inversedMixup: 混合埋め込みの反転によるデータ拡張
inversedMixupは、埋め込み空間での線形補間を行うMixupの精密な制御性と、大規模言語モデル(LLM)によるトークンレベル生成の解釈性を統合した、新しいデータ拡張フレームワークである。
TL;DR(結論)
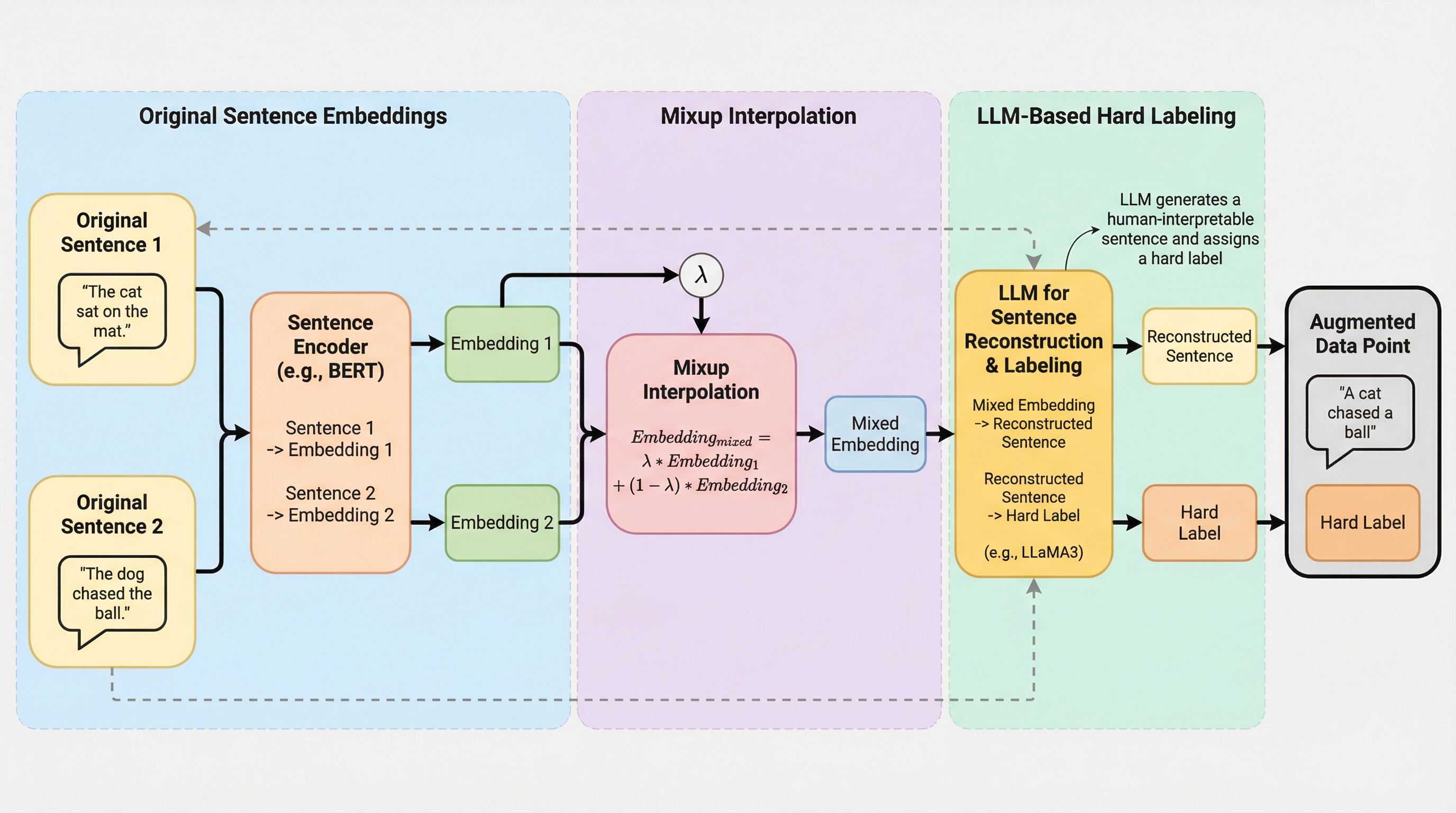
inversedMixupは、埋め込み空間での線形補間を行うMixupの精密な制御性と、大規模言語モデル(LLM)によるトークンレベル生成の解釈性を統合した、新しいデータ拡張フレームワークである。 タスク固有モデルの出力空間とLLMの入力空間をアダプターで接続する3段階の学習手順を導入し、数学的に混合された埋め込みから、人間が理解可能な自然言語の文章を再構築することに成功した。 テキストにおけるマニホールド・イントルージョン現象を初めて実証的に特定し、LLMを用いて生成された文章に新しいラベルを割り当てることでこの問題を軽減し、モデルの性能と汎化性能を大幅に向上させた。
なぜこの問題か
ウェブコンテンツの理解や特定の専門ドメインにおける自然言語処理では、学習データが極めて少ない低リソースな状況に直面することが少なくない。このような課題を解決するためにデータ拡張は不可欠な技術であるが、既存の手法には制御性と解釈性のトレードオフという大きな課題が存在していた。伝統的な手法の一つであるMixupは、入力データとラベルを特定の比率で線形補間することで、モデルの決定境界を滑らかにし、堅牢性を高めることができる。しかし、テキストデータにおいてMixupは潜在的な埋め込みレベルで操作されるため、合成された結果がどのような意味を持つのかを人間が直接確認することは不可能であった。 一方で、近年の大規模言語モデル(LLM)を用いた拡張手法は、プロンプトを通じて自然な文章を生成するため、出力結果の読みやすさや意味的な豊かさには優れている。しかし、LLMの生成プロセスは確率的であり、特定の比率で情報を混ぜ合わせるといった精密な制御を行うことは困難である。つまり、Mixupは埋め込み空間での数学的な操作により高い制御性を持つが解釈性に欠け、LLMベースの手法は解釈性は高いが制御性が制限されているという対照的な特徴を持っていた。…
核心:何を提案したのか
本研究では、Mixupの制御性とLLM反転の解釈性を統合した新しいフレームワークである「inversedMixup」を提案した。この手法の核心は、2つの異なる文章の埋め込みを任意の比率で混合し、その混合された「中間的な意味を持つ埋め込み」をLLMに読み込ませることで、対応する自然言語の文章を生成させる点にある。これにより、従来はブラックボックスであったMixupの補間プロセスが可視化され、人間が内容を確認できる高品質な拡張サンプルを生成することが可能になった。 inversedMixupを実現する上での最大の技術的課題は、Mixupを実行するタスク固有モデル(例えばBERTなど)の出力埋め込み空間と、文章を生成するLLMの入力埋め込み空間をいかにして精密に整列させるかという点である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related