順序ランキングのためのランキングを考慮した強化学習
本研究は、順序回帰とランキングの課題を解決するため、数値の正確性と順序の一貫性を同時に最適化する強化学習フレームワーク「Ranking-Aware Reinforcement Learning(RARL)」を提案しました。
TL;DR(結論)
本研究は、順序回帰とランキングの課題を解決するため、数値の正確性と順序の一貫性を同時に最適化する強化学習フレームワーク「Ranking-Aware Reinforcement Learning(RARL)」を提案しました。 検証可能な報酬関数を用いて回帰とランキングの相互改善を促すとともに、進化的戦略に基づく「Response Mutation Operations(RMO)」を導入することで、学習の停滞を防ぎ効率的な探索を実現しています。 顔写真の年齢推定、物体の計数、画像の美学評価の3つのベンチマークにおいて、従来の教師あり微調整を大幅に上回る性能を達成し、特に複数画像間での比較推論能力において顕著な向上を示しました。
なぜこの問題か
順序回帰とランキングは、信号処理や機械学習において極めて基本的かつ重要なタスクであり、医療信号の分析における疾患の重症度判定や、コンテンツの品質評価における音声や画像の美学評価など、幅広い実世界分野に応用されています。これらのタスクにおける最大の課題は、ラベルが持つ固有の順序依存性をモデルが正確に捉える必要がある点にあります。単なる数値の予測だけでなく、データ間の相対的な順序関係を維持することが求められるのです。しかし、従来の回帰モデルは個々のデータ点における誤差を最小化することに特化しており、データ間の順序構造を軽視する傾向があります。一方で、分類ベースの手法はラベルを離散化することで情報の粒度を失ってしまうという欠点があります。 また、既存のLearning-to-Rank(L2R)手法は相対的な順序に焦点を当てていますが、単一のフレームワーク内で回帰の正確性とランキングの一貫性の両方を同時に最適化することは困難でした。さらに、入力信号とその順序構造の間の因果関係を明示的にモデル化するメカニズムが欠如しており、モデルは正確な数値予測と一貫した順序維持の間のトレードオフを効果的に処理できていないという現状があります。…
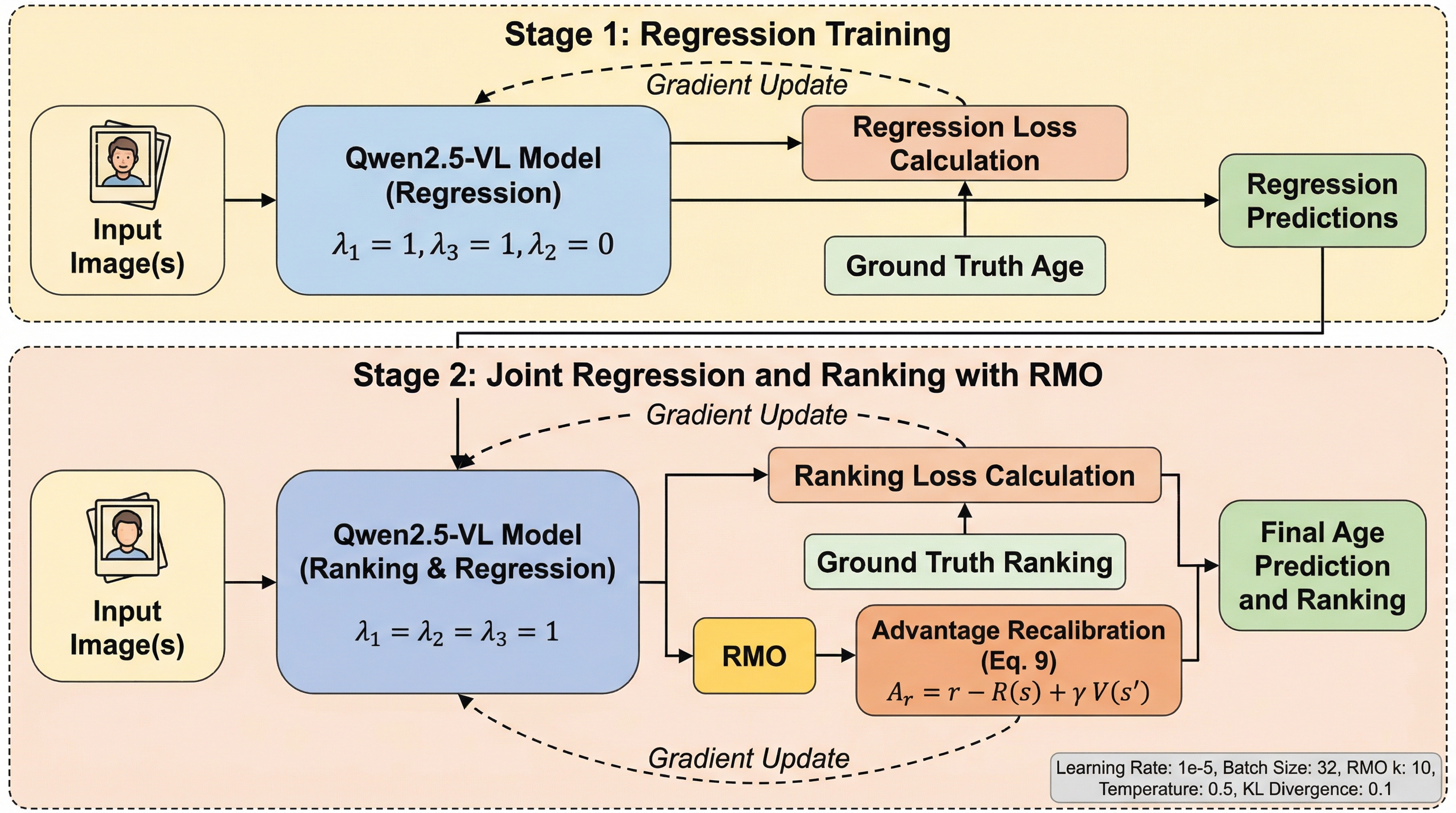
核心:何を提案したのか
本論文では、順序依存性を直接モデル化する新しい強化学習フレームワークとして「Ranking-Aware Reinforcement Learning(RARL)」を提案しています。これが本研究の核心的な貢献です。RARLの最大の特徴は、回帰タスクとランキングタスクを統合し、両者の間で相互に精度を高め合う「統一された目的関数」を備えている点にあります。このフレームワークは、学習済みの報酬モデルに依存するのではなく、回帰の精度とランキングの正確さを共同で評価する「検証可能な報酬(Verifiable Reward)」を採用しており、これにより報酬モデルのバイアスを排除しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related