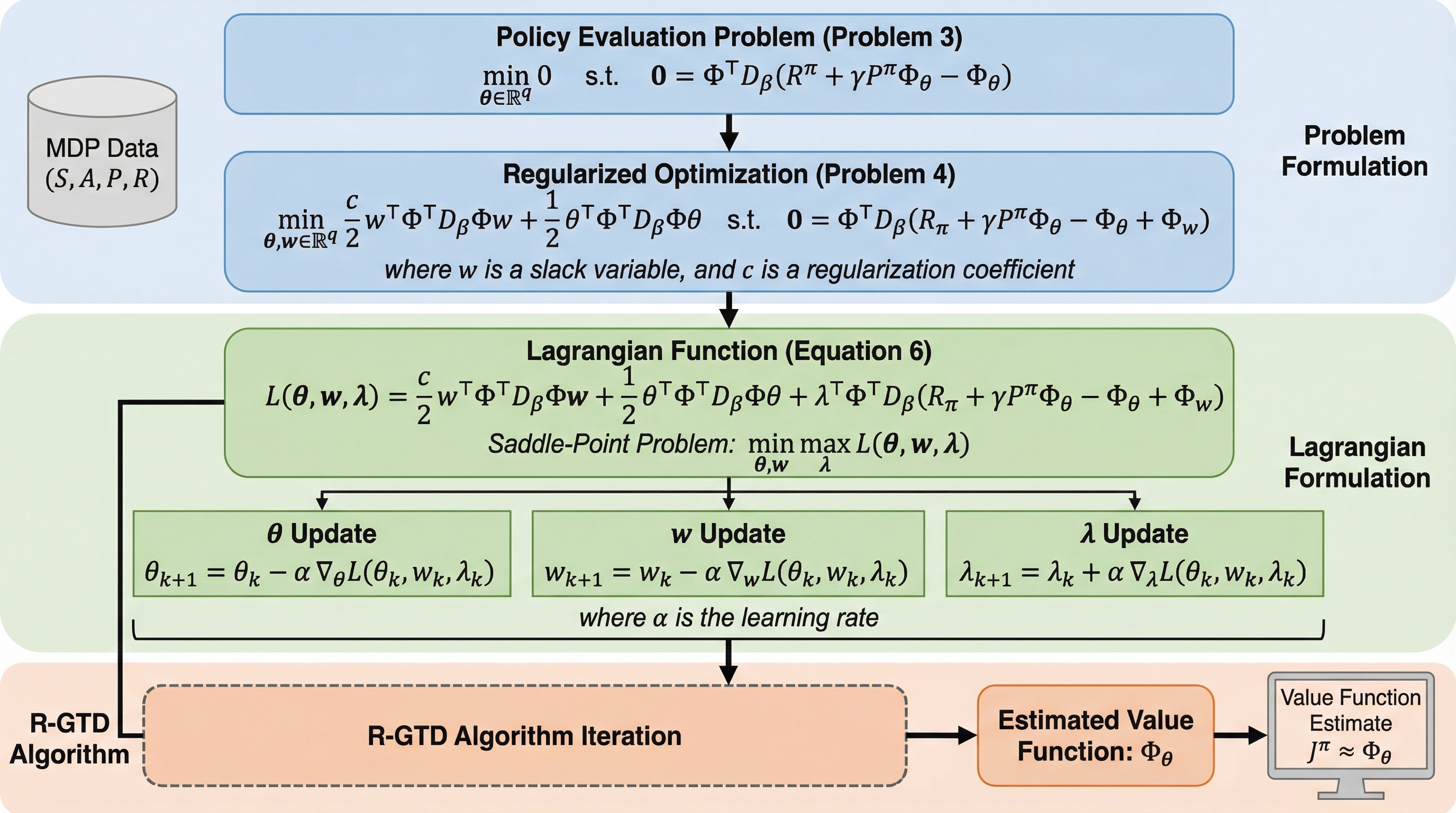
強化学習における方策評価は、エージェントが未知の環境で最適な意思決定を行うための基盤となる重要なプロセスである。その基礎的な手法として時間差学習(TD学習)が広く知られているが、関数近似、ブートストラップ、そしてオフポリシー学習を組み合わせる「死の三つ組(deadly triad)」と呼ばれる設定では、学習の不安定性や解の発散が生じることが大きな理論的・実用的課題となっていた。この不安定性を根本的に解決するために導入されたのが勾配時間差学習(GTD)であり、これは平均二乗ベルマン誤差(MSBE)の真の勾配を利用することで、線形関数近似を用いたオフポリシー学習における収束を可能にする画期的な手法であった。しかし、ベルマン演算子が価値関数を特徴空間の外側に写像する場合、MSBEの最小解でも残差が残るという限界があり、これに対処するために射影ベルマン方程式(PBE)を最小化するGTD2が提案された。 GTD2は平均二乗射影ベルマン誤差(MSPBE)を最小化することで、選択された特徴量で表現可能な範囲内で最も正確な近似を得ようとする。…
核心:何を提案したのか
本研究は、特徴相互作用行列(FIM)の非特異性の仮定を完全に取り除き、どのような条件下でも安定して動作する新しいアルゴリズム「正則化勾配時間差学習(R-GTD)」を提案している。R-GTDの核心的なアイデアは、従来のMSPBE最小化問題を、正則化項を含む制約付き最適化問題として再定義した点にある。具体的には、目的関数にパラメータの二次形式による正則化を導入し、さらに制約条件の中に補助変数(スラック変数)を組み込むことで、数学的な構造を根本から強化している。この補助変数は、射影ベルマン方程式における誤差を柔軟に吸収する役割を果たし、その誤差の大きさをペナルティ項によって制御する仕組みとなっている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related