機械学習を用いたIoTデバイス識別:よくある落とし穴とベストプラクティス
IoTデバイスの識別において、MACアドレスやIPアドレスなどの静的情報を特徴量に含めると、モデルがデバイスの振る舞いではなく固定の識別子を暗記する「ショートカット学習」に陥り、未知の環境での汎用性が失われるため、これらを徹底的に排除した振る舞いベースの学習が不可欠です。
TL;DR(結論)
IoTデバイスの識別において、MACアドレスやIPアドレスなどの静的情報を特徴量に含めると、モデルがデバイスの振る舞いではなく固定の識別子を暗記する「ショートカット学習」に陥り、未知の環境での汎用性が失われるため、これらを徹底的に排除した振る舞いベースの学習が不可欠です。 IoT環境特有の深刻なデータ不均衡に対応するため、全体の正解率(Accuracy)ではなく、通信量の少ないデバイスの性能を公平に評価できるマクロ平均F1スコアや混同行列を用いることで、特定のデバイスに対する識別失敗を可視化し、モデルの信頼性を確保する必要があります。 システムの拡張性を高めるために、全デバイスを一括分類する巨大なモデルを避けてデバイスごとにバイナリ分類器を構築するOne-vs-Rest(OvR)アプローチを採用し、さらに表形式データに対しては深層学習よりも決定木などの古典的な手法を優先して推論速度と説明可能性を両立させることが推奨されます。
なぜこの問題か
IoTデバイスはサイバー空間と物理的な世界を繋ぐ重要な架け橋であり、リモート管理や自動化を実現するための基盤となっています。しかし、その急速な普及に伴い、セキュリティ上の課題が極めて深刻化しています。IoTデバイスは、ハードウェア、オペレーティングシステム、通信インターフェースが極めて多岐にわたるため、従来のコンピュータ向けセキュリティソリューションをそのまま適用することが困難なほど異質です。多くのデバイスは標準的なユーザーインターフェースを持たず、バッテリー容量やプロセッサの処理能力といったリソースも限られているため、ユーザーが手動でセキュリティ設定を更新したり、必要な対策を講じたりすることが物理的に不可能な場合も少なくありません。 このような背景から、ネットワーク上の通信挙動からデバイスのブランドやモデルといった正体を推論する「IoTデバイス識別」という技術が、重要な防御手法として浮上しました。デバイスの正体を正確に特定できれば、それぞれの特性に応じた適切なセキュリティポリシーの適用、脆弱性に対する自動的なアップデート管理、あるいは異常な挙動を示すデバイスの迅速な隔離といった高度な管理戦略が可能になります。…
核心:何を提案したのか
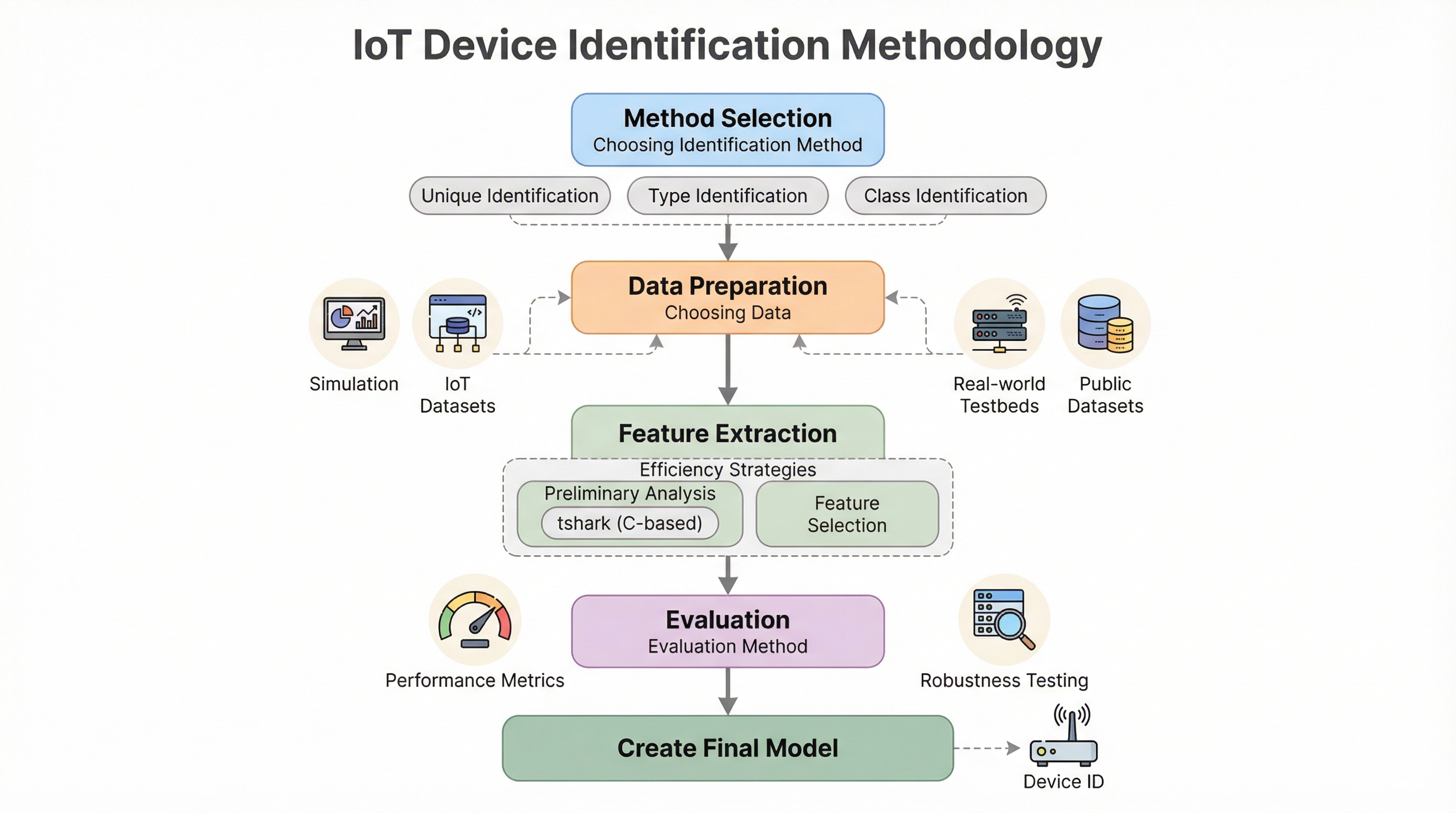
本研究では、IoTデバイスの識別プロセスを「手法の選択」「データの準備」「特徴量抽出」「評価」という4つの重要な段階に分解し、それぞれのステップで発生しやすいミスと、それを回避するための具体的な戦略を提案しています。まず、識別の粒度を「ユニーク識別(個体識別)」「タイプ識別(機種識別)」「クラス識別(機能群識別)」の3つのレベルに分類し、それぞれの目的と特徴量の選択が論理的に一致している必要があることを強調しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related