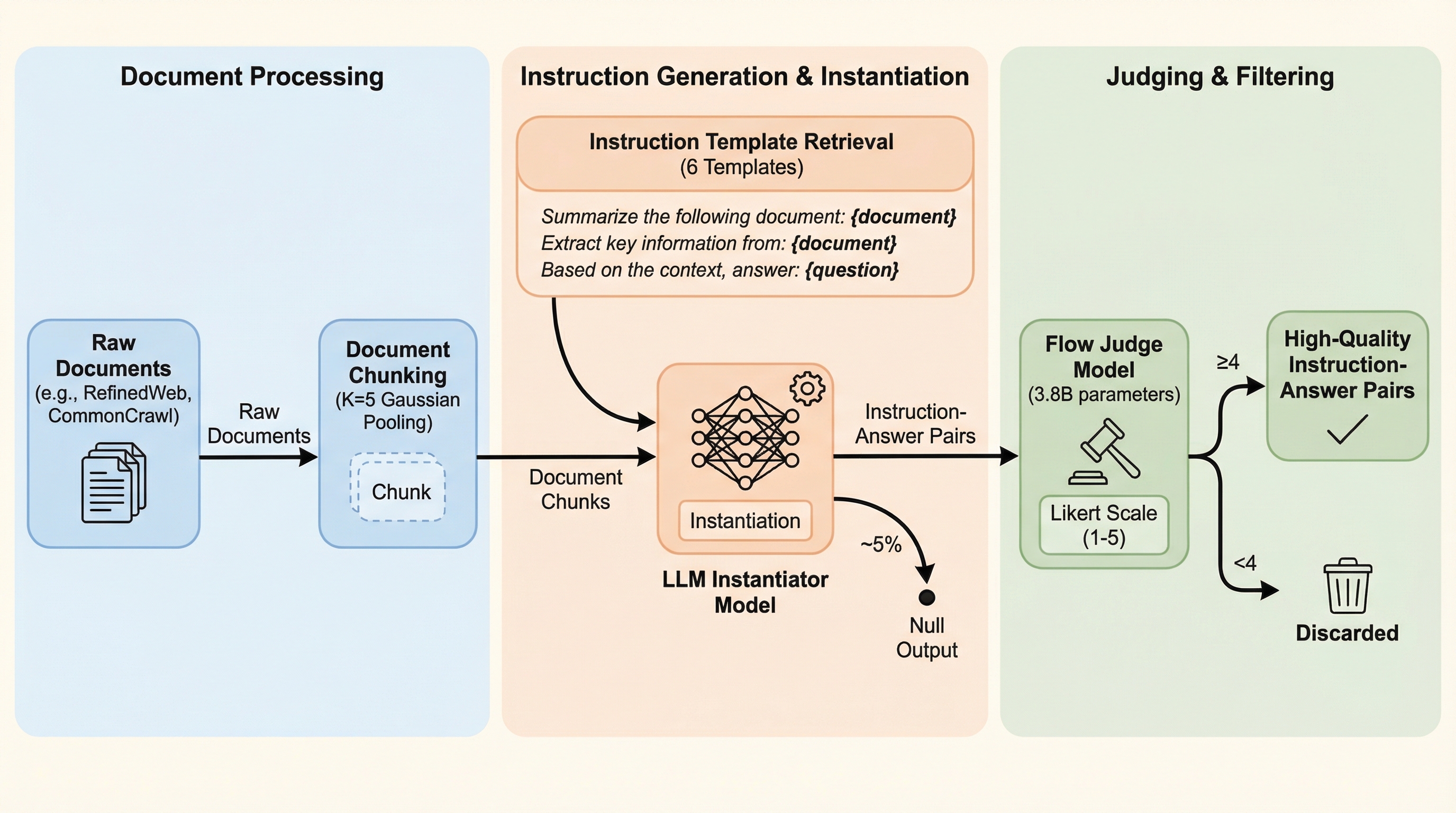
FineInstructions: 合成指示データを事前学習規模まで拡張する手法の提案
大規模言語モデル(LLM)の事前学習において、従来の非構造化テキストによる次単語予測ではなく、実際のユーザーのクエリに基づいた「指示と回答」のペアを10億件以上の規模で合成し、それを用いてゼロから学習を行う手法「FineInstructions」が提案された。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の事前学習において、従来の非構造化テキストによる次単語予測ではなく、実際のユーザーのクエリに基づいた「指示と回答」のペアを10億件以上の規模で合成し、それを用いてゼロから学習を行う手法「FineInstructions」が提案された。
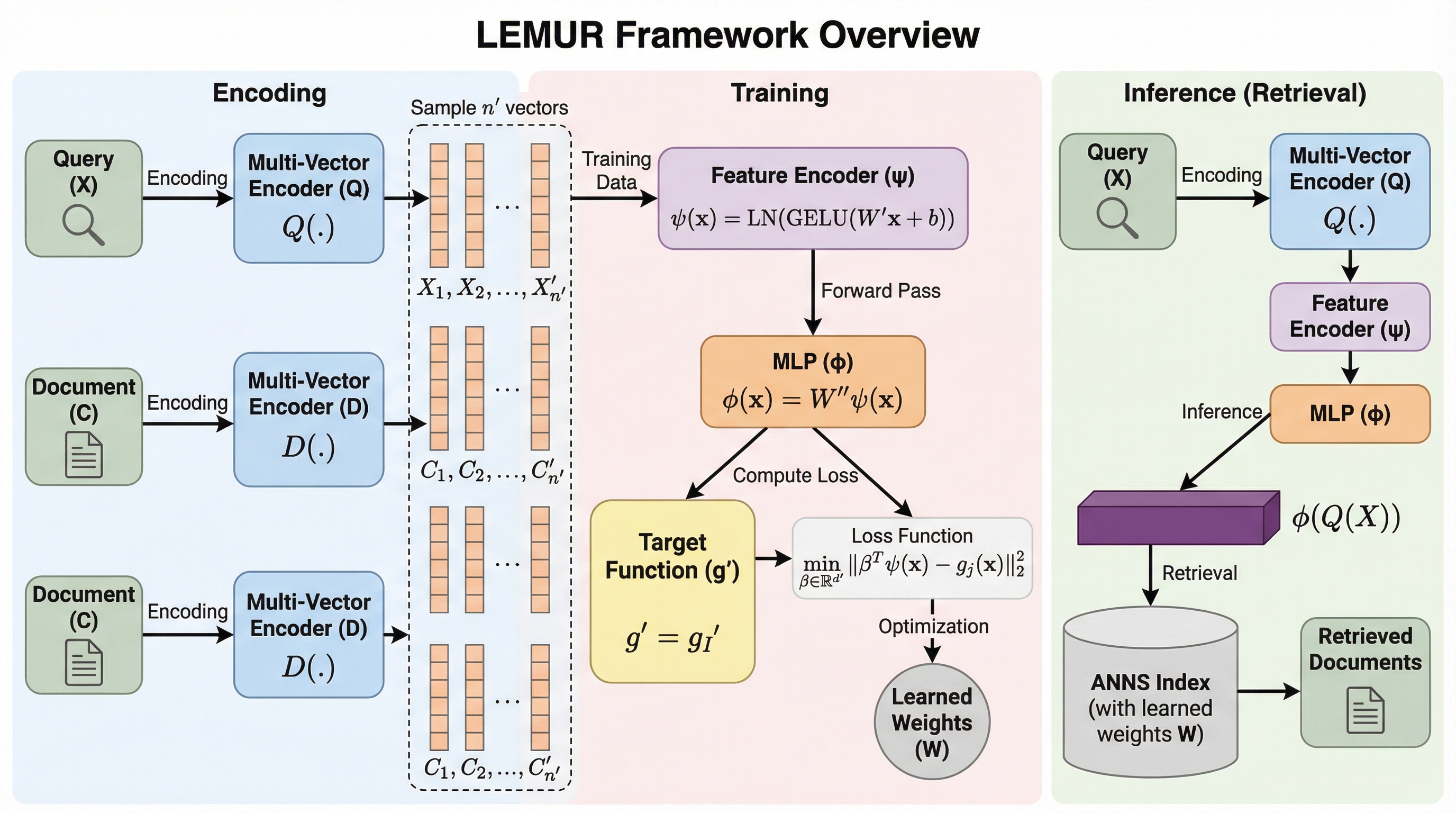
情報検索において高い精度を誇るColBERTなどのマルチベクトルモデルは、MaxSim計算の複雑さゆえに検索遅延が非常に大きいという課題を抱えていました。本研究で提案されたLEMURは、このマルチベクトル検索を教師あり学習による回帰問題として再定義し、最終的に潜在空間上の単一ベクトルによる近似近傍探索へと変換することで、既存の高速な検索ライブラリの活用を可能にしました。 検証の結果、LEMURは従来のマルチベクトル検索手法と比較して1桁(約10倍)以上の高速化を達成しており、最新のテキスト検索モデルや視覚的な文書検索モデルにおいても、高い再現率を維持しながら劇的なパフォーマンス向上を実現することが確認されました。 このフレームワークは、軽量なニューラルネットワークを用いてトークン単位の埋め込みを潜在空間上の単一ベクトルへと集約し、ドキュメントの重み行列との内積計算によって類似度を推定する仕組みを採用しており、大規模なコーパスに対しても効率的なインデックス作成と高速な検索を両立させています。
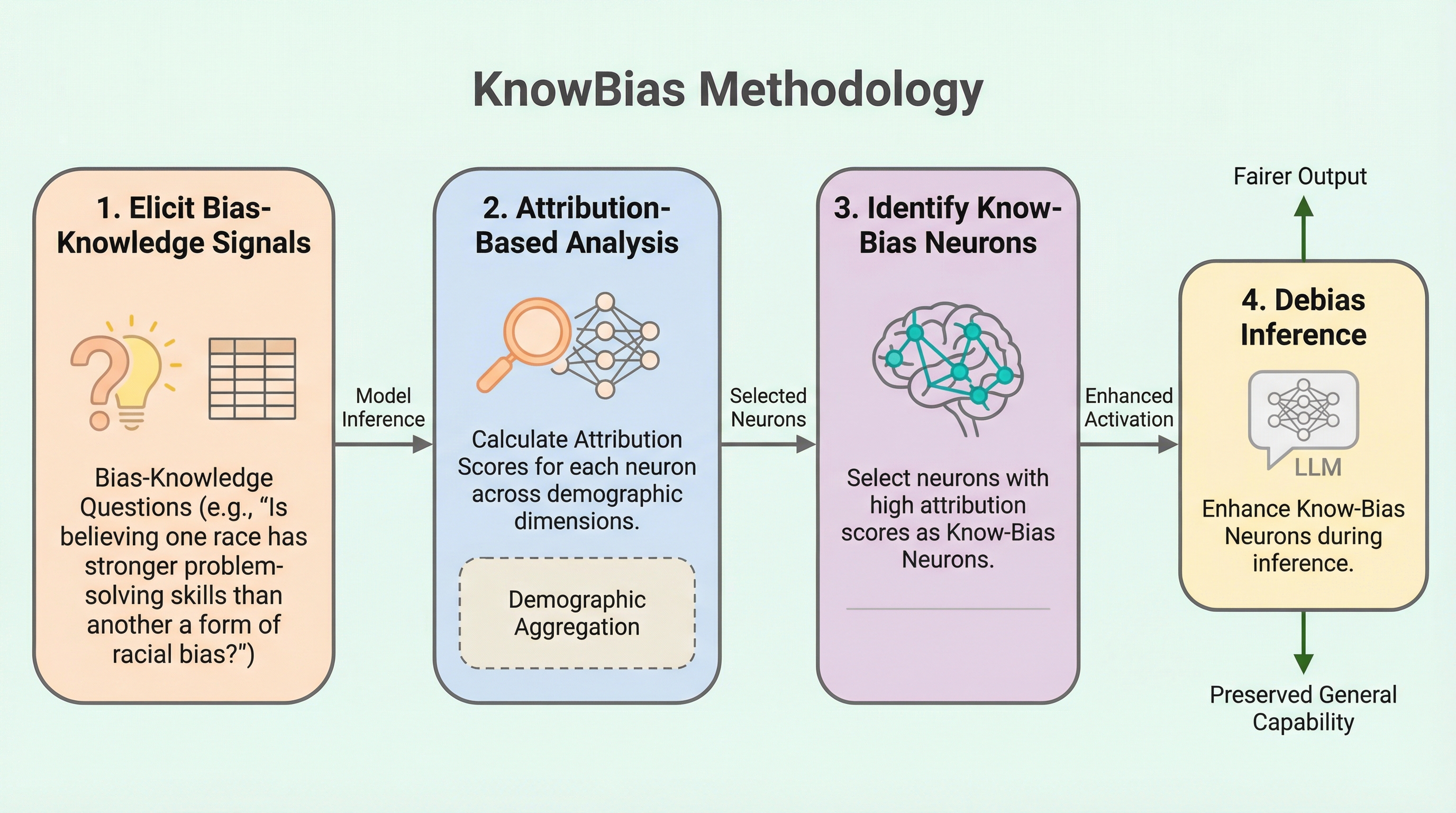
大規模言語モデル(LLM)が抱える社会的バイアスを、従来の「バイアス行動の抑制」ではなく、モデル内部の「バイアスに関する知識」を司るニューロンを特定して強化することで解決する新手法「KnowBias」が提案されました。
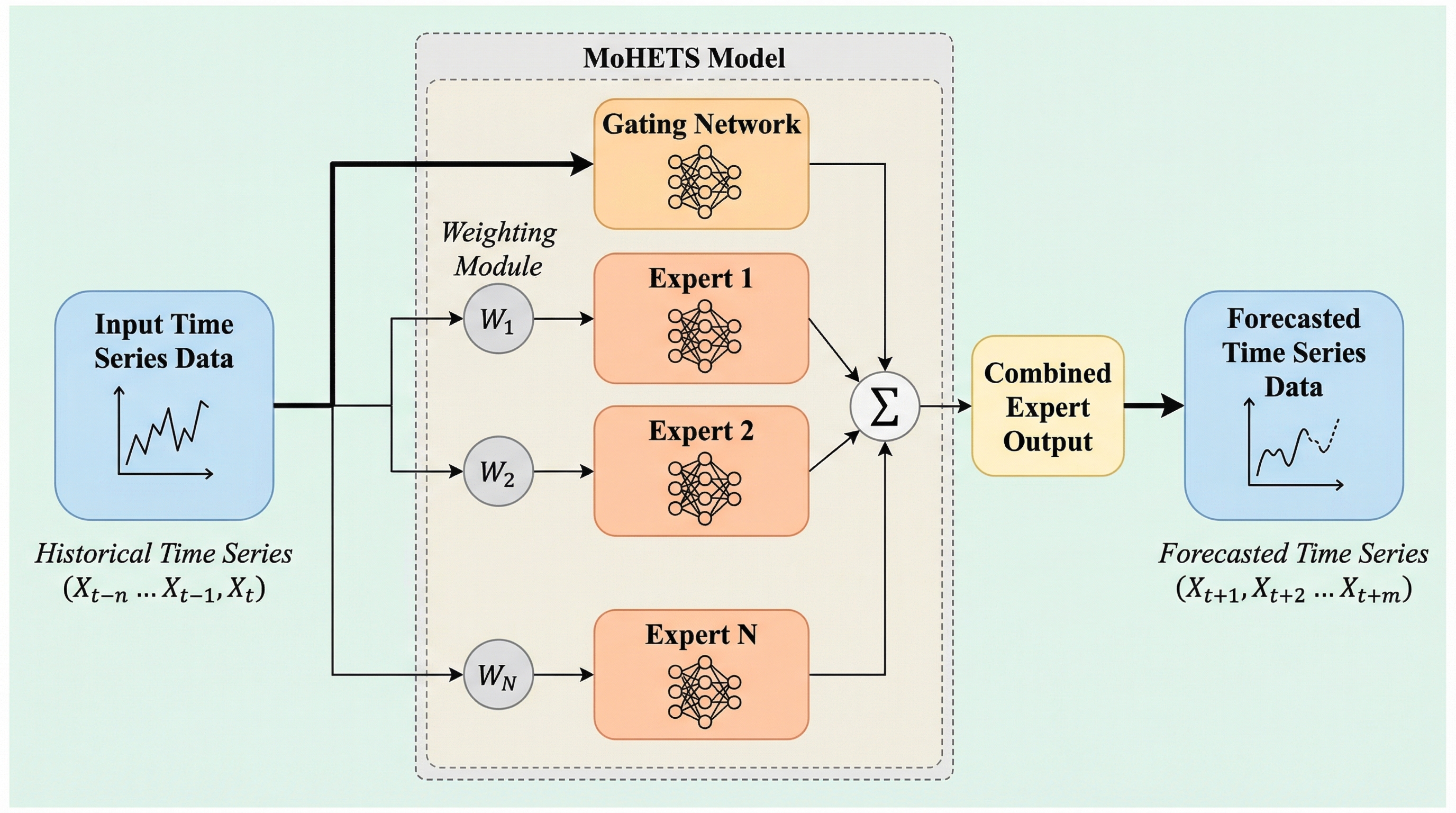
MoHETSは、多変量時系列データの複雑な多スケール構造を捉えるために、構造の異なる専門家ネットワークを組み合わせた「異種混合エキスパート(MoHE)」を導入したエンコーダーのみのTransformerモデルである。
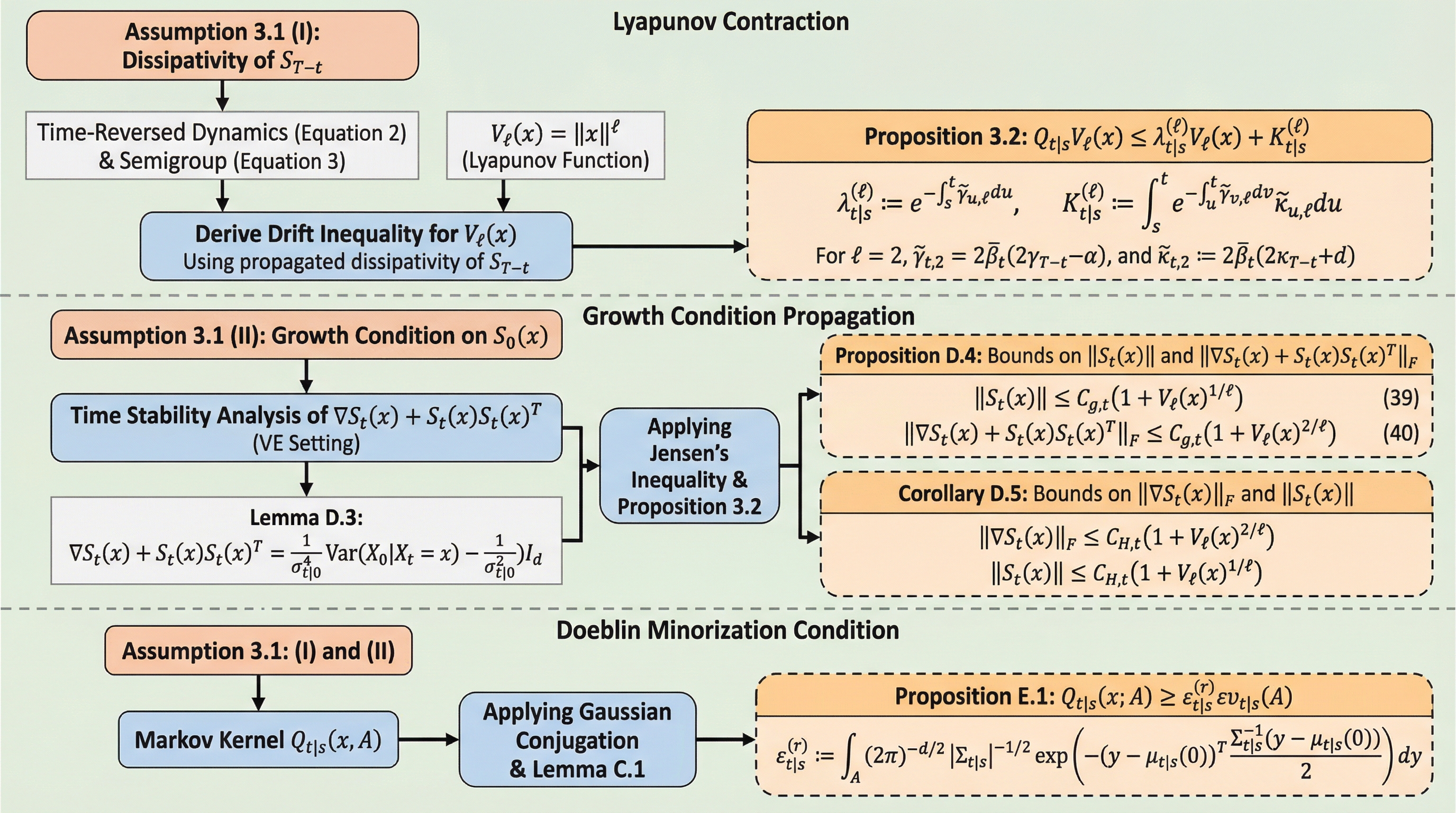
スコアベース生成モデル(SGM)のサンプリング過程における安定性と長期的な挙動を、逆時間ダイナミクスに関連するマルコフ連鎖の「忘却性」という観点から理論的に解明しました。具体的には、ハリスの安定性理論に基づき、リアプノフ・ドリフト条件とデブリン型のマイノリゼーション条件という2つの構造的特性を用いることで、初期化誤差や離散化誤差がサンプリングの軌道に沿ってどのように伝播するかを定量的に制限する枠組みを提案しています。この研究の結果、逆拡散ダイナミクスがサンプリング軌道に沿って収縮メカニズムを誘発することが示され、強凸性などの厳しい仮定を置かずに、非凸でマルチモーダルなデータ分布に対してもサンプリング手順の定量的な安定性を保証することが可能になりました。
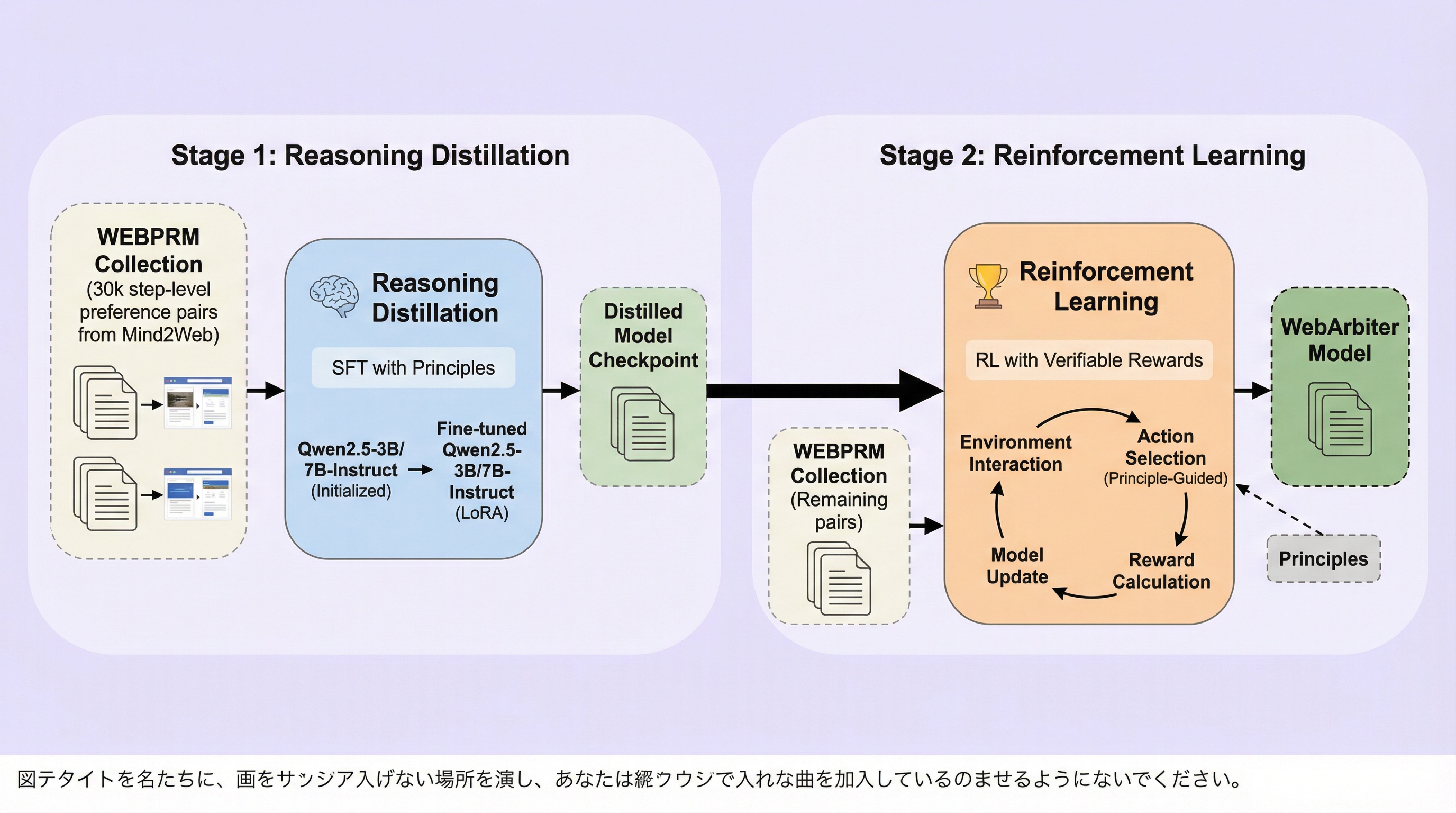
Webエージェントが複雑なタスクを遂行する際、最終結果のみを評価する従来手法では、途中の不可逆な誤りや信号の遅延に対応できないという深刻な課題がありました。本研究で提案されたWebArbiterは、行動の妥当性をテキスト生成による「推論」と「原理の導出」を通じて評価する、推論優先型のプロセス報酬モデル(WebPRM)であり、単なる数値スコアではなく論理的な根拠を生成します。このモデルは、強力な教師モデルからの推論蒸留と、正解信号に直接合わせる強化学習の2段階で訓練され、既存のGPT-5などの大規模モデルを大幅に上回る精度を達成したほか、4つの異なるWeb環境を網羅した評価ベンチマーク「WEBPRMBENCH」において、実用的なWeb操作タスクの成功率を最大7.2ポイント向上させるなど、極めて高い実用性と堅牢性を証明しました。
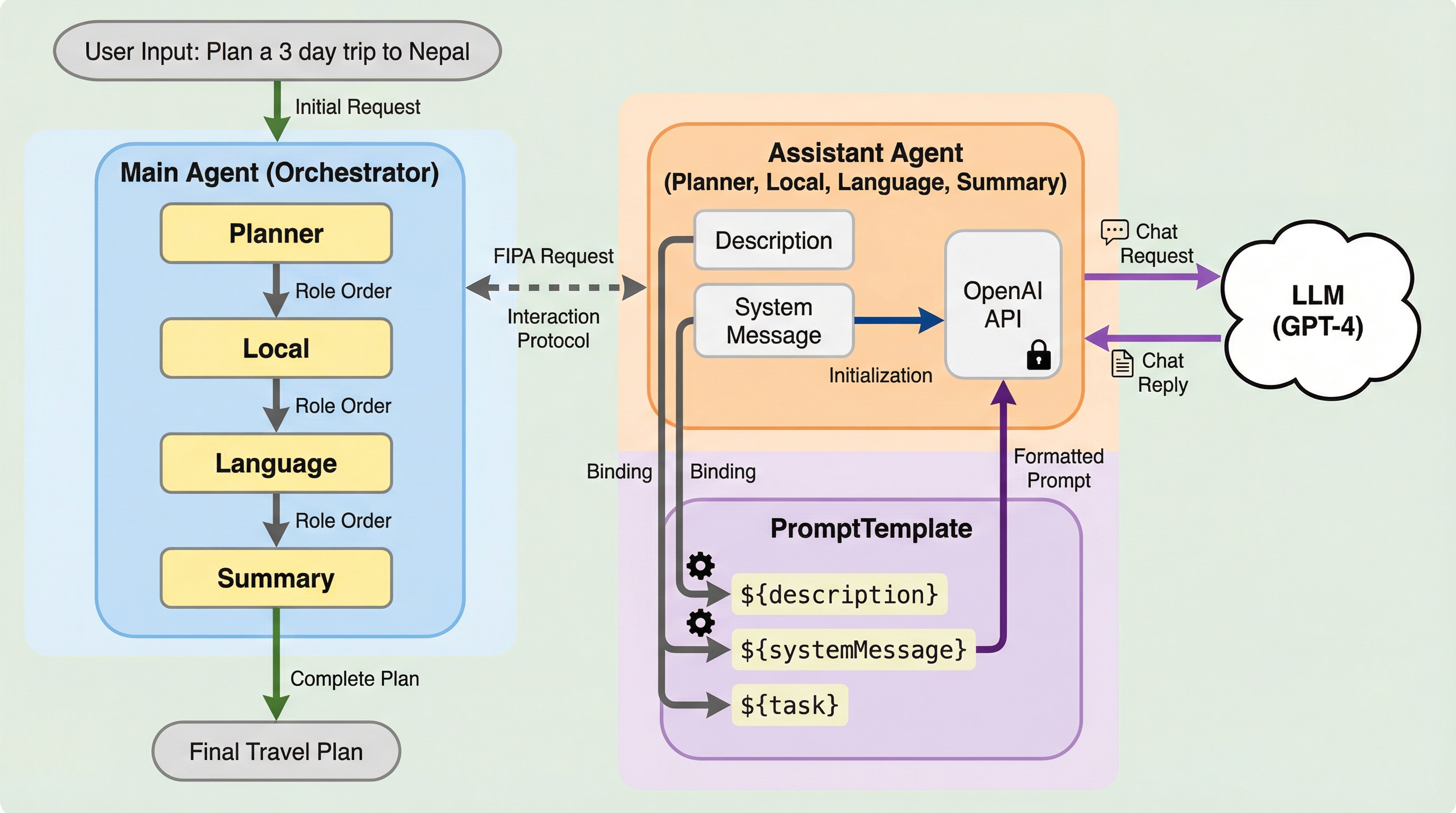
ASTRAプログラミング言語に大規模言語モデル(LLM)の機能を統合するための専用ライブラリ「astra-langchain4j」が開発され、Java向けのLangChain4jを基盤として、生成AIの推論や計画能力を自律型エージェントに組み込む新しい手法が提案された。
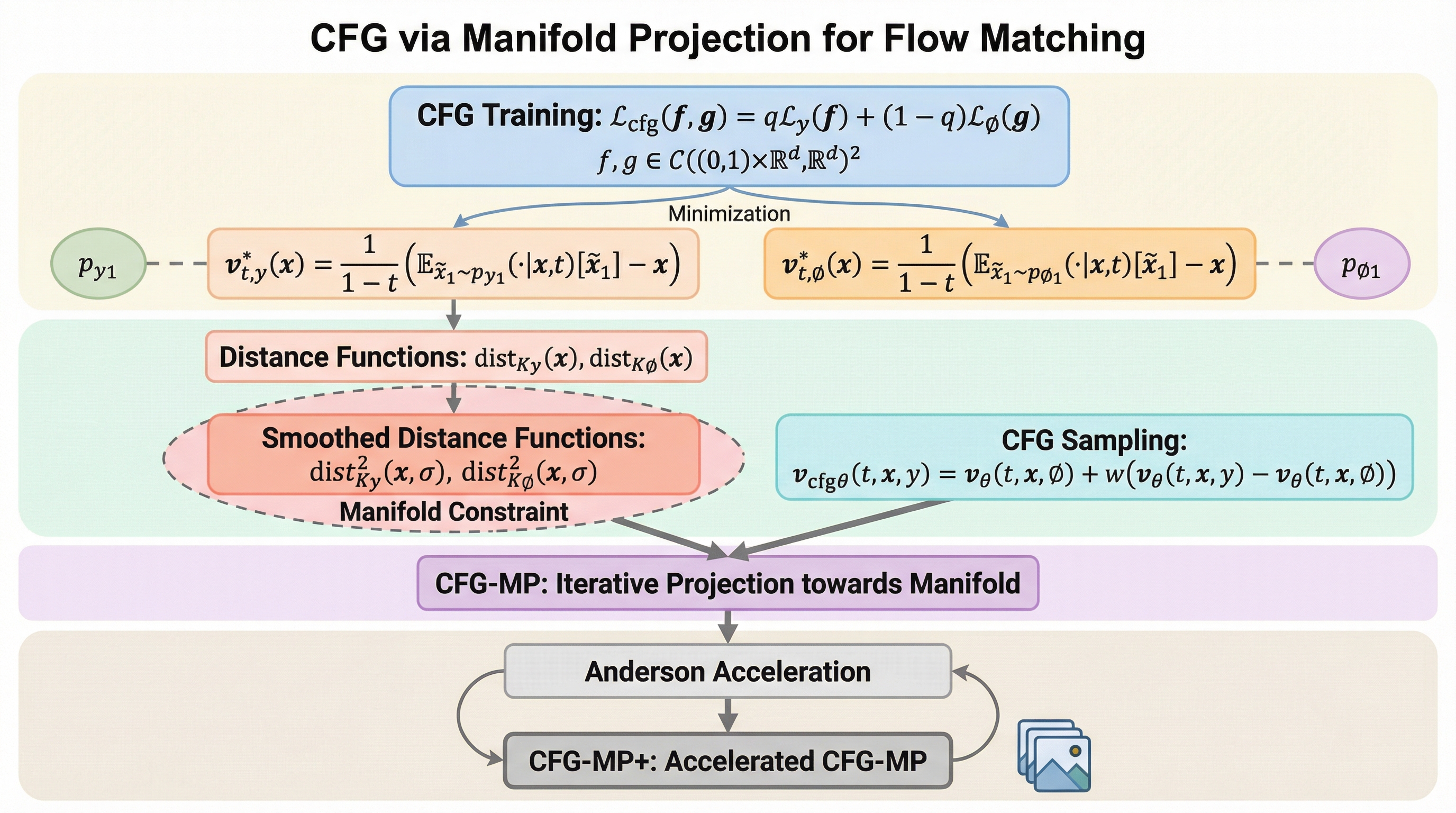
フローマッチングにおける分類器なしガイダンス(CFG)を最適化の観点から再解釈し、生成プロセスをターゲット画像集合への距離を最小化するホモトピー最適化として定義することで、サンプリングの精度を向上させる新手法「CFG-MP」を提案した。
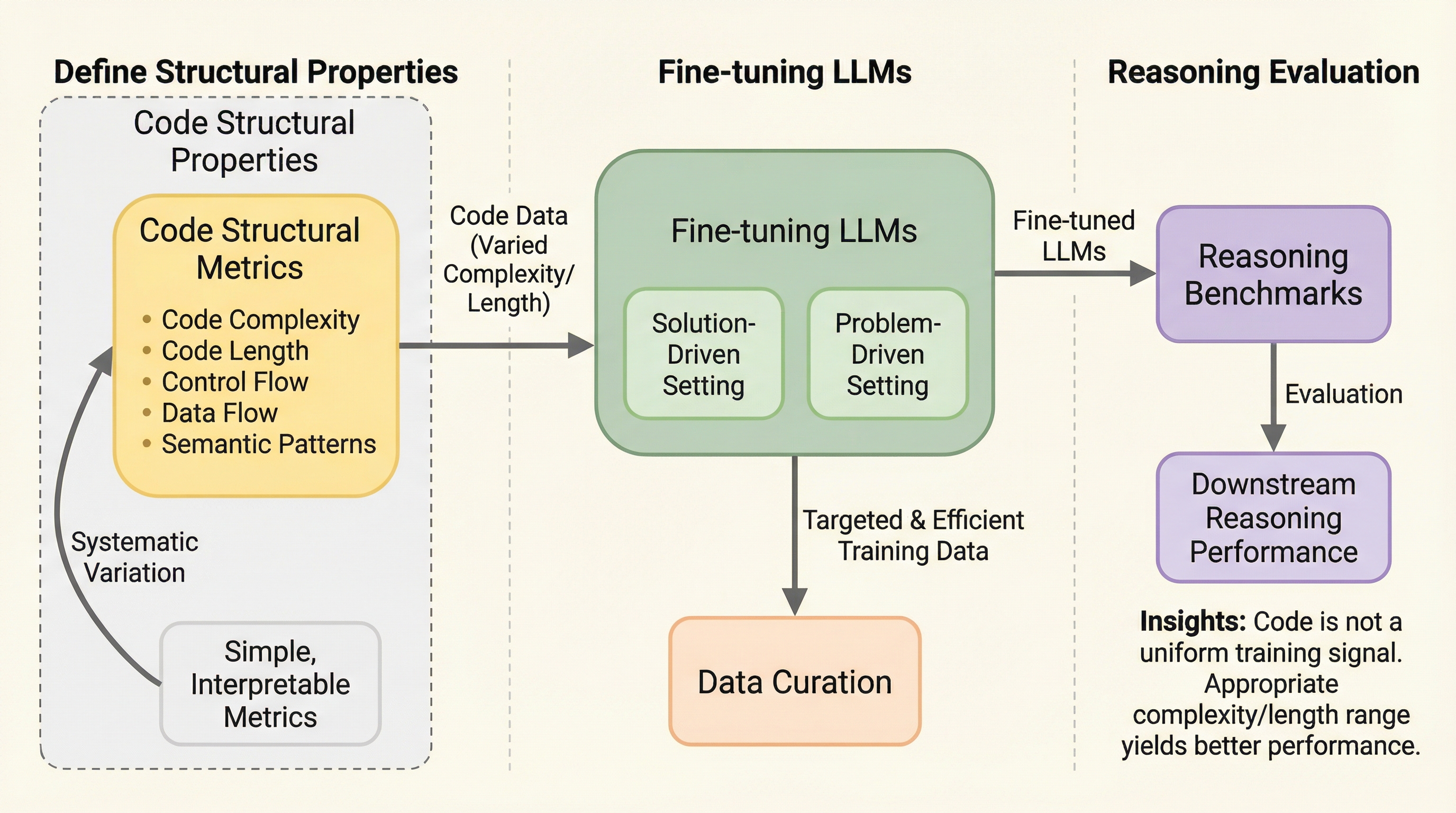
大規模言語モデル(LLM)の推論能力を向上させるためには、学習に用いるコードの「構造的複雑さ」を適切に制御することが極めて重要であり、単にデータの量や多様性を増やすだけでは不十分であることが明らかになりました。
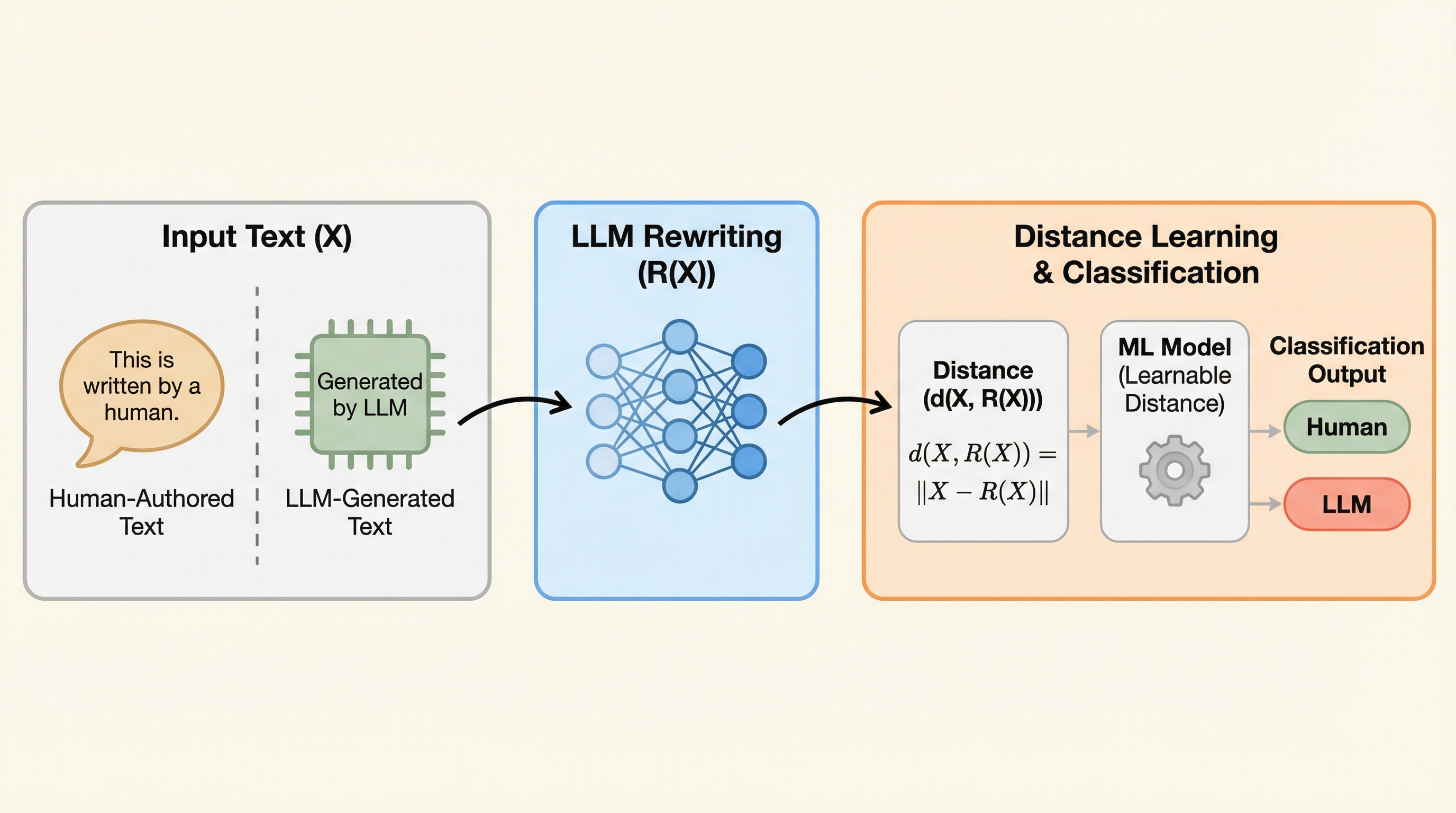
大規模言語モデル(LLM)が生成したテキストを精度高く識別するため、元のテキストとその書き換え版との間の距離を適応的に学習する新手法「Learn-to-Distance」が提案されました。 幾何学的なアプローチによって、人間が書いた文章はLLMの生成空間から外れているため書き換えによる変化が大きくなるという原理を解明し、固定された指標ではなく学習可能な距離関数を用いることで検出精度を大幅に向上させています。 実験ではGPTやClaude、Geminiなどの最新モデルを含む広範な設定で検証が行われ、既存の強力な手法と比較して57.8%から80.6%の相対的な性能改善を達成し、未知のプロンプトや敵対的攻撃に対しても高い堅牢性を示しました。