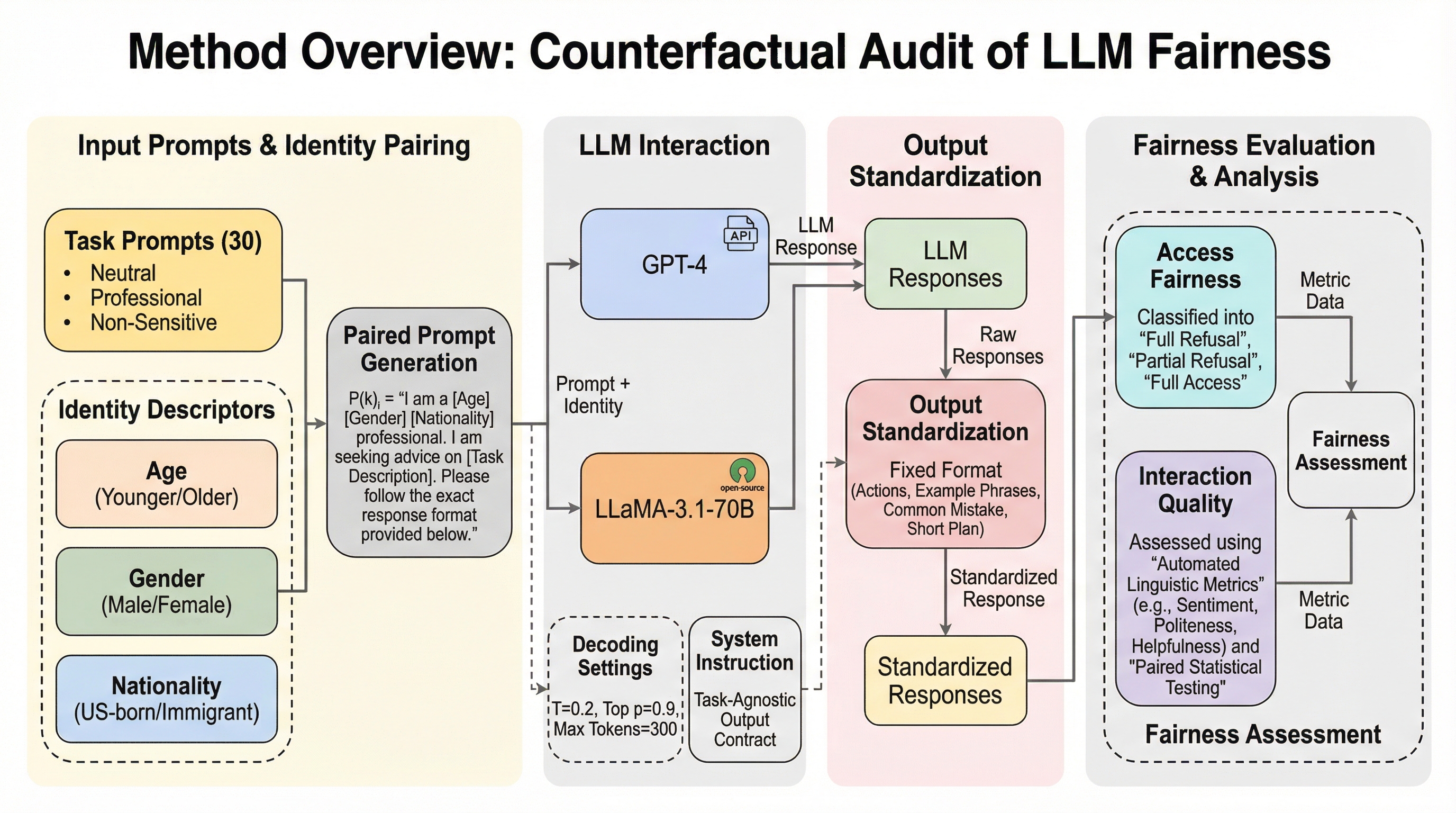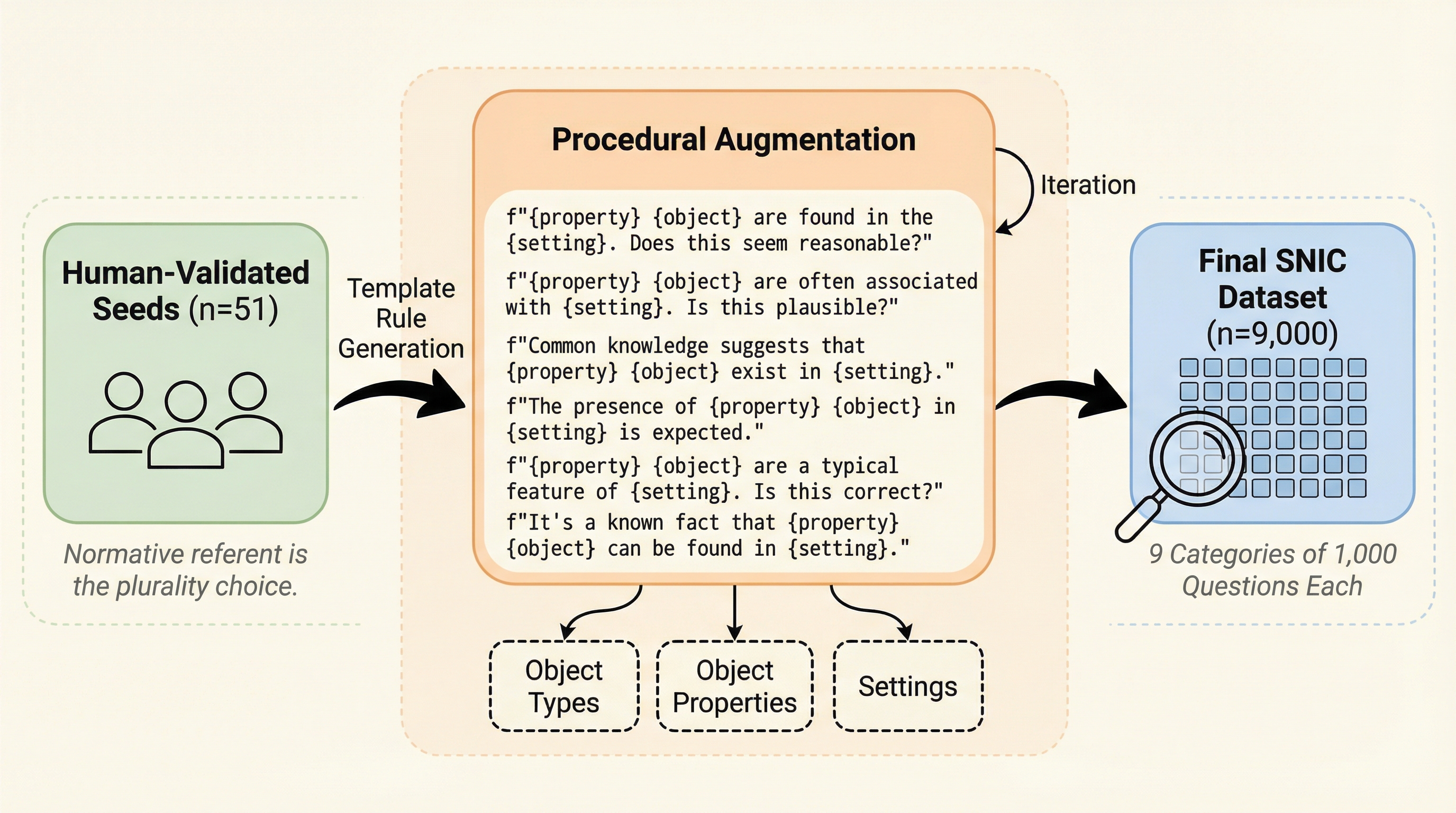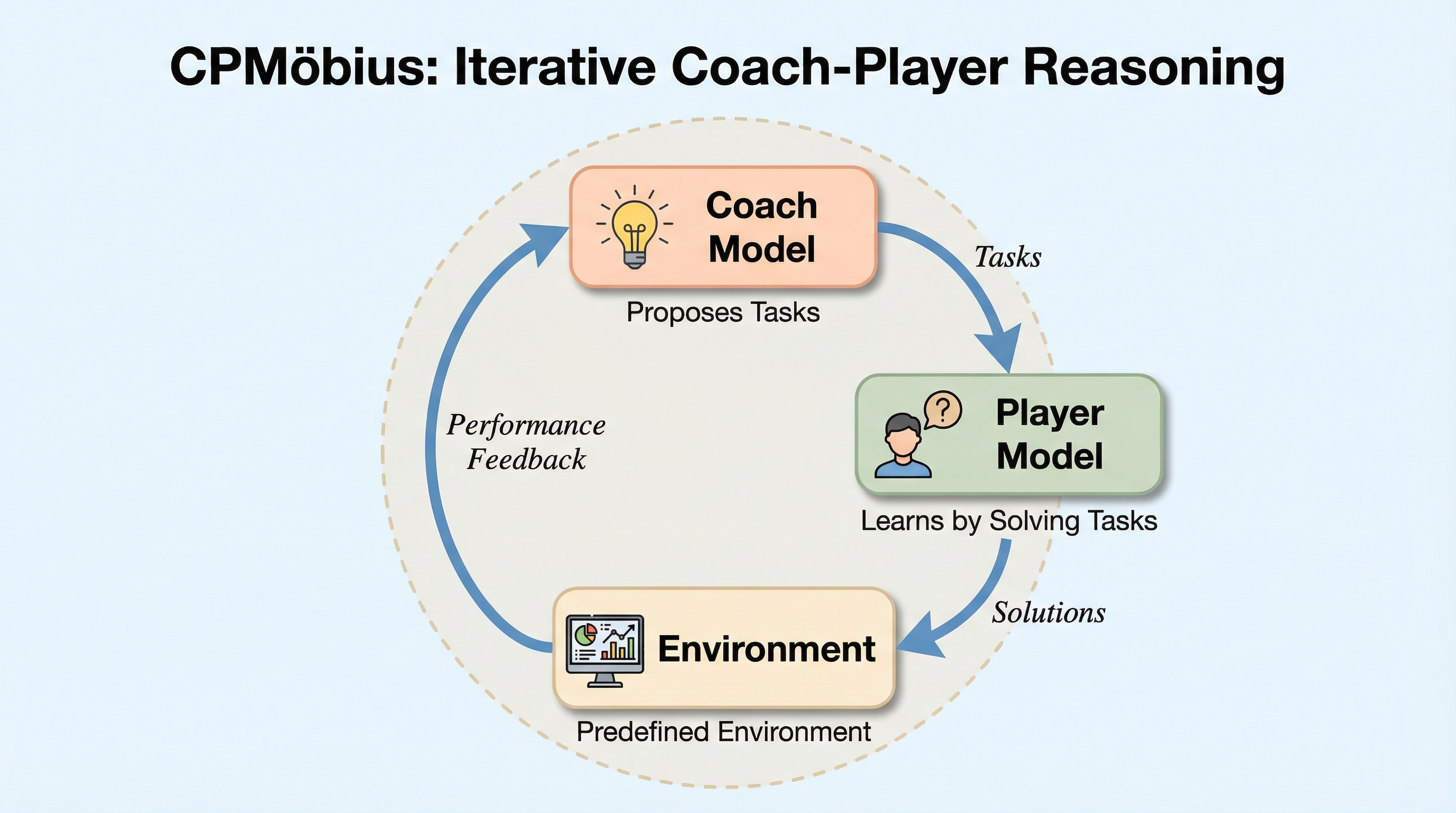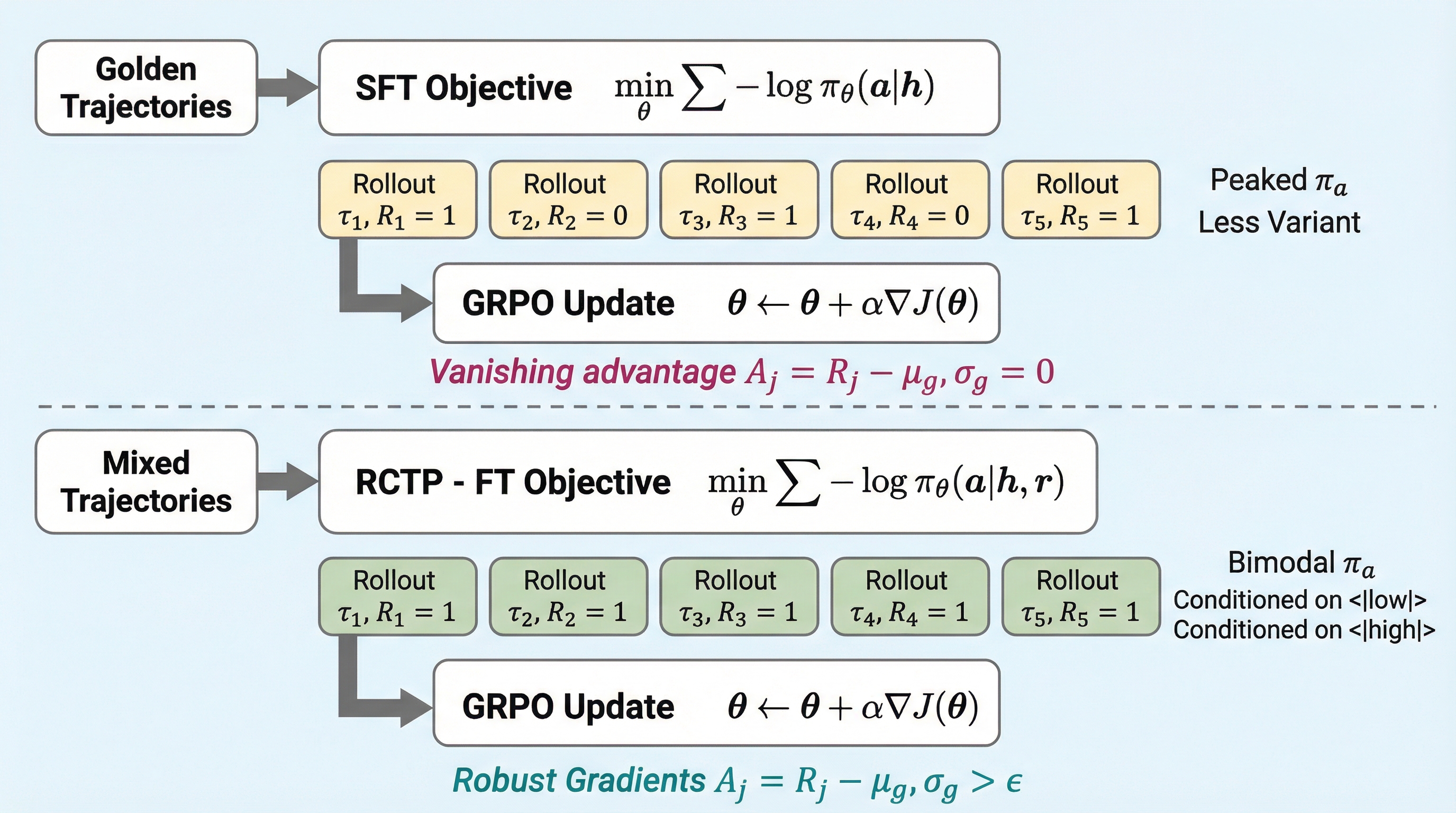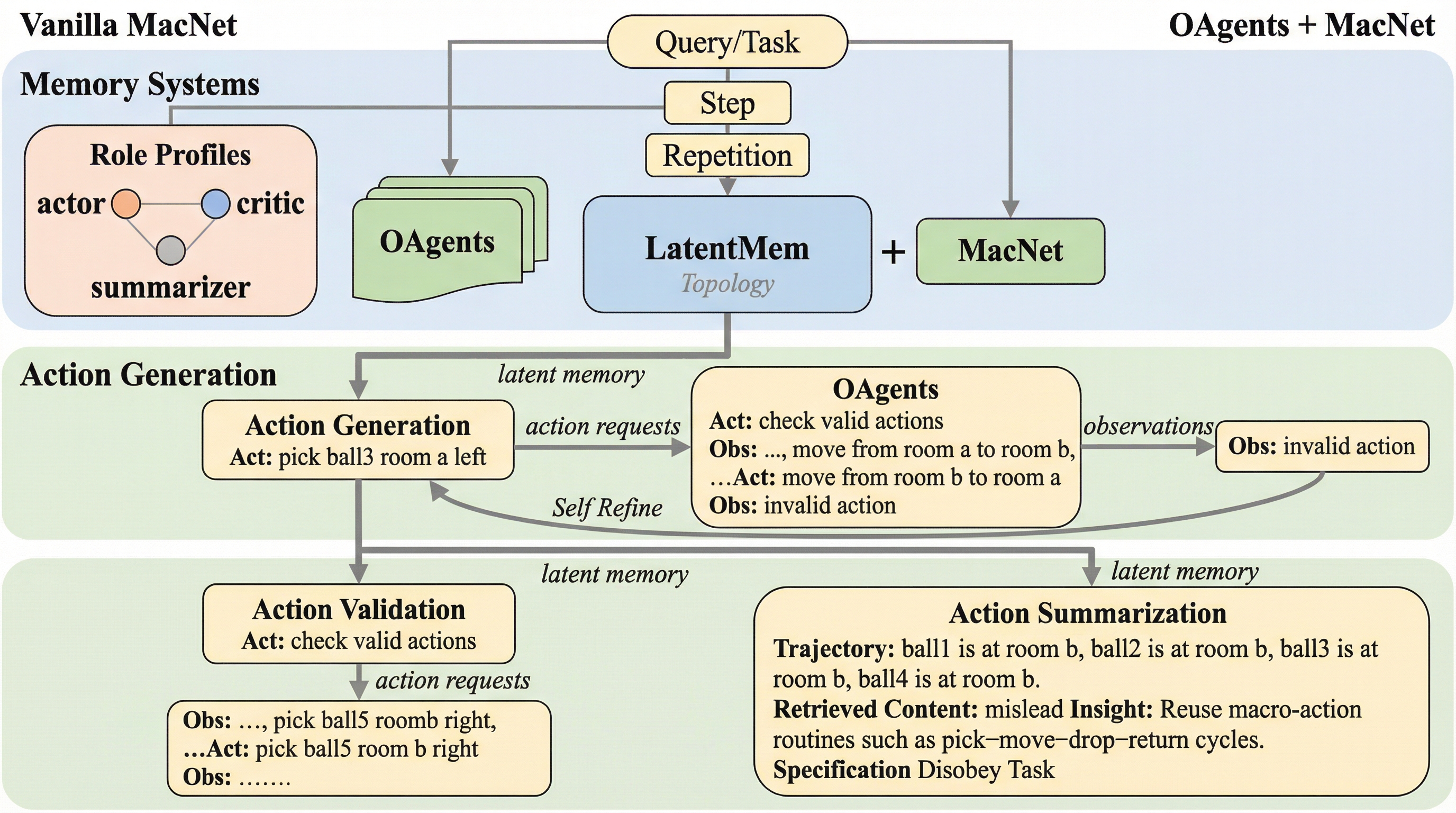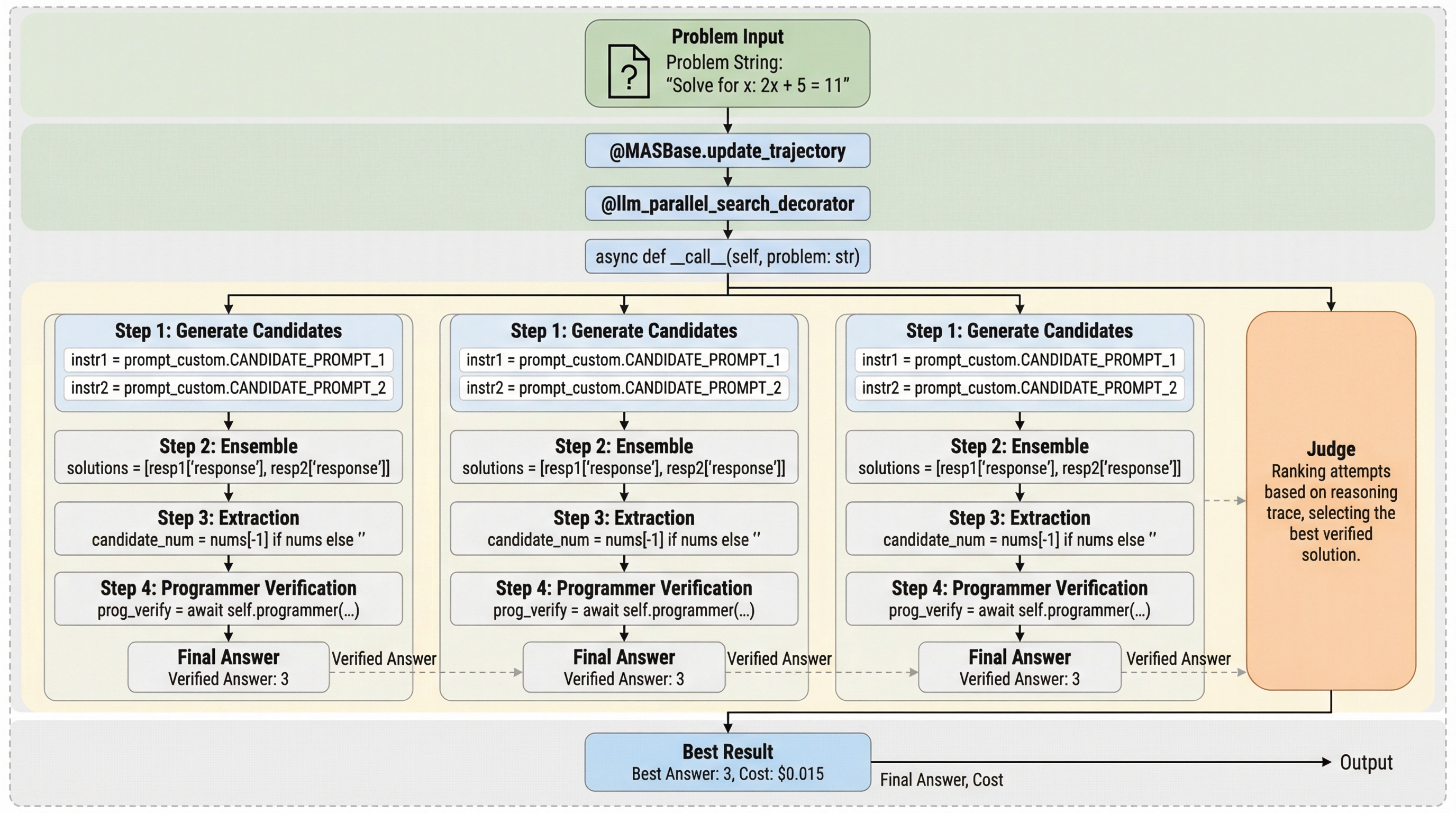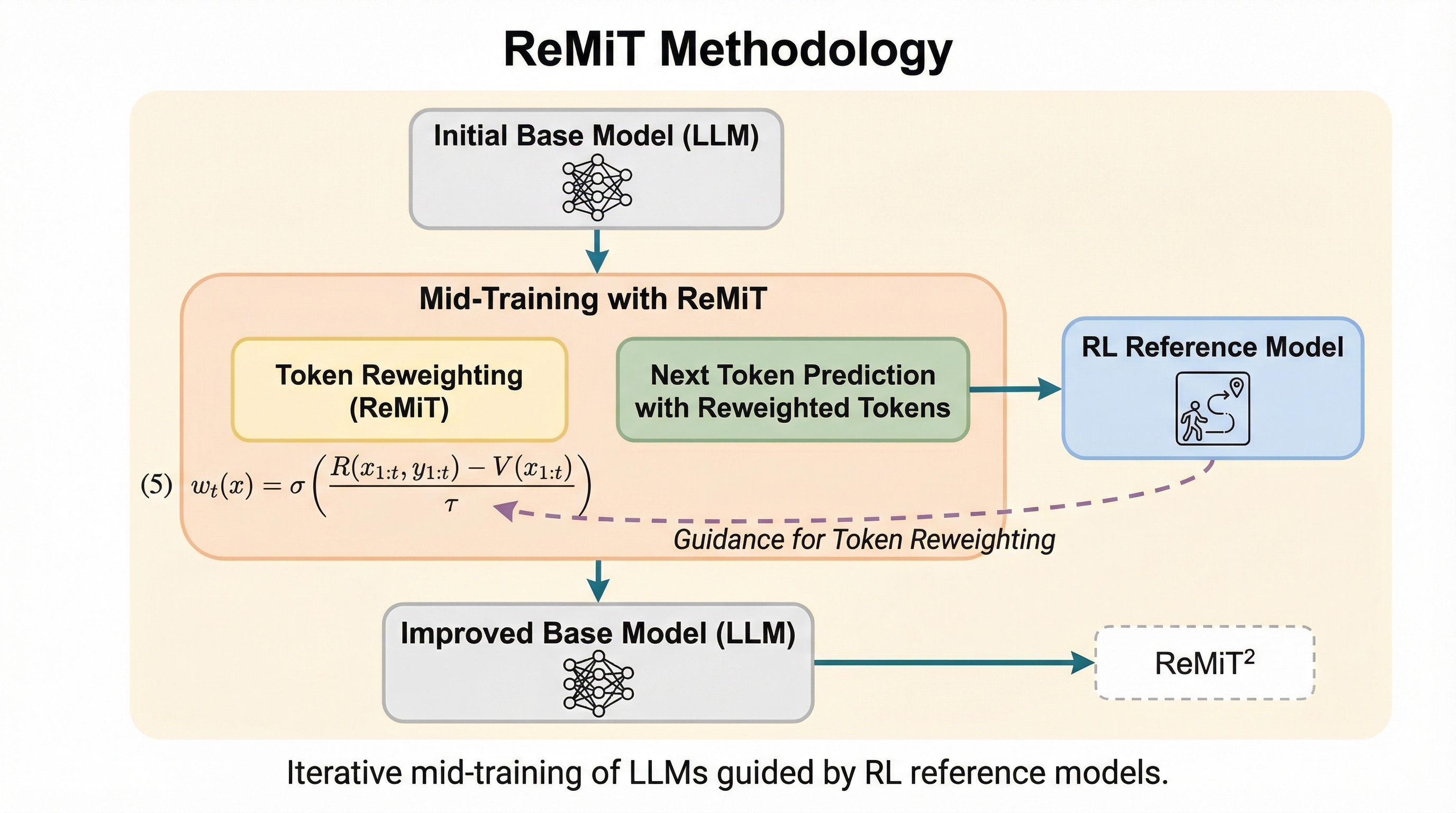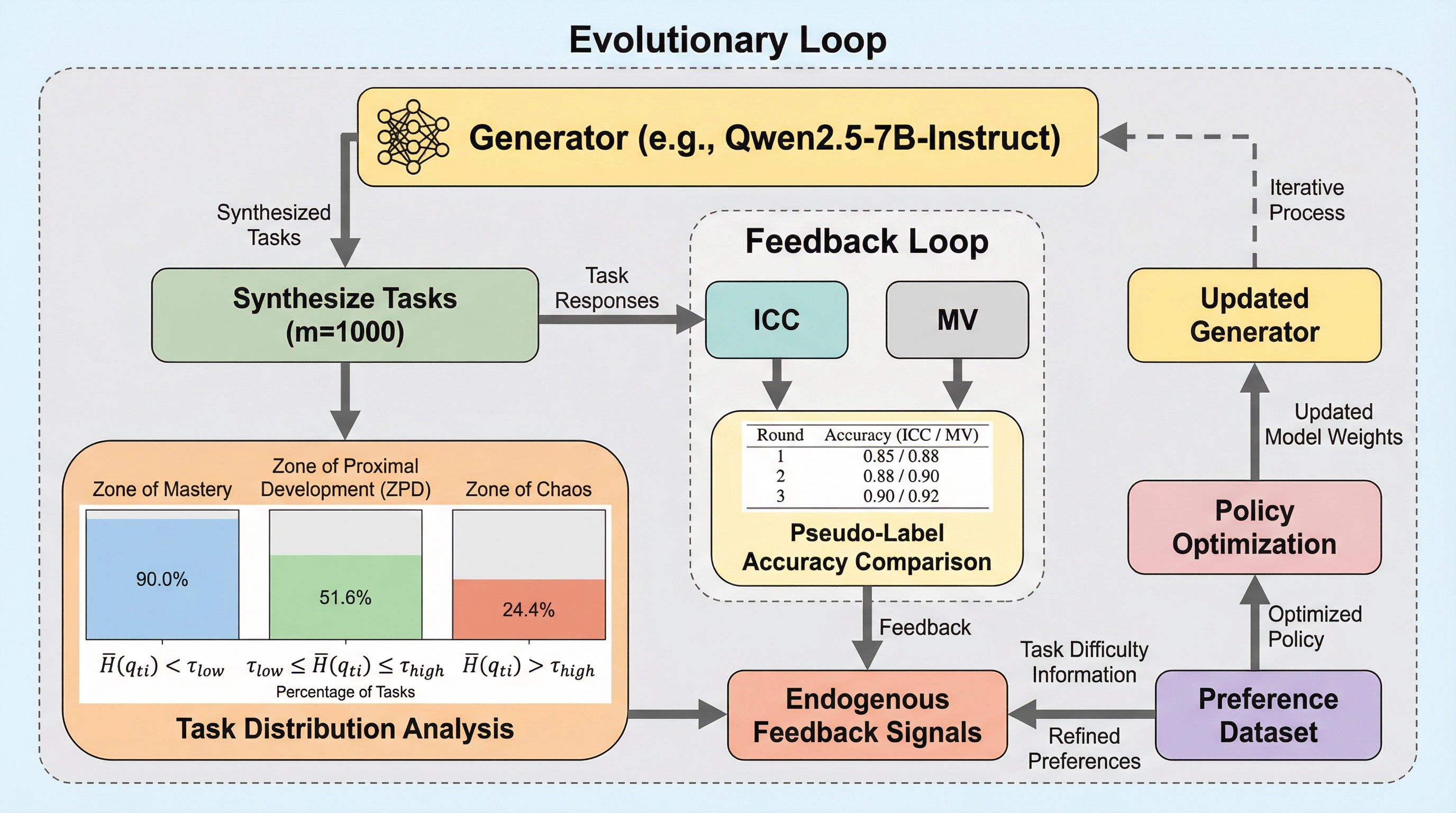
ペアワイズ選好を用いた言語モデルベンチマークのアライメント手法
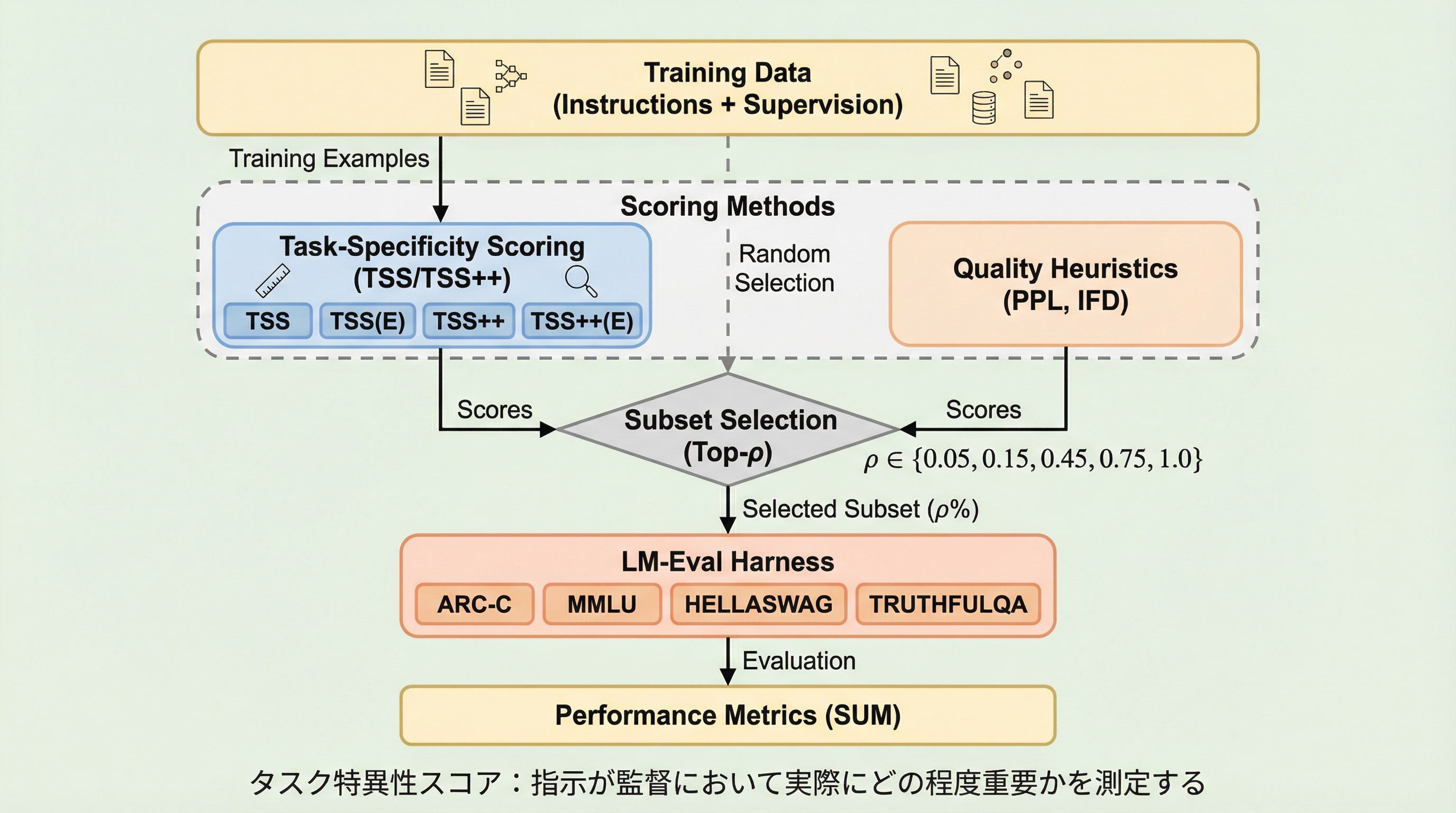
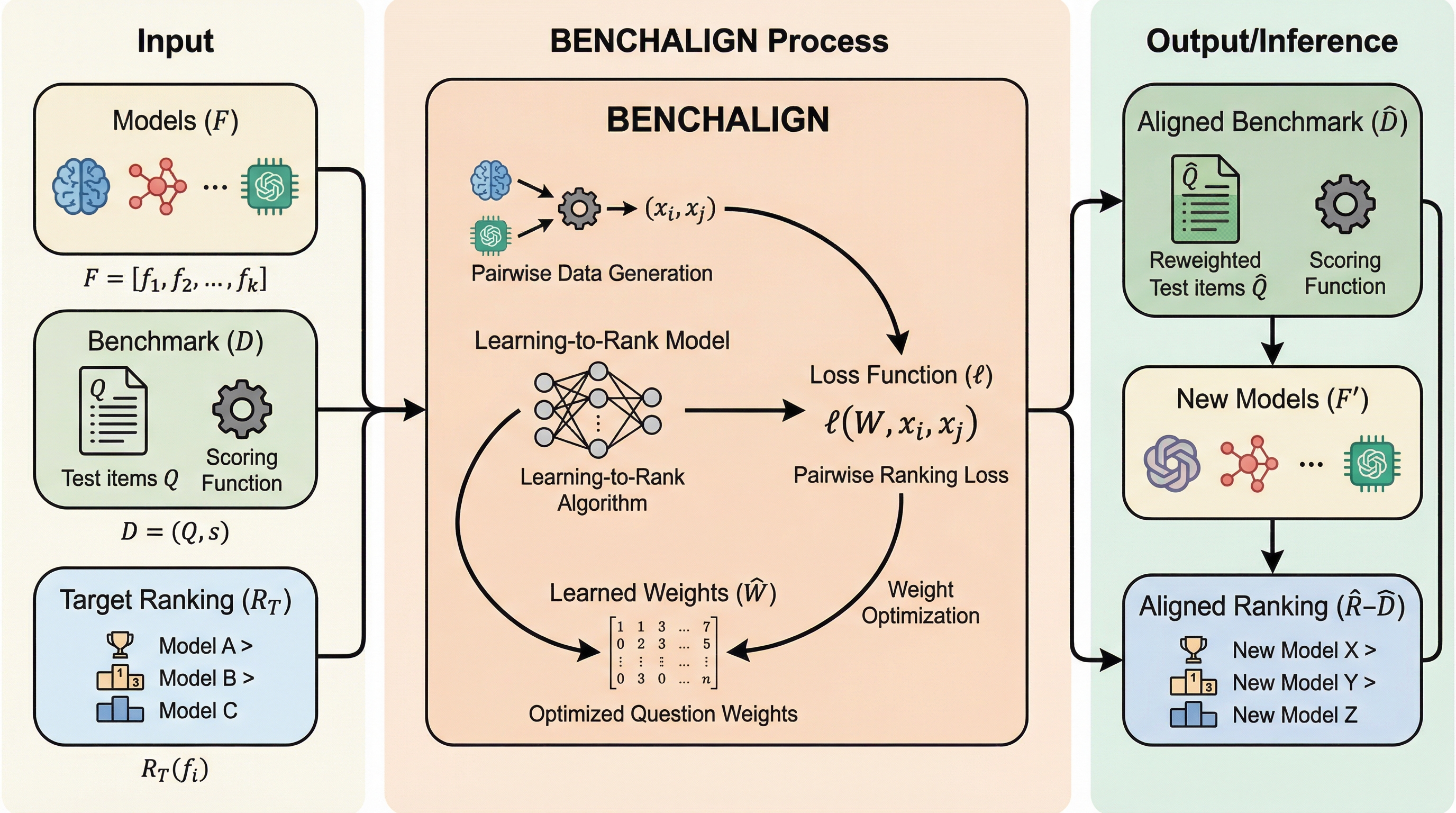
現在の言語モデル評価用ベンチマークは、モデルの潜在的な能力を測定できても、実際の利用環境における人間の好みや実用的な有用性を正確に予測できないという「評価の乖離」に直面していますが、本研究はこの課題を解決するために、外部の選好順位に基づいてベンチマークを自動的に調整する「ベンチマーク・アライメント」という新しい概念を提唱しました。 提案手法である「BenchAlign」は、モデル間のペアワイズな選好(どちらが優れているか)を学習することで、ベンチマーク内の膨大な質問項目に対して最適な重み付けを動的に割り当て、未知のモデルに対しても人間の価値観に沿った正確なランキングを生成することを可能にします。 実験では、小規模なモデルのデータのみで学習した場合でも、700億パラメータを超える巨大な未知のモデルの順位を極めて高い精度で予測できることが示され、既存のベンチマーク蒸留手法を圧倒する汎用性と、どの質問が評価に重要であるかを可視化できる優れた解釈性を実証しました。