公共部門の要件を満たさないAIエージェントのベンチマーク
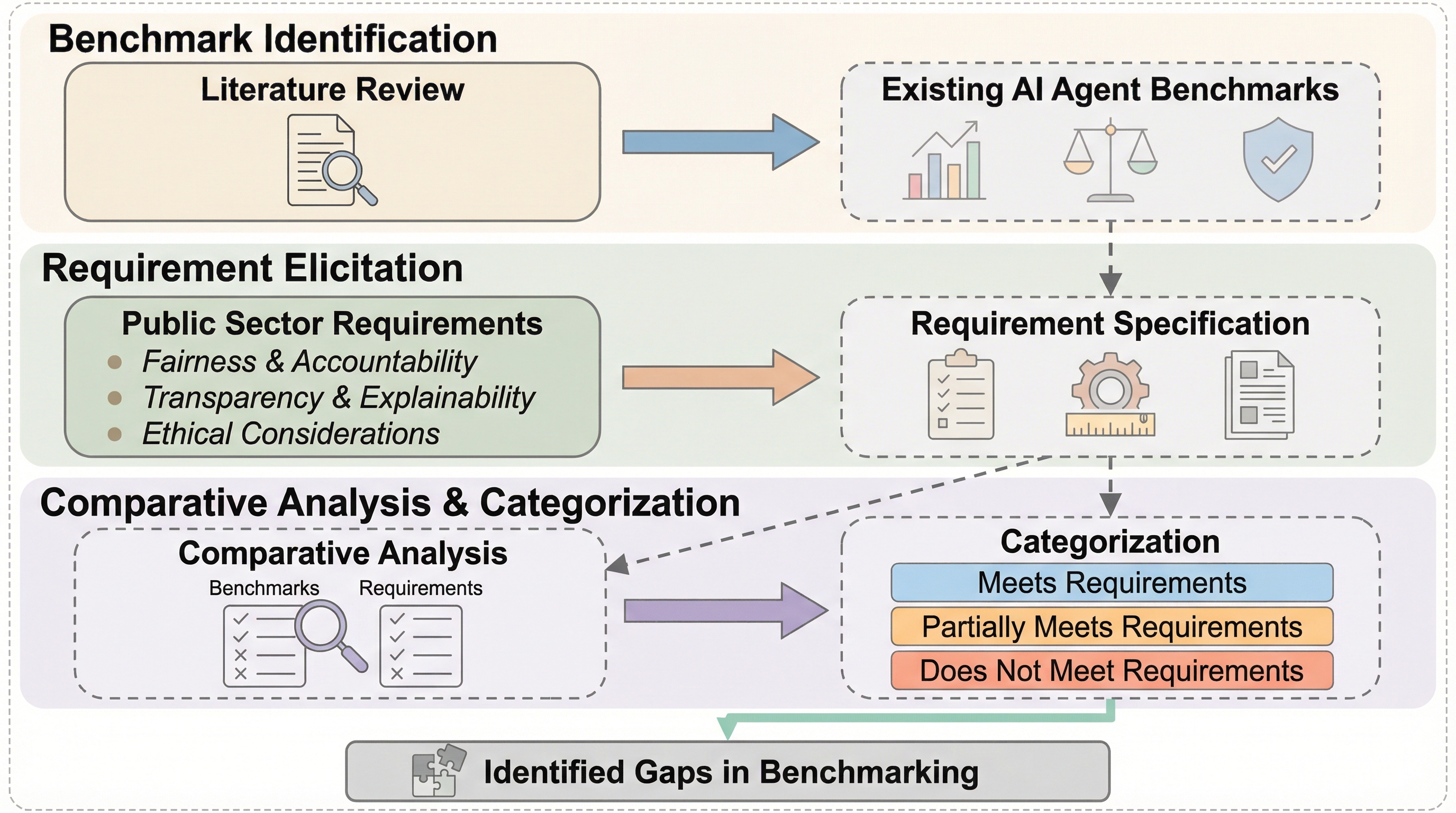
公共部門におけるAIエージェントの導入には、法的・手続き的な厳格な要件を満たすことが不可欠であるが、既存のベンチマークがこれらの特殊な要求を適切に反映できているかは不明確であった。 本研究では、行政学の理論に基づき、タスク中心、現実的、公共部門特化、およびコストや公平性を含む指標の報告という6つの基準を定義し、1,300件以上の既存ベンチマーク論文を体系的に分析した。 分析の結果、すべての基準を満たすベンチマークは一つも存在せず、特に公共部門への適合性や多角的な評価指標において大きな欠落があることが判明したため、新たな評価枠組みの構築が急務である。
TL;DR(結論)
公共部門におけるAIエージェントの導入には、法的・手続き的な厳格な要件を満たすことが不可欠であるが、既存のベンチマークがこれらの特殊な要求を適切に反映できているかは不明確であった。 本研究では、行政学の理論に基づき、タスク中心、現実的、公共部門特化、およびコストや公平性を含む指標の報告という6つの基準を定義し、1,300件以上の既存ベンチマーク論文を体系的に分析した。 分析の結果、すべての基準を満たすベンチマークは一つも存在せず、特に公共部門への適合性や多角的な評価指標において大きな欠落があることが判明したため、新たな評価枠組みの構築が急務である。
なぜこの問題か
自由民主主義における公共部門の組織は、中立性、効率性、そして偏りのない実体として、民主的に合意された法律を忠実に執行することが期待されている。この目的を達成するために、多くの法域では、プロセスの正当性、政治的中立性、透明性、非個人的な対応といった極めて厳格な要件が課されている。これらの要件に違反することは、政府に対する市民の信頼を著しく損なう可能性があり、組織的または意図的な違反が発生した場合には、国家と社会の力の均衡を崩し、民主主義の安定を脅かすリスクさえ孕んでいる。このような背景の中で、大規模言語モデル(LLM)を基盤としたエージェントを公共部門に導入することは、これまでにない脅威をもたらす可能性がある。LLMエージェントの利点であり同時に危険性でもあるのは、人間による監視を減らしながら、より複雑なタスクを遂行できる能力にある。例えば、コンプライアンスの遵守を支援したり、複雑な政策文書のための証拠を収集したりすることで効率を高めることが期待されているが、これらの過程でエージェントはどの情報を含め、どのように提示するかという裁量的な微細な決定を必然的に行うことになる。…
核心:何を提案したのか
本論文では、公共部門におけるLLMエージェントの安全で責任ある導入を導くために、ベンチマークが満たすべき基準を明確に定義することを提案している。この基準を策定するにあたり、著者らはデジタル化と官僚制に関する文献と、AIシステムの社会技術的評価に関する理論を組み合わせ、第一原理に基づいた調査を実施した。その結果、公共部門の文脈において理論的かつ実践的に意味のある評価を行うための6つの基準が導き出された。これらの基準は大きく「ベンチマークの構成」と「報告される指標」の2つのカテゴリーに分類される。構成に関する基準としては、まず第一に「タスクベースのモデル」であることが求められる。これは、組織やプロセスの活動を意味のある最小単位であるタスクに分解し、それらを相互に関連するプロセスとして再構成して評価することを意味する。第二に「現実的なタスク」であること。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related