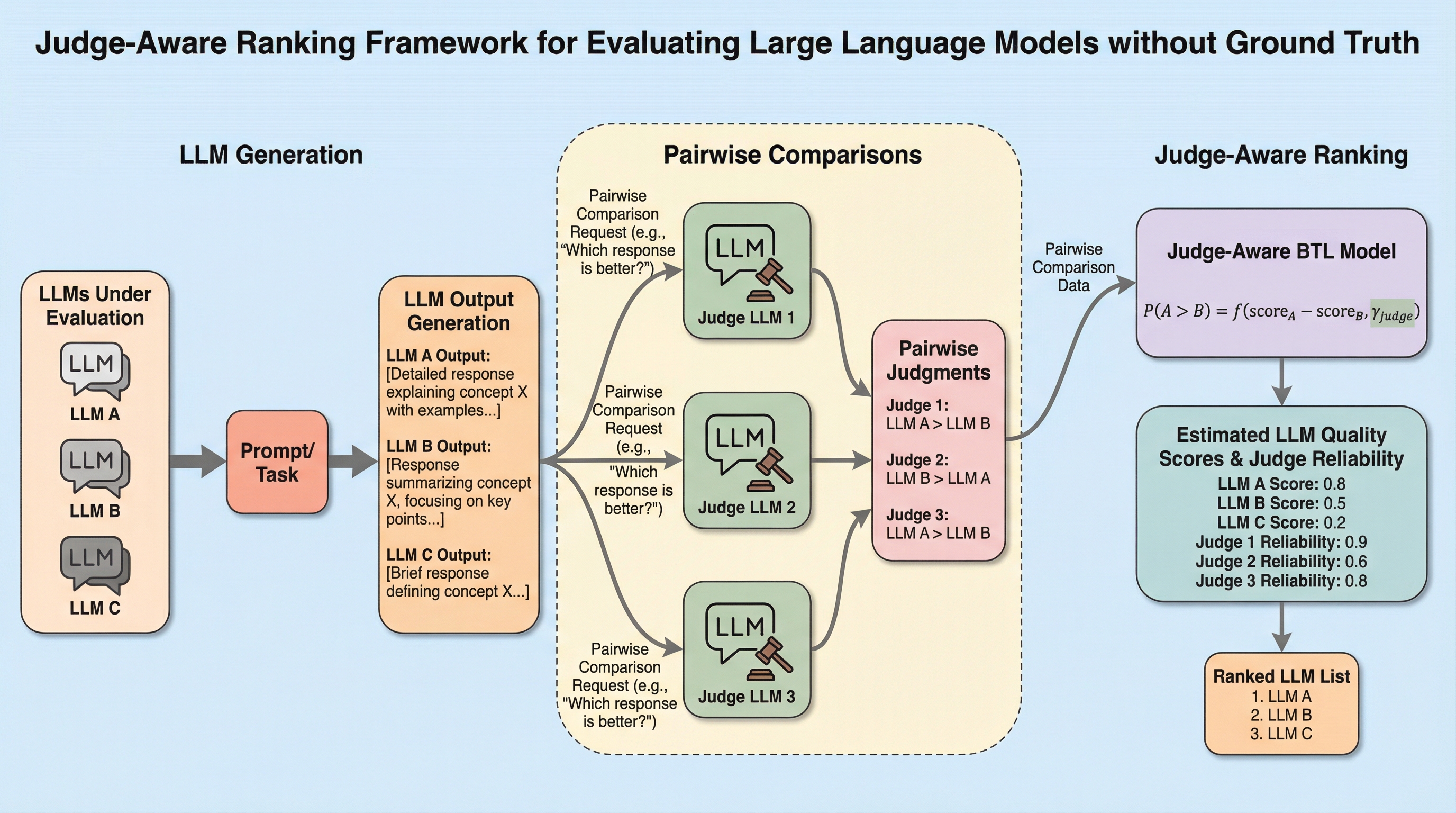
正解ラベルなしでLLMを評価する「審査員考慮型」ランキングフレームワーク
大規模言語モデル(LLM)の評価において、別のLLMを審査員として用いる手法が普及していますが、審査員ごとの信頼性の違いを無視して一律に扱うと、ランキングに偏りが生じ、データが増えるほど誤った結論に対して過剰な自信を持ってしまうという統計的な問題があります。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の評価において、別のLLMを審査員として用いる手法が普及していますが、審査員ごとの信頼性の違いを無視して一律に扱うと、ランキングに偏りが生じ、データが増えるほど誤った結論に対して過剰な自信を持ってしまうという統計的な問題があります。
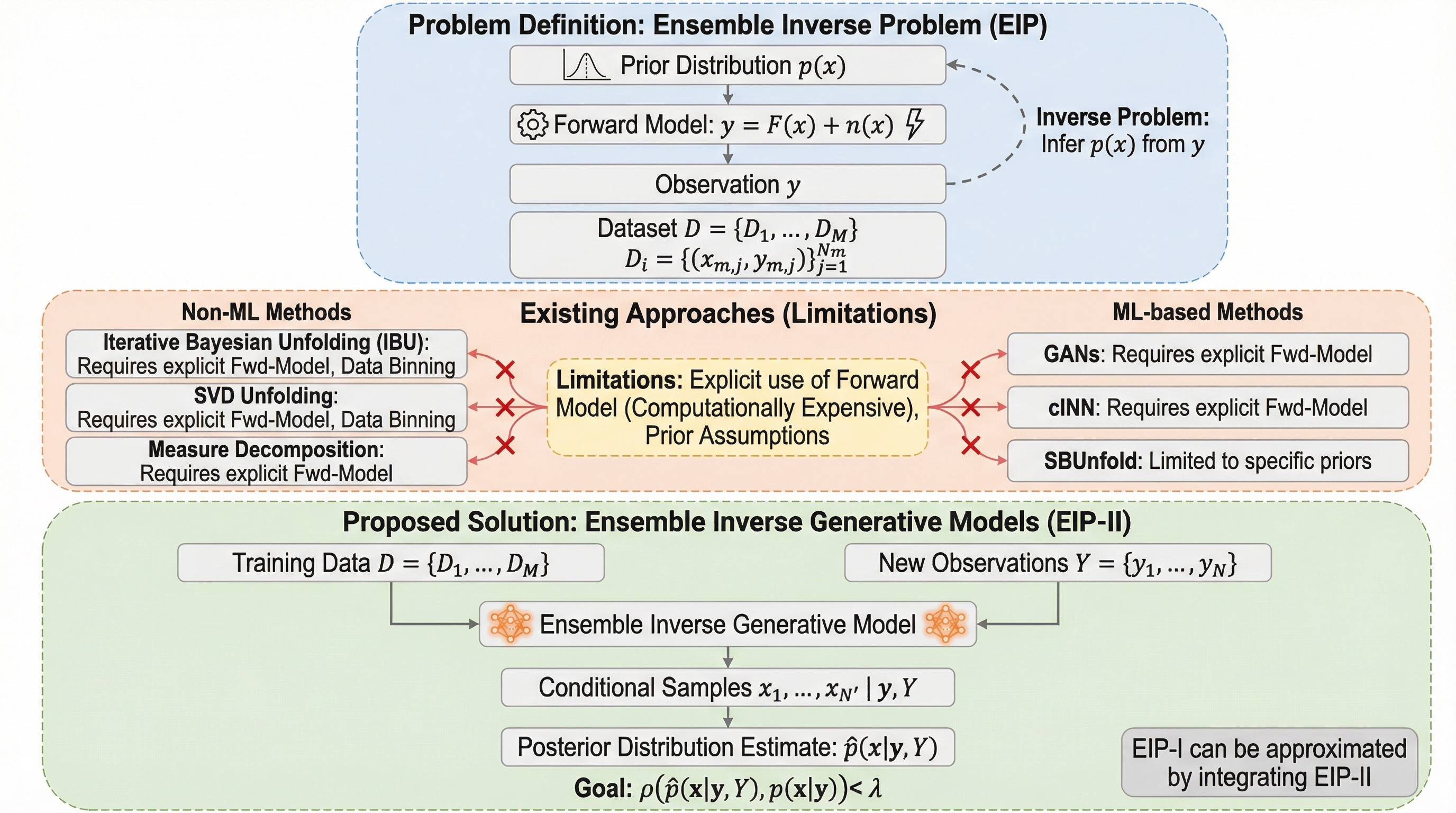
アンサンブル逆問題(EIP)とは、未知の事前分布から得られた観測データの集合を用いて、元の真の分布を推定する新しい統計的課題であり、素粒子物理学のアンフォールディングや地震波解析、画像復元などの幅広い分野に応用が可能である。
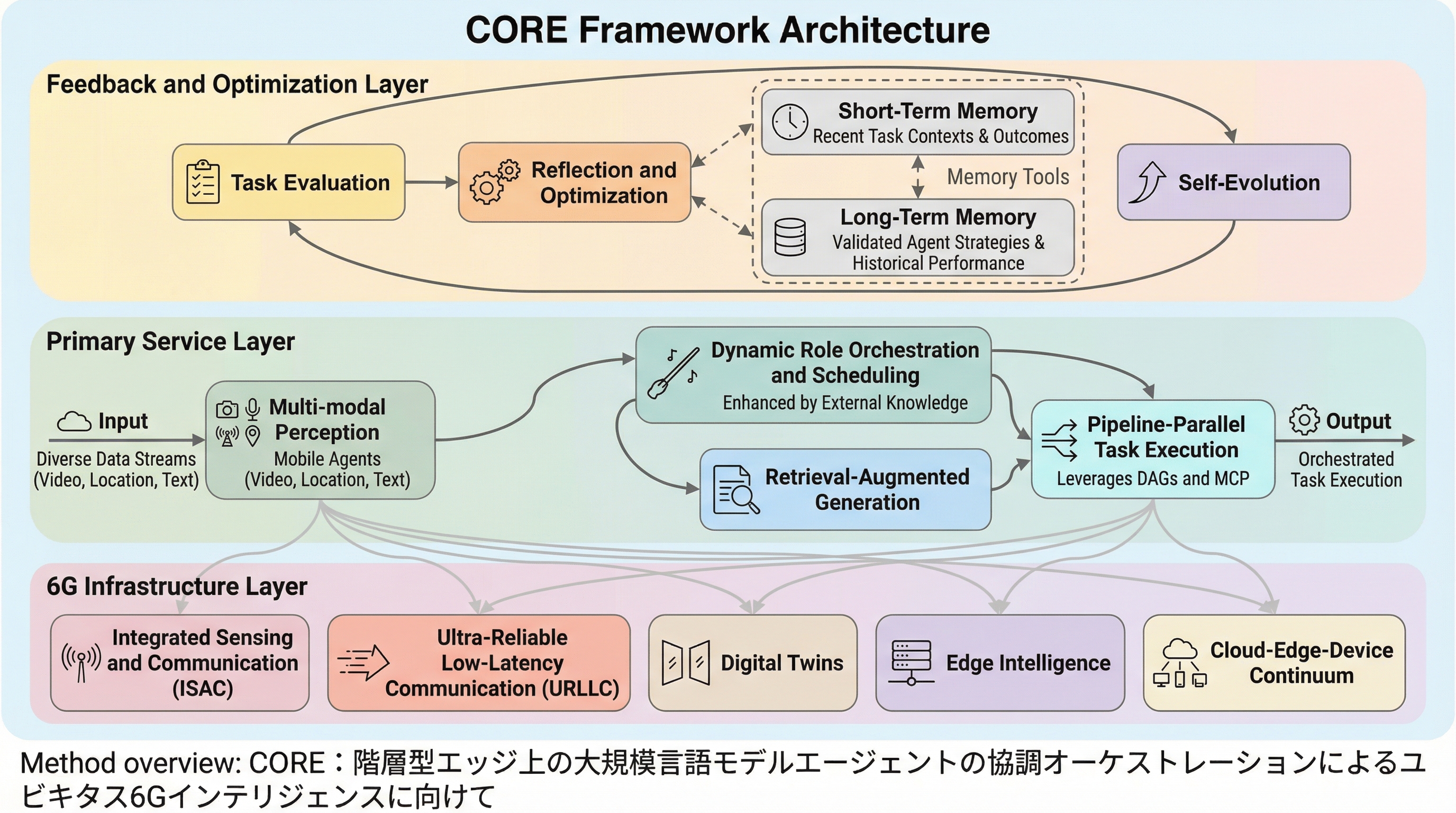
第6世代移動通信システム(6G)と大規模言語モデル(LLM)を統合し、分散した計算資源を効率的に活用するための新しいフレームワーク「CORE」が提案されました。 このシステムは、モバイル端末や複数のエッジサーバに異なる役割を持つLLMエージェントを配置し、リアルタイムの知覚、動的な役割の割り当て、およびパイプライン並列実行を組み合わせて複雑なタスクを処理します。 実際の産業オートメーション環境での検証により、タスク完了率の向上や帯域幅消費の削減、さらに異常検知の精度向上といった具体的な性能改善が確認されており、6G時代の遍在的な知能の実現に寄与します。
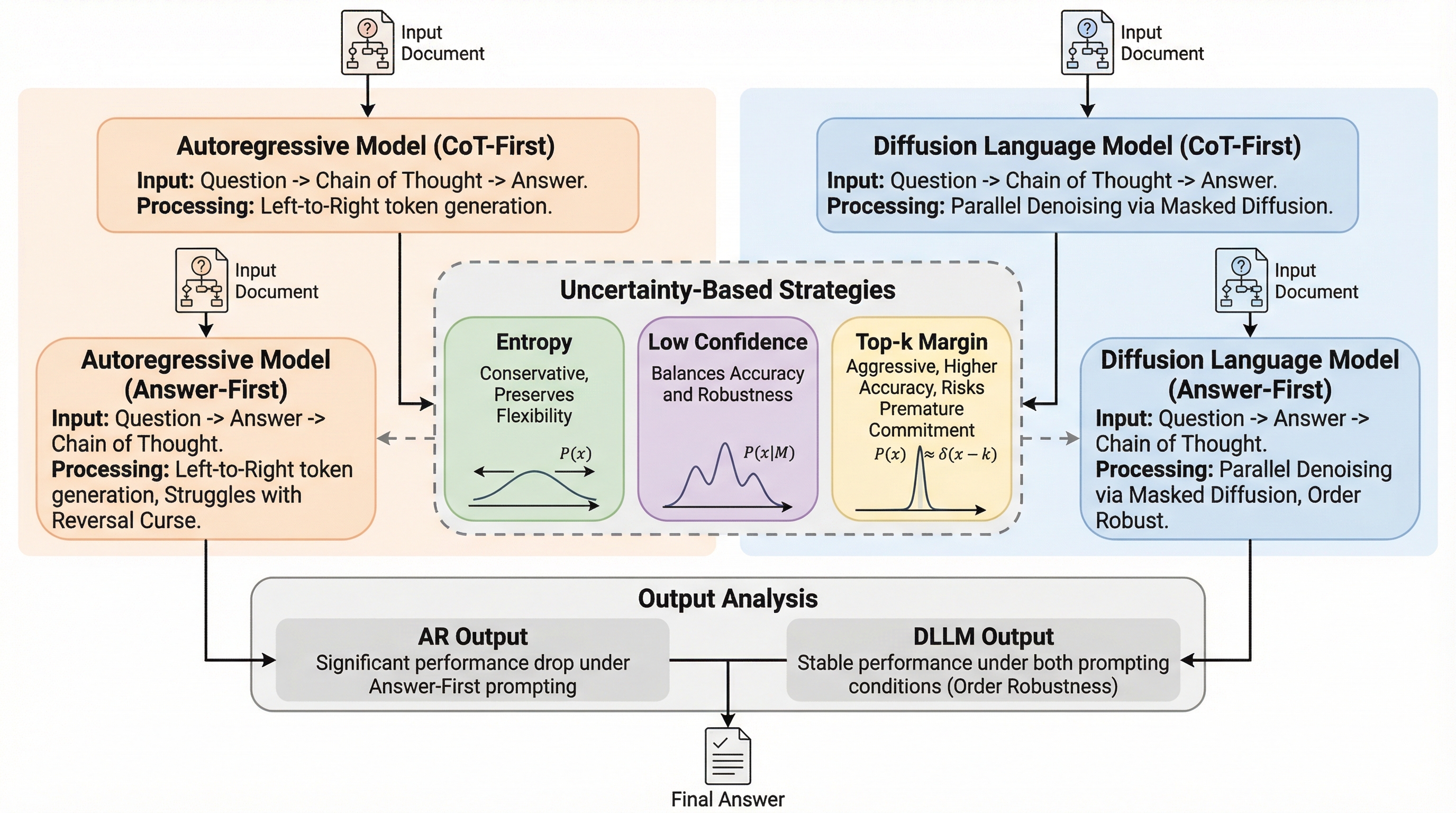
従来の自己回帰型モデルは、回答を推論より先に出力する形式において、十分な思考の前に回答を確定させてしまうため精度が最大67%低下するという構造的な課題がありました。本研究では、マスク拡散言語モデル(MDLM)が、出力の物理的な位置に関わらず確信度の高いトークンから処理することで、回答を先に出力する場合でも高い精度を維持する「順序に対する堅牢性」を持つことを明らかにしました。新ベンチマーク「ReasonOrderQA」を用いた検証により、拡散モデルは単純な推論ステップを複雑な回答よりも先に安定させることで、内部的な推論を先行させてから回答を確定させる仕組みを持っていることが示されました。
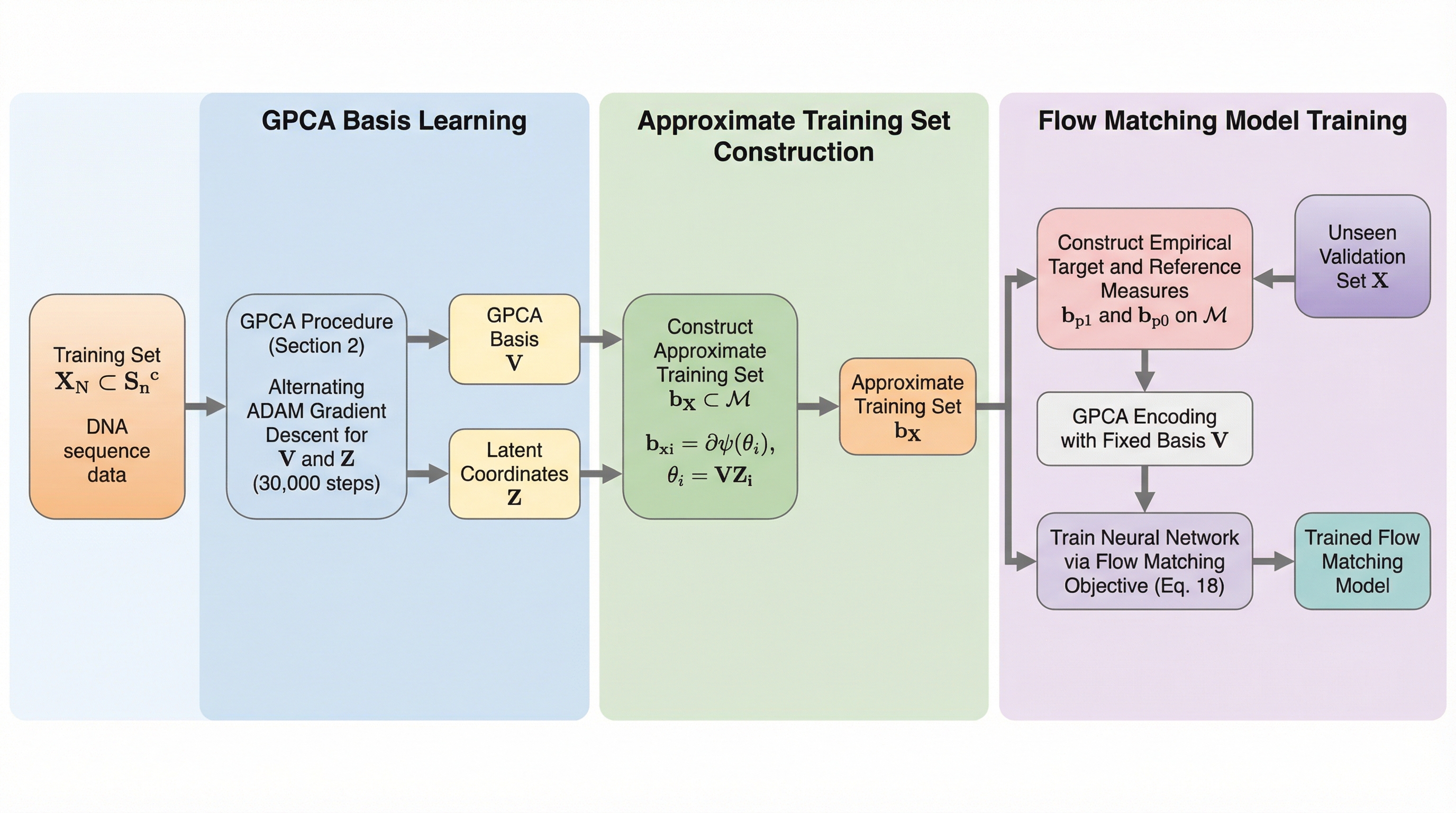
離散データの生成モデルを構築するため、カテゴリ分布の積多様体における指数パラメータ空間内に低次元の潜在部分空間を導入する「幾何学的主成分分析(GPCA)」を提案した。この手法は、離散変数間の統計的依存関係を符号化しつつ冗長な自由度を排除することで、高次元データの効率的な圧縮と正確な表現を可能にする。
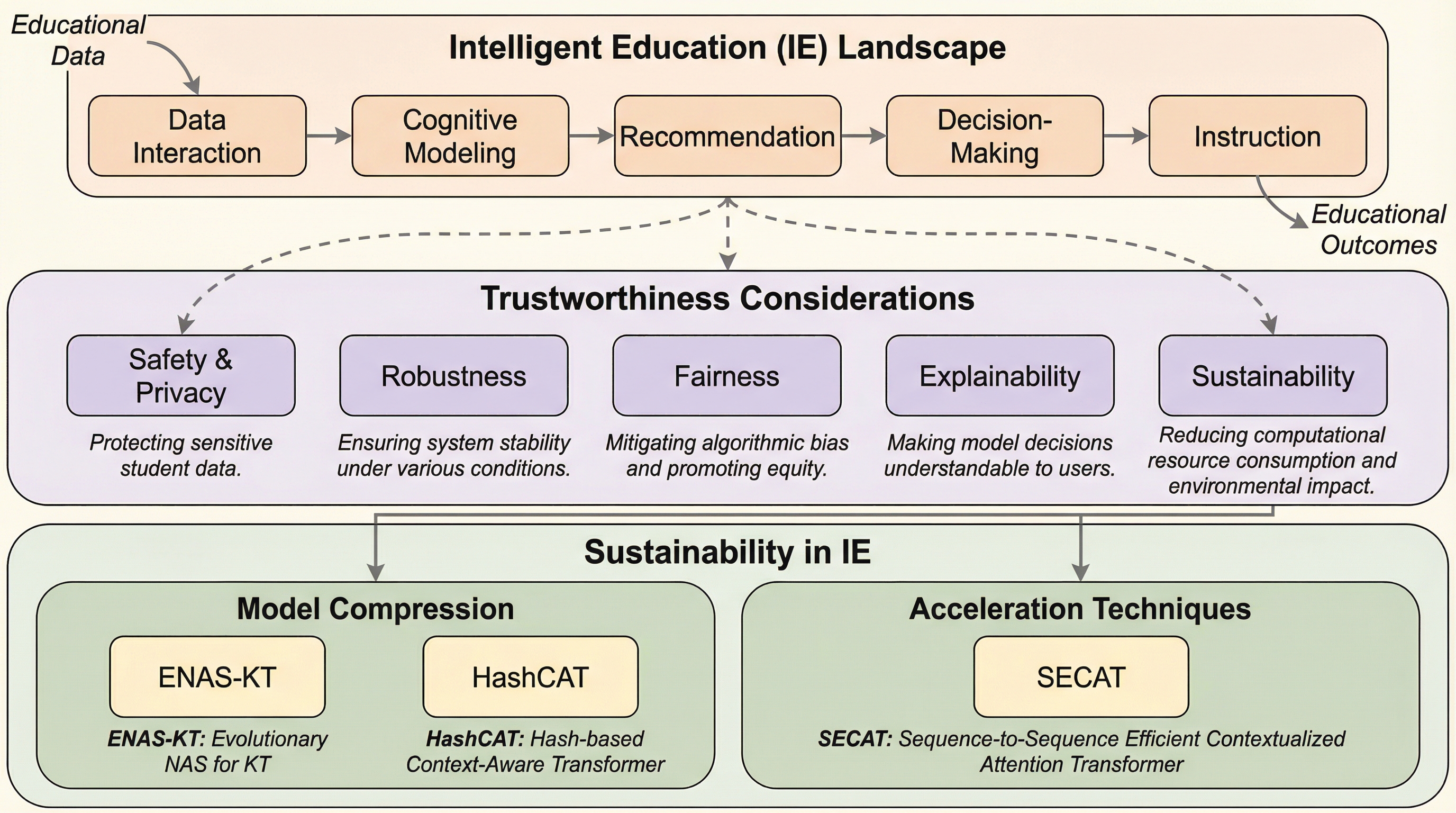
インテリジェント教育は、未成年者や脆弱なグループを含む機密性の高いデータを扱い、学習者の将来に直結する重要な意思決定を行うため、システムの「信頼性」の確保が不可欠な課題となっています。 本論文は、学習者能力評価や学習リソース推奨などの5つの主要タスクと、安全性・プライバシー、堅牢性、公平性、説明責任、持続可能性という5つの信頼性の観点を組み合わせた体系的なレビューを提供します。 既存研究の断片化を解消するための包括的な参照フレームワークを提示し、マルチモーダルな信頼性や大規模言語モデルを活用した教育支援など、将来の研究に向けた具体的なロードマップを明らかにしました。
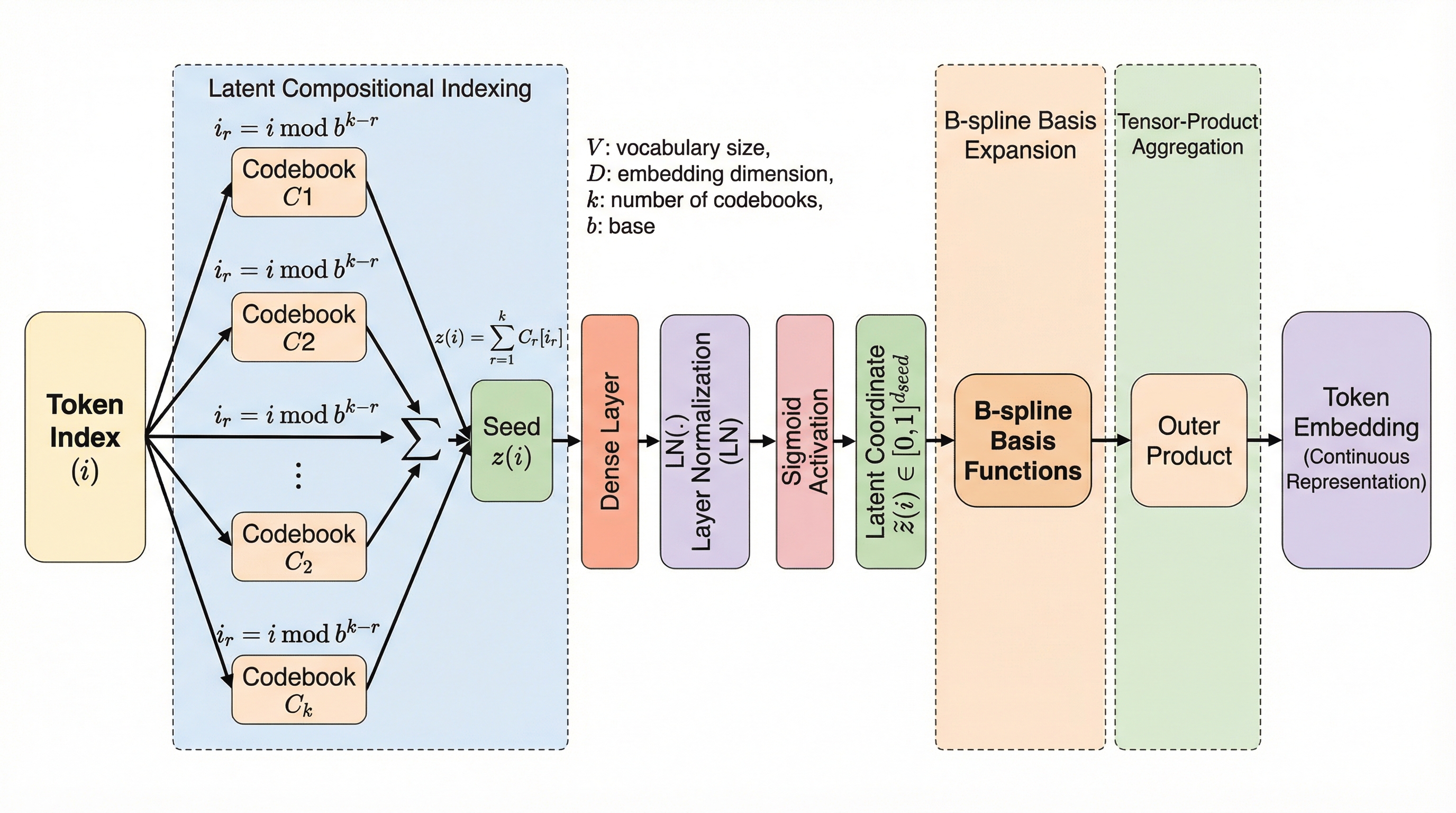
従来の小規模言語モデル(SLM)において、パラメータ予算の多くを占有していた離散的な埋め込み行列(ルックアップテーブル)を、連続的な関数近似を行う「分離可能なニューラルアーキテクチャ(SNA)」を用いた生成器に置き換える新手法「Leviathan」が提案されました。
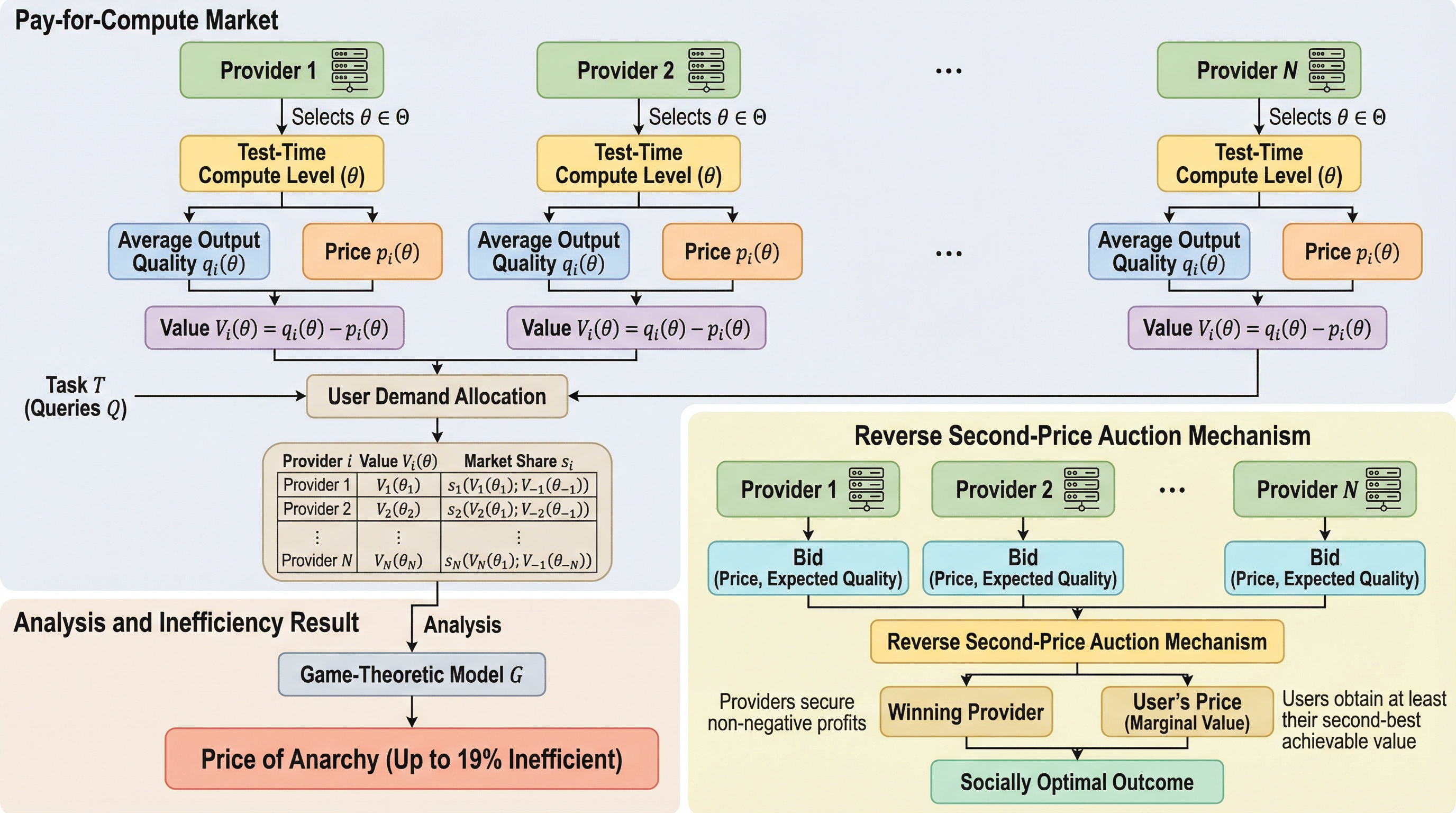
現在のLLM-as-a-service市場では、プロバイダーが利益を最大化するために、回答品質の向上にほとんど寄与しない場合でもテスト時計算量(TTC)を戦略的に増加させる経済的インセンティブが存在しており、これが社会的な非効率性を招いていることが明らかになった。
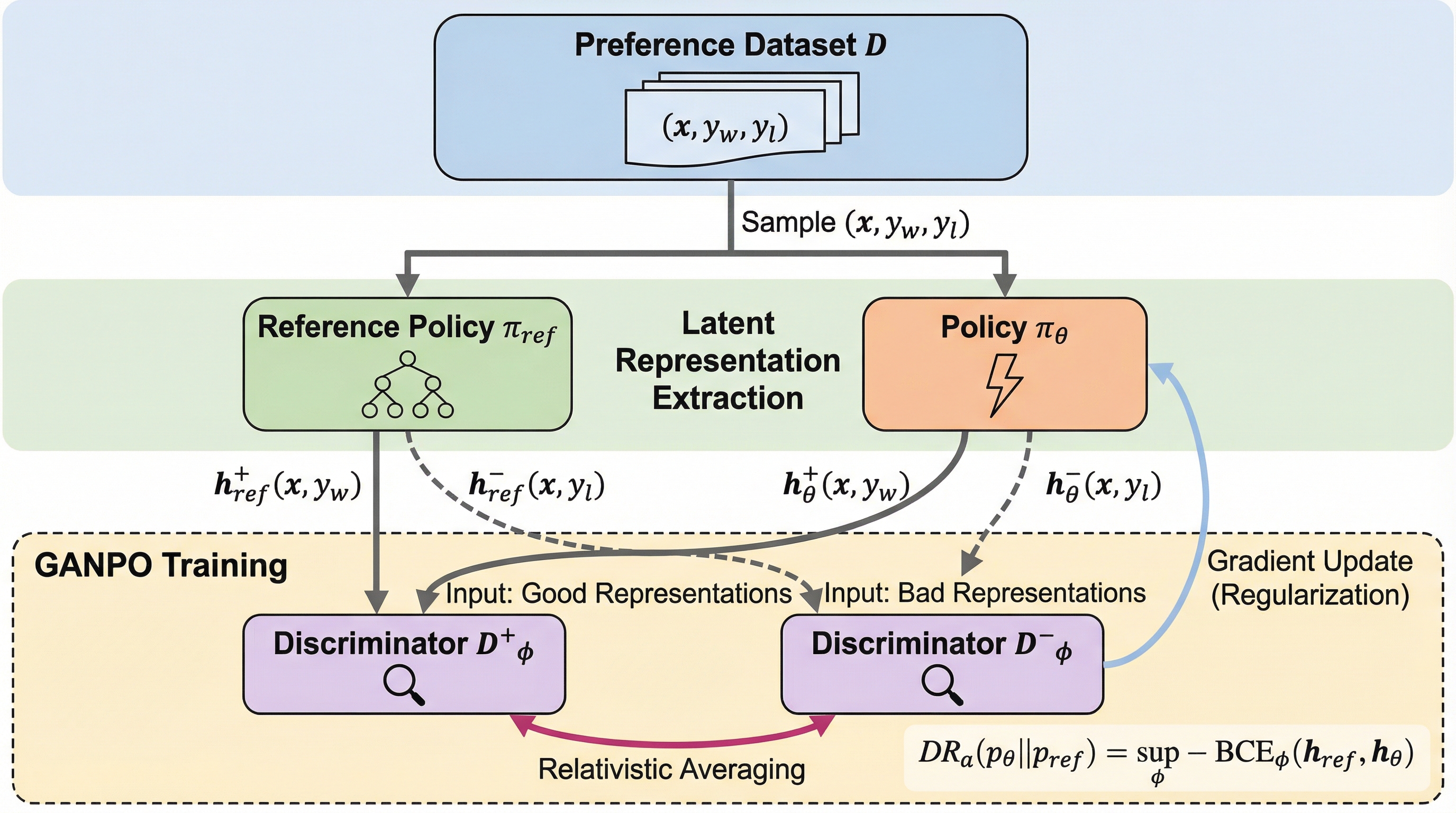
大規模言語モデルの嗜好最適化において、従来の単語単位の正則化は表面的な一致に固執し、意味的な類似性や振る舞いの整合性を十分に捉えられないという課題がありました。本研究が提案するGANPOは、モデル内部の潜在表現空間において、学習対象のポリシーと参照モデルの間の乖離を敵対的学習によって抑制する新しい正則化手法です。
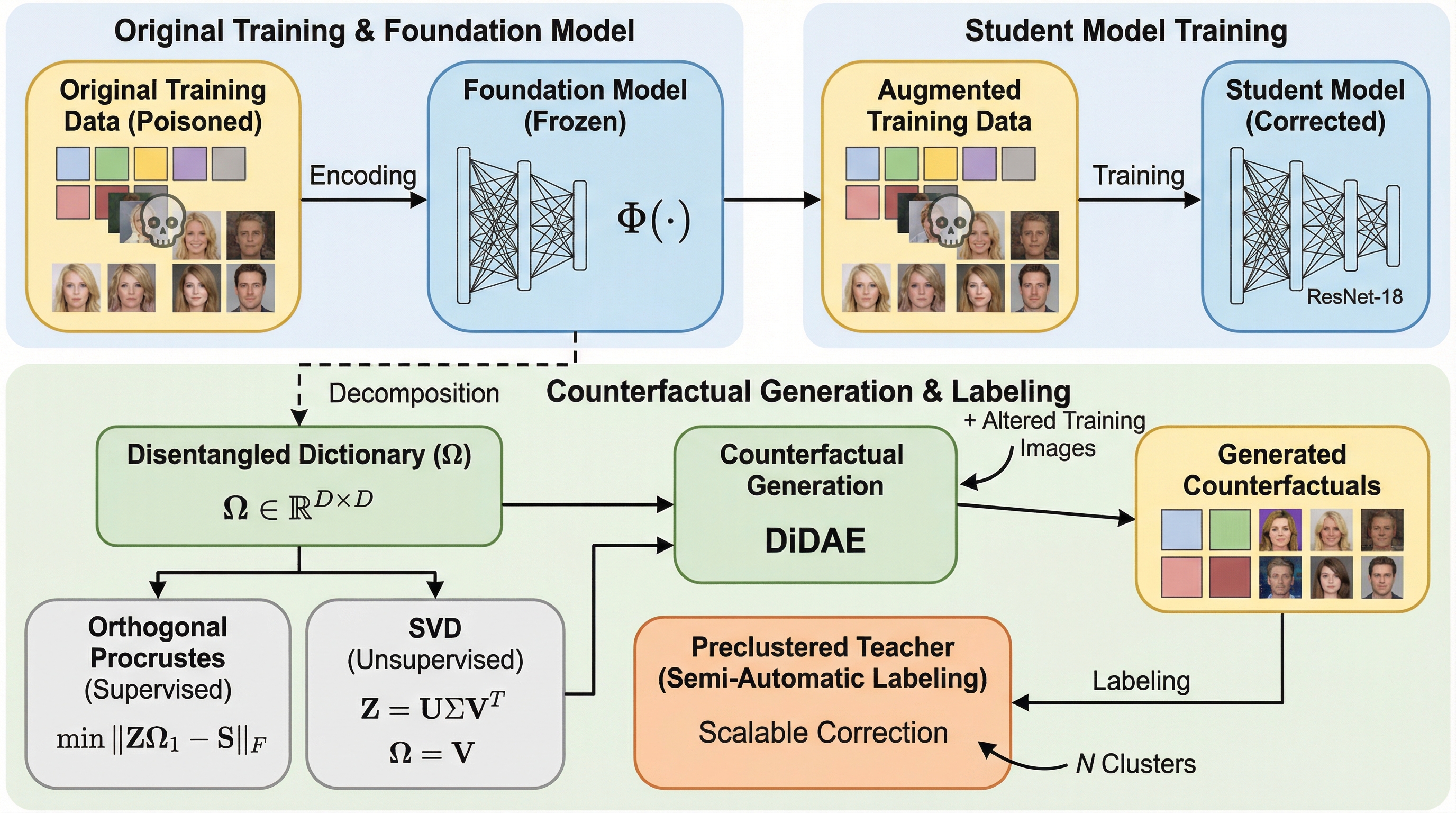
基盤モデルが「賢いハンス」現象や偽の相関に依存する問題を解決するため、視覚的分離拡散オートエンコーダ(DiDAE)が提案されました。この手法は、凍結された基盤モデルの潜在空間を分離辞書学習によって解釈可能な方向に分解し、勾配計算を必要としない高速かつ精密な反事実的画像の生成を可能にします。