inversedMixup: 混合埋め込みの反転によるデータ拡張
inversedMixupは、Mixupが持つ「制御可能な補間」と大規模言語モデル(LLM)が持つ「解釈可能な文章生成」を統合した、新しいテキストデータ拡張フレームワークである。 3段階の学習プロセスを通じてタスク固有モデルの埋め込み空間とLLMの入力空間を精密に整列させることで、混合された潜在的な数値情報を人間が理解できる高品質な文章へと再構成することを可能にしている。 さらに、テキストのMixupにおいて課題となっていた「マニホールド侵入」という現象を初めて実証的に特定し、LLMを活用してラベルを適切に修正することで、学習の堅牢性とモデルの汎用性を大幅に向上させている。
TL;DR(結論)
inversedMixupは、Mixupが持つ「制御可能な補間」と大規模言語モデル(LLM)が持つ「解釈可能な文章生成」を統合した、新しいテキストデータ拡張フレームワークである。 3段階の学習プロセスを通じてタスク固有モデルの埋め込み空間とLLMの入力空間を精密に整列させることで、混合された潜在的な数値情報を人間が理解できる高品質な文章へと再構成することを可能にしている。 さらに、テキストのMixupにおいて課題となっていた「マニホールド侵入」という現象を初めて実証的に特定し、LLMを活用してラベルを適切に修正することで、学習の堅牢性とモデルの汎用性を大幅に向上させている。
なぜこの問題か
ウェブコンテンツの理解や特定の専門ドメインにおける自然言語処理において、ラベル付きデータが不足している「低リソース」な状況は極めて頻繁に発生する課題である。 このような課題を解決するための基本的な技術としてデータ拡張が存在するが、既存の手法には大きく分けて二つの対立する課題があった。 一つは、Mixupに代表される伝統的なデータ拡張手法である。 Mixupは、入力とラベルを特定の比率で線形補間することによって新しいサンプルを生成する手法であり、モデルの汎用性向上や決定境界の平滑化に大きく寄与することが知られている。 しかし、テキストデータは離散的な性質を持つため、Mixupは通常、目に見えない潜在的な埋め込みレベルで実行される。 その結果、生成された中間的なサンプルは人間にとって解釈不可能であり、合成された文章が意味的に一貫性を欠いている可能性があるという問題が長年指摘されてきた。 もう一つは、大規模言語モデル(LLM)に基づいたデータ拡張手法である。 LLMベースの手法は、プロンプトを通じてトークンレベルで文章を生成するため、出力される文章は人間にとって読みやすく、豊かな意味を持つ。…
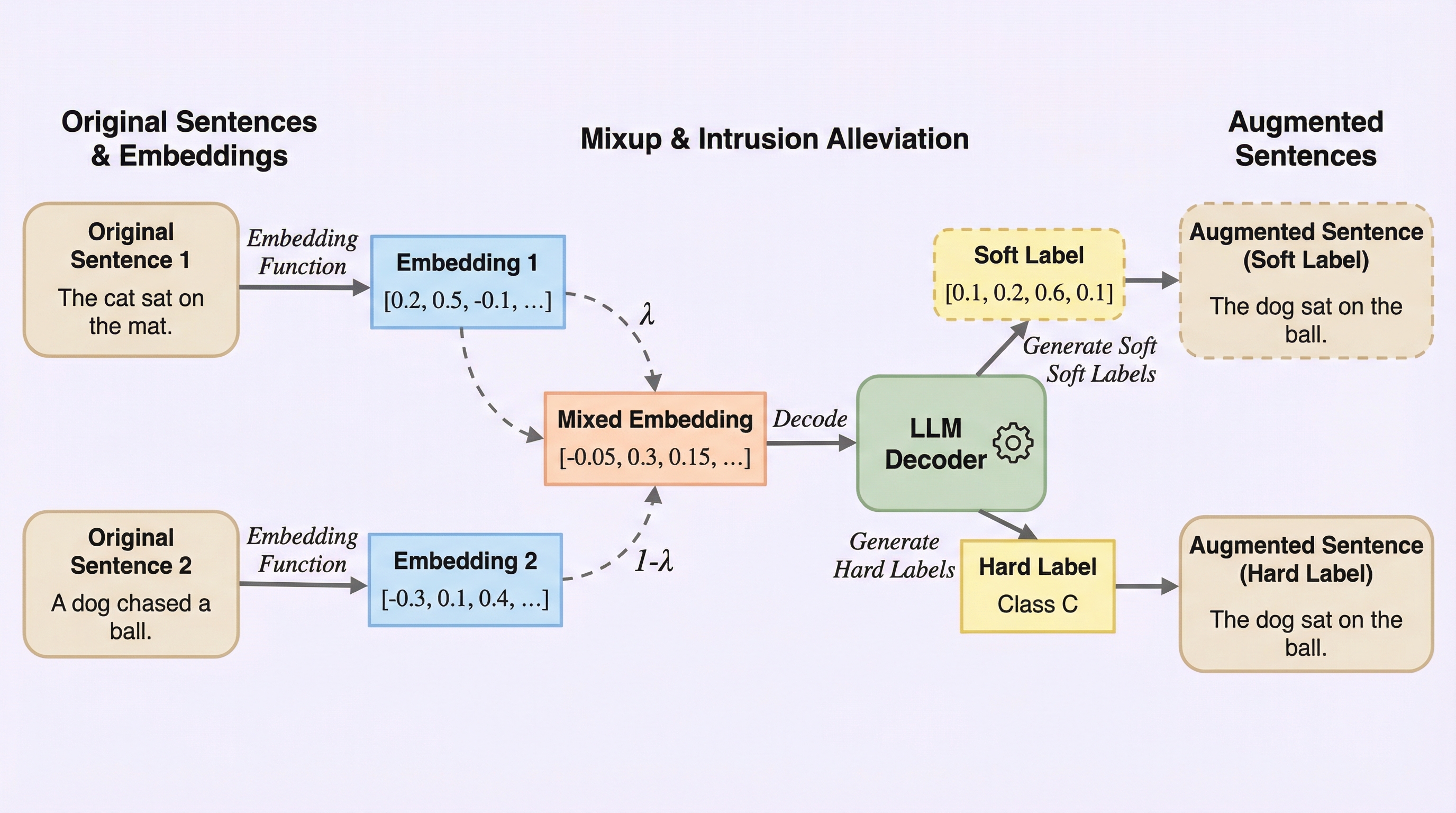
核心:何を提案したのか
本論文では、Mixupの制御性とLLM生成の解釈性を組み合わせた統一フレームワークである「inversedMixup」を提案している。 この手法の核心は、LLM反転(LLM inversion)と呼ばれる技術を応用し、埋め込みから自然言語を再構成することで、潜在空間とトークン空間の橋渡しを行う点にある。 具体的には、タスク固有のモデルが生成した埋め込みを、LLMが理解できる形式に変換し、そこから人間が読める文章を復元する。 これにより、Mixupによって生成された「混合された埋め込み」を、単なる数値の羅列ではなく、具体的な文章として可視化し、学習に利用することが可能になった。 inversedMixupは、タスク固有モデルの出力埋め込み空間と、LLMの入力埋め込み空間を整列させるための「アダプタ」を導入している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related