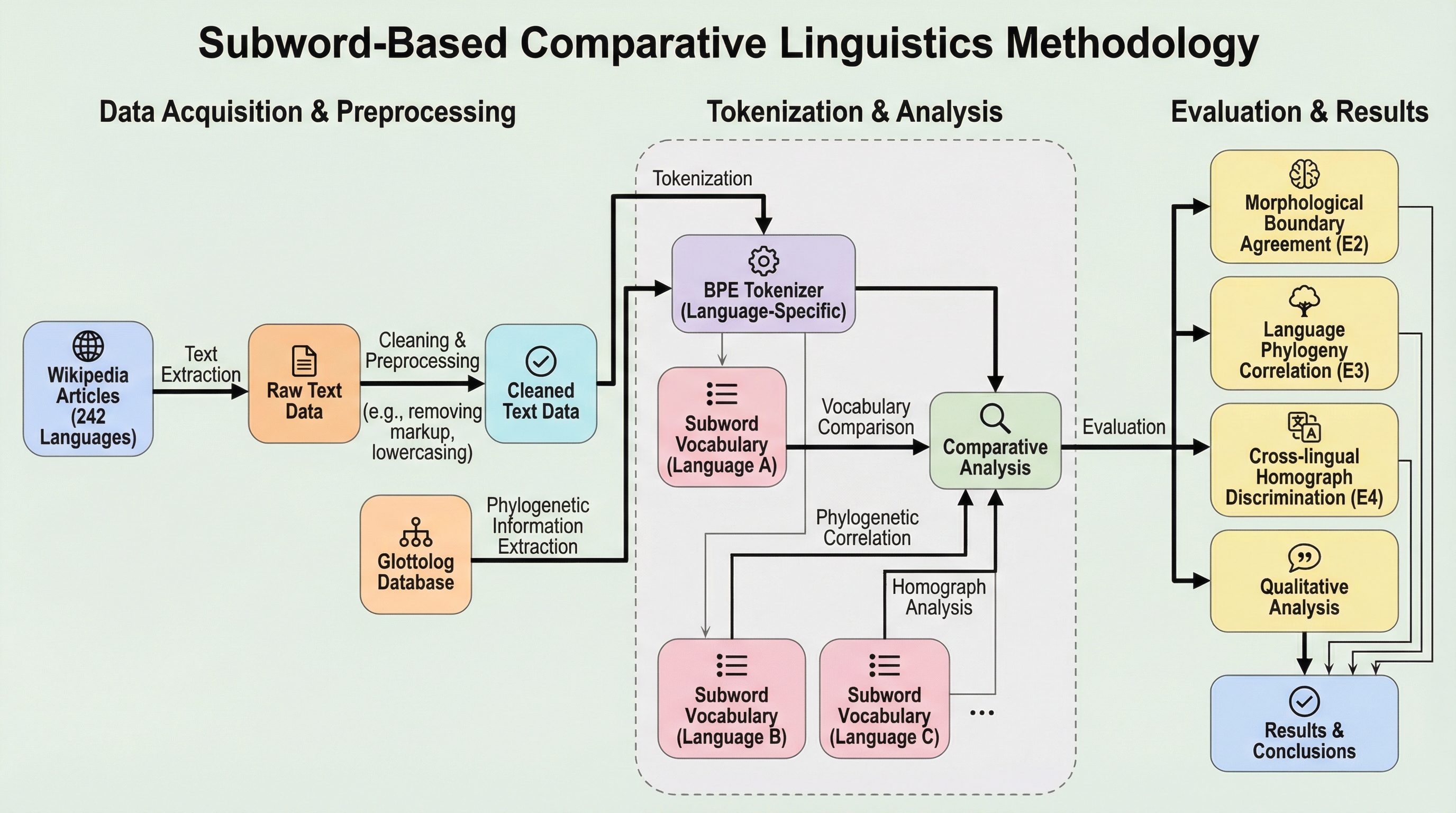
Wikipedia Glottosetを用いた242言語にわたるサブワードベースの比較言語学
本研究は、Wikipediaの語彙データから構築した「glottoset」を活用し、ラテン文字とキリル文字を使用する242言語を対象に、Byte-Pair Encoding(BPE)を用いた大規模な比較言語学のフレームワークを提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、Wikipediaの語彙データから構築した「glottoset」を活用し、ラテン文字とキリル文字を使用する242言語を対象に、Byte-Pair Encoding(BPE)を用いた大規模な比較言語学のフレームワークを提案した。
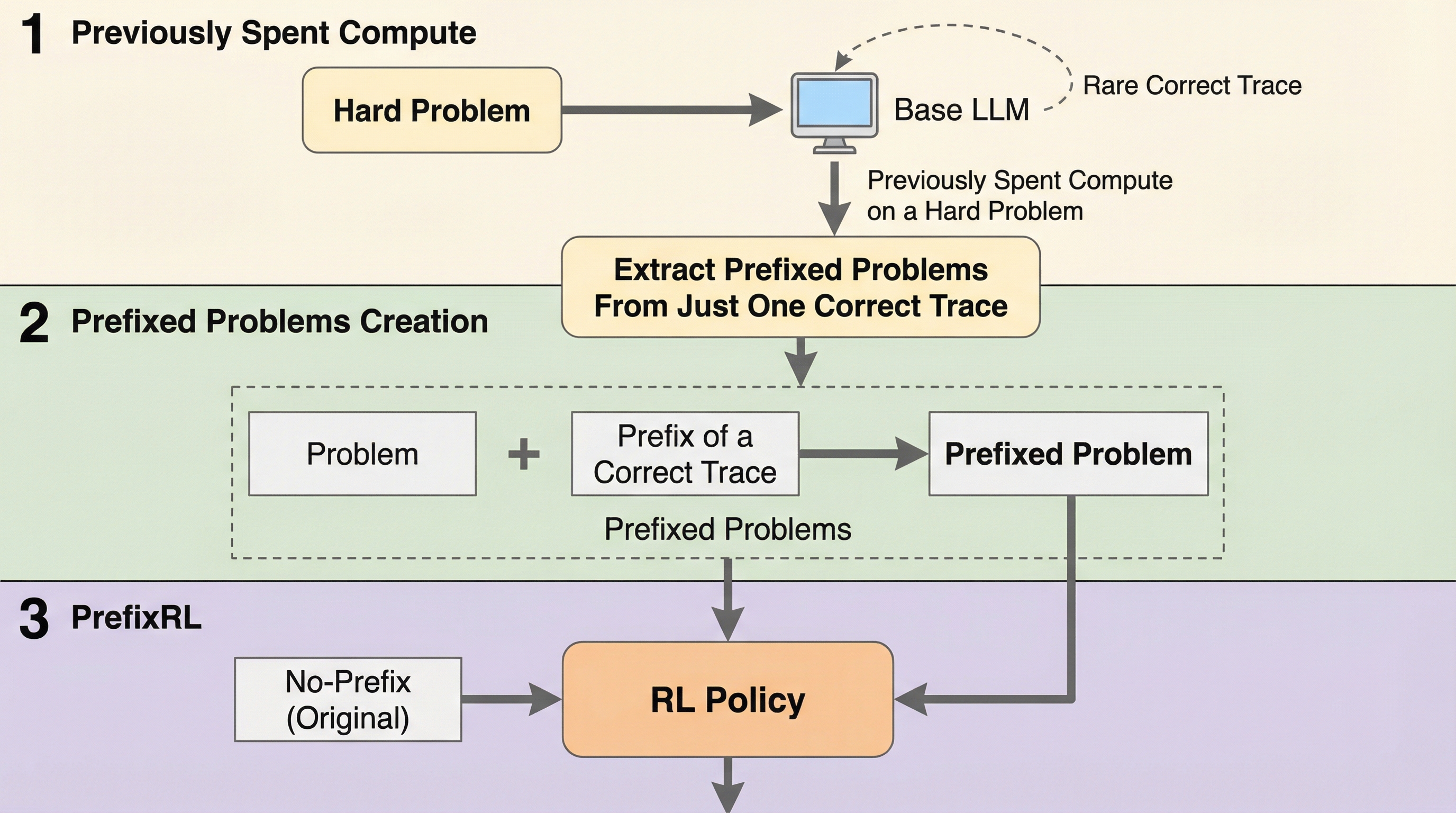
大規模言語モデルの数学やコーディング等の難問解決において、正解が稀なために学習が停滞する課題に対し、過去の成功トレースの冒頭部分を「プレフィックス」として与えることでオンポリシー学習を導く新手法「PrefixRL」を提案しました。
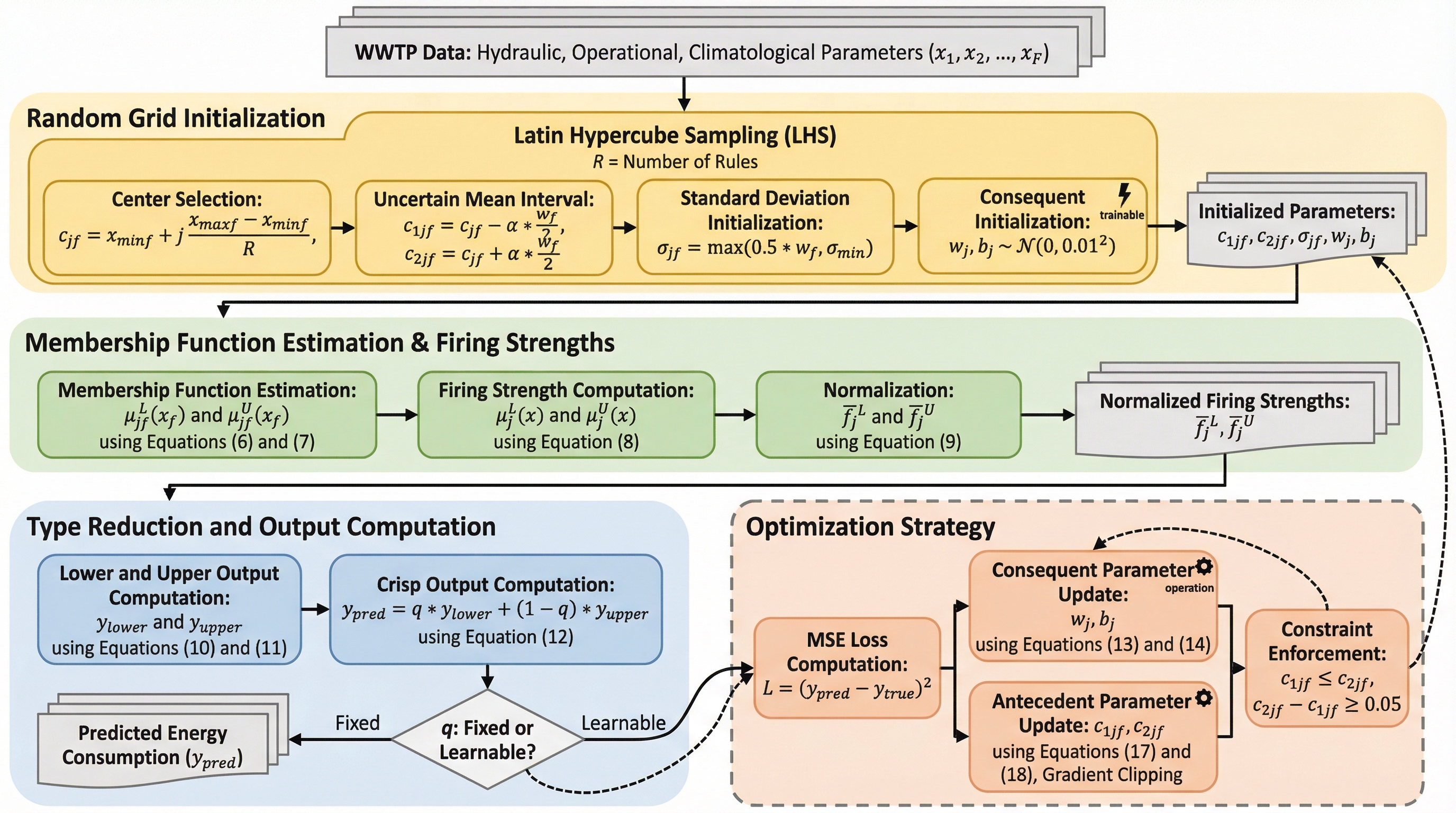
世界全体の電力の1〜3%を消費する下水処理施設において、持続可能な運用のために高精度な電力需要予測が不可欠ですが、従来の機械学習モデルは点予測に留まり、意思決定の根拠となる不確実性を説明する能力が不足していました。
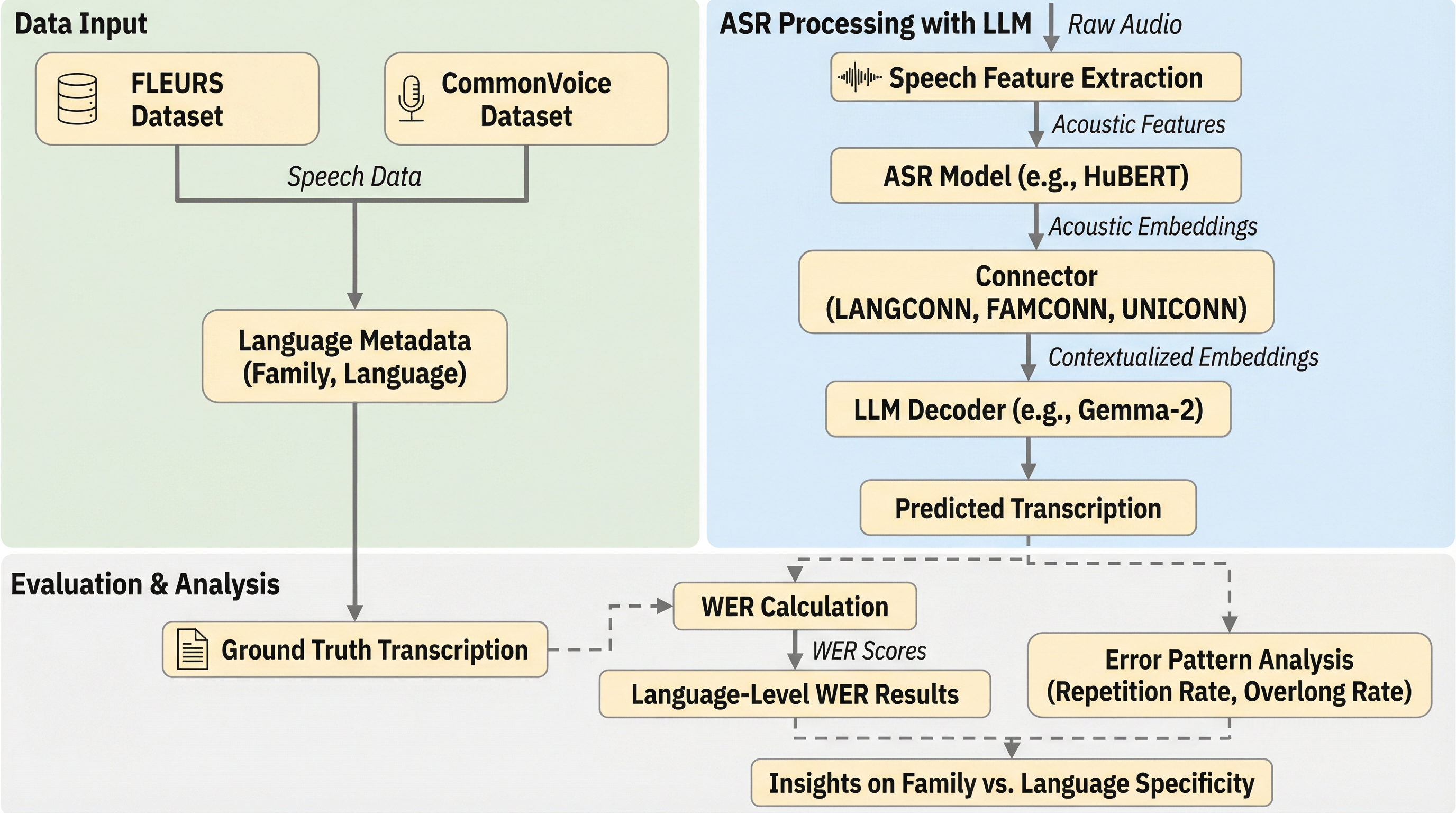
大規模言語モデル(LLM)を活用した自動音声認識(ASR)において、個別の言語ごとに接続モジュール(コネクタ)を学習させる従来の手法に対し、言語的な類似性に基づいた「語族」単位でコネクタを共有する新しい戦略を提案した。
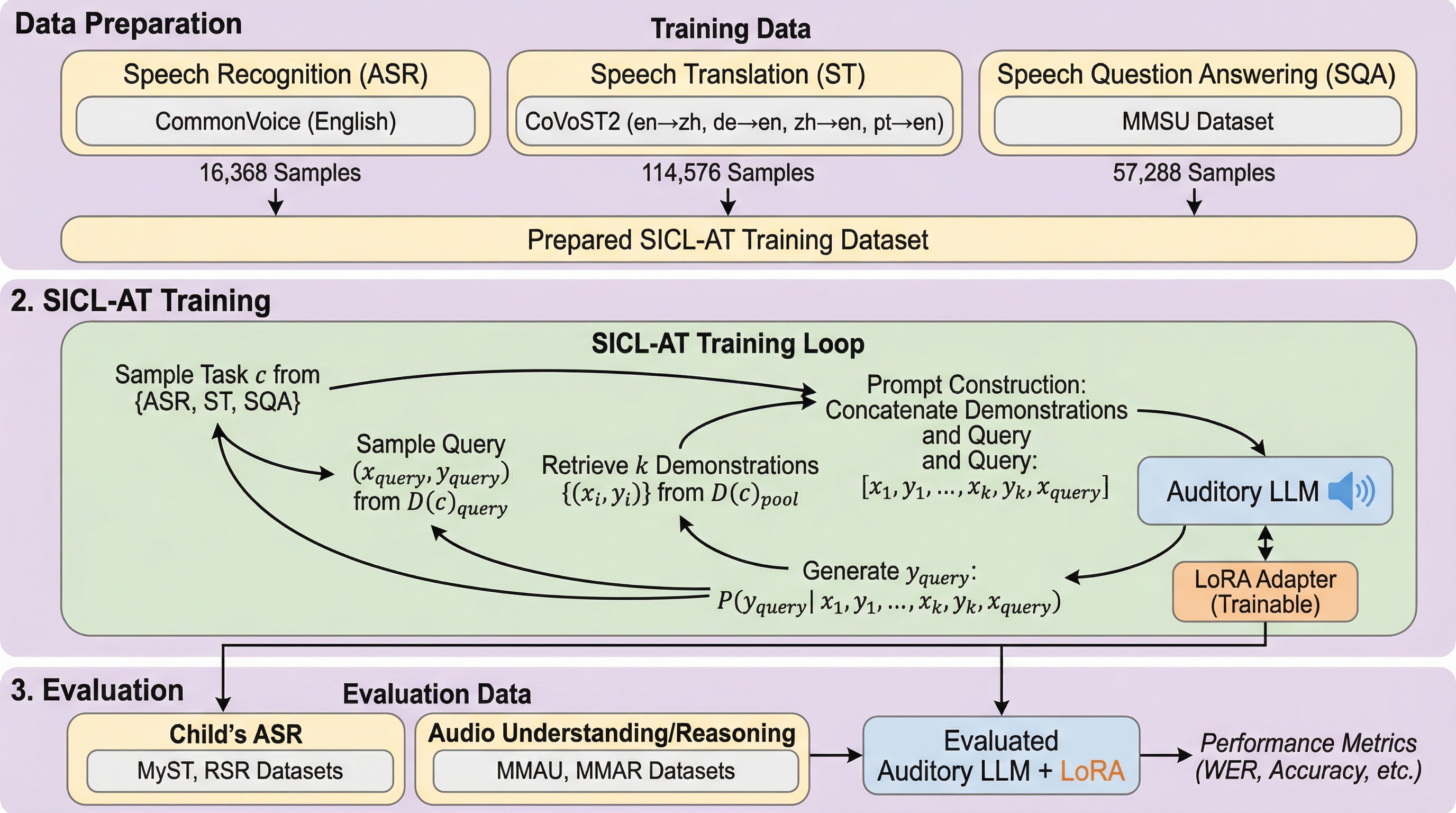
聴覚大規模言語モデル(Auditory LLM)は、子供の音声認識や複雑な音声推論といったデータが乏しい低リソースタスクにおいて、直接的な微調整を行うと過学習や分布の不一致により性能が不安定になるという課題を抱えています。
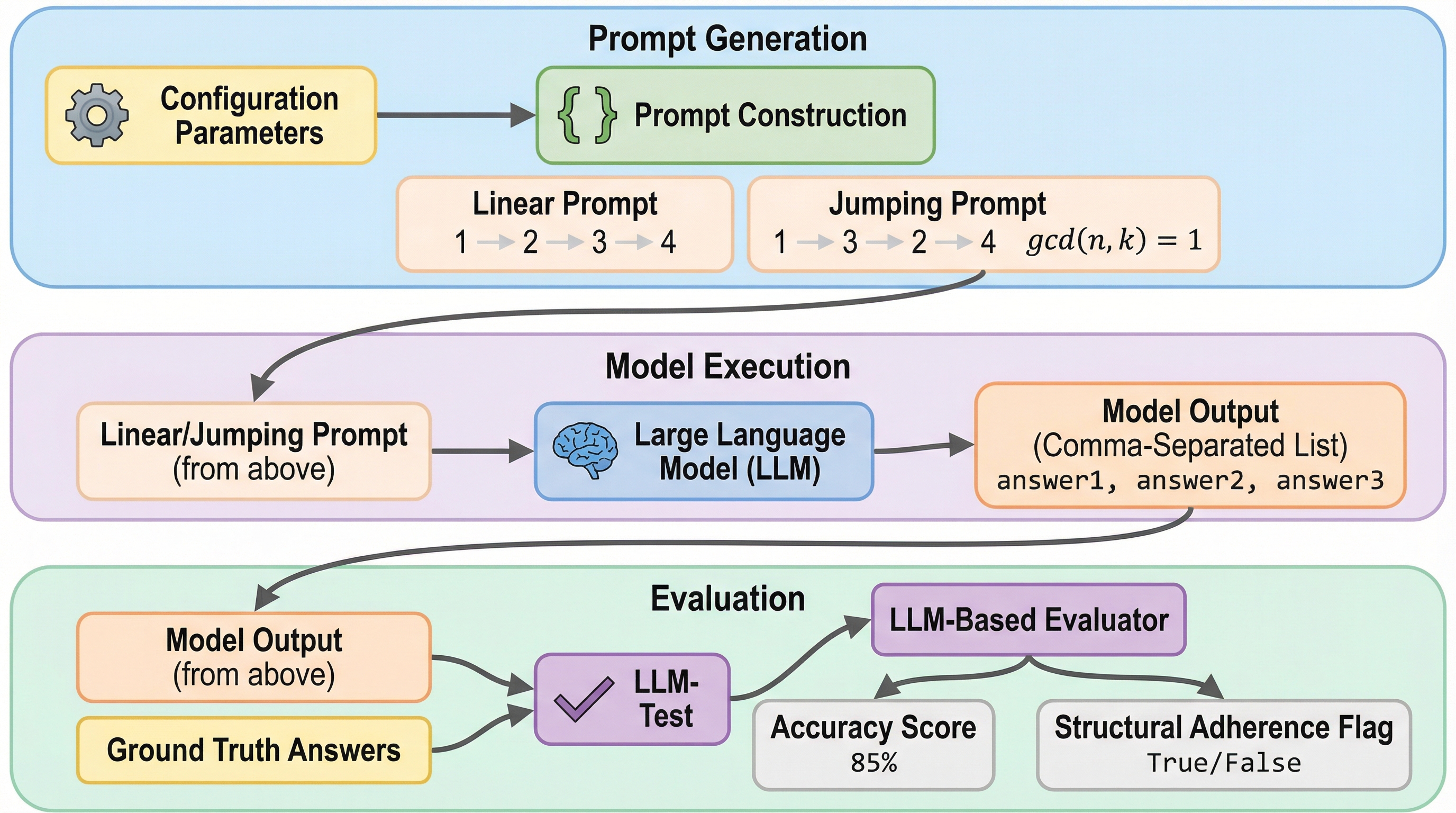
大規模言語モデル(LLM)が複雑な指示に従う能力を、タスクの難易度や内容から構造的な配置を切り離して精密に評価するための新しいベンチマークフレームワーク「RIFT」が提案されました。 テレビ番組のクイズを基にしたデータセットを用い、順番通りに回答する「線形プロンプト」と、指示に従って非連続な順序で回答を求める「ジャンププロンプト」の二つの構造でモデルの性能を比較検証しています。 最新の高性能モデルであっても、非連続な指示条件下では正解率が最大で72%も低下し、モデルが指示を論理的な推論スキルとしてではなく、単なる逐次的なパターンの継続として処理しているという構造的な脆弱性が明らかになりました。
本研究は、隠れ状態を持つシステムの動態を学習するため、予測状態表現(PSR)とテンソル分解の手法を統合し、一部の行動がフルランクであれば離散的な部分観測マルコフ決定過程(POMDP)のパラメータを推定できる新しい枠組みを提案している。
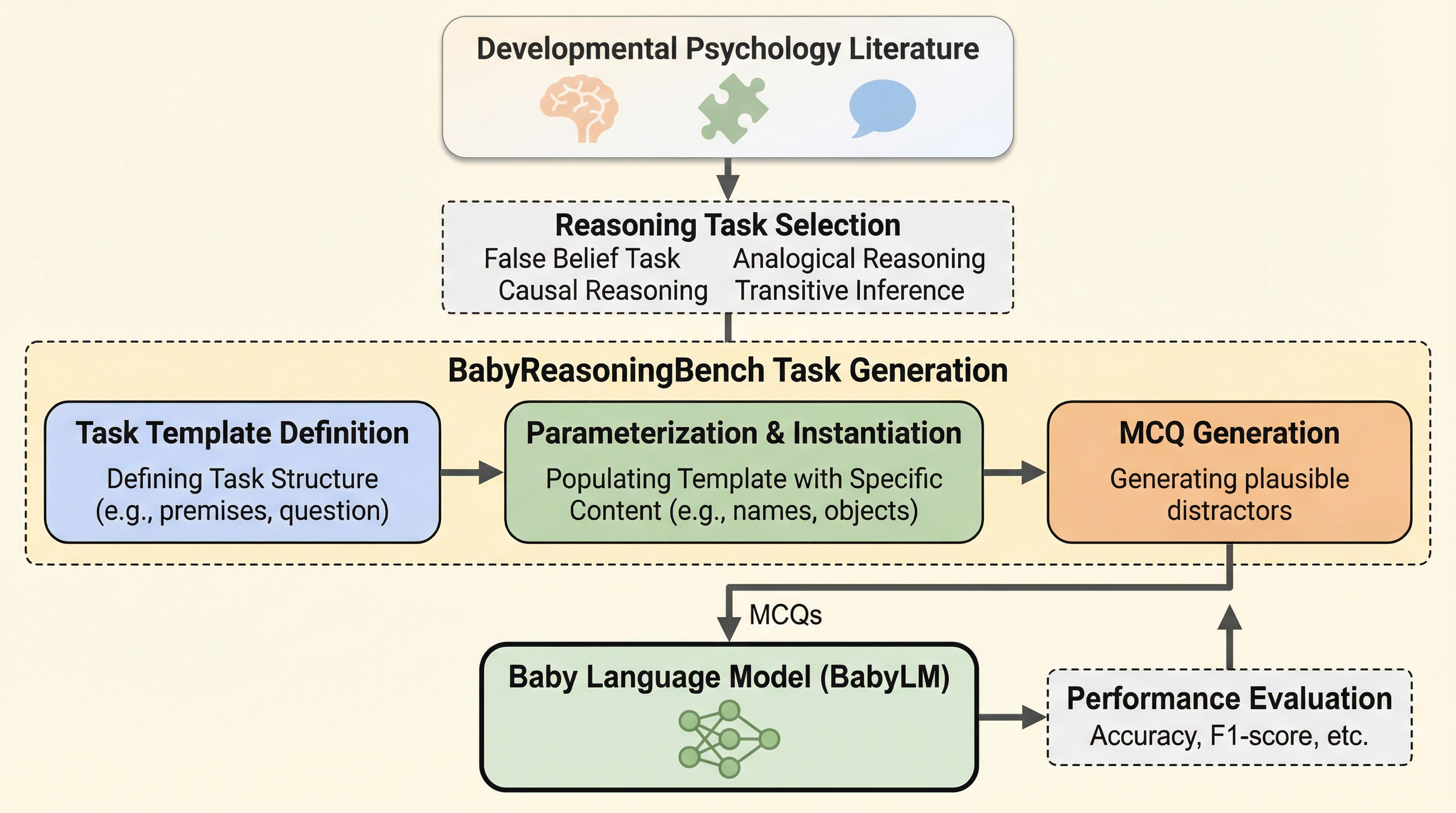
従来の言語モデル評価は成人の知識や複雑な指示への追従を前提としていましたが、本研究では乳幼児の認知発達の軌跡に着想を得た新しい評価指標「BABYREASONINGBENCH」を提案しました。 このベンチマークは、心の理論、類推、因果推論、基本的な推論プリミティブの4つの領域にわたる19のタスクで構成されており、子供向けの発話データなどで学習された「赤ちゃん言語モデル」の能力を精密に測定します。 実験の結果、学習データの規模を拡大することで物理的・因果的な推論能力は向上するものの、他者の信念の理解や語用論的な判断を要する課題は依然として困難であり、能力の出現には不均一なパターンがあることが明らかになりました。
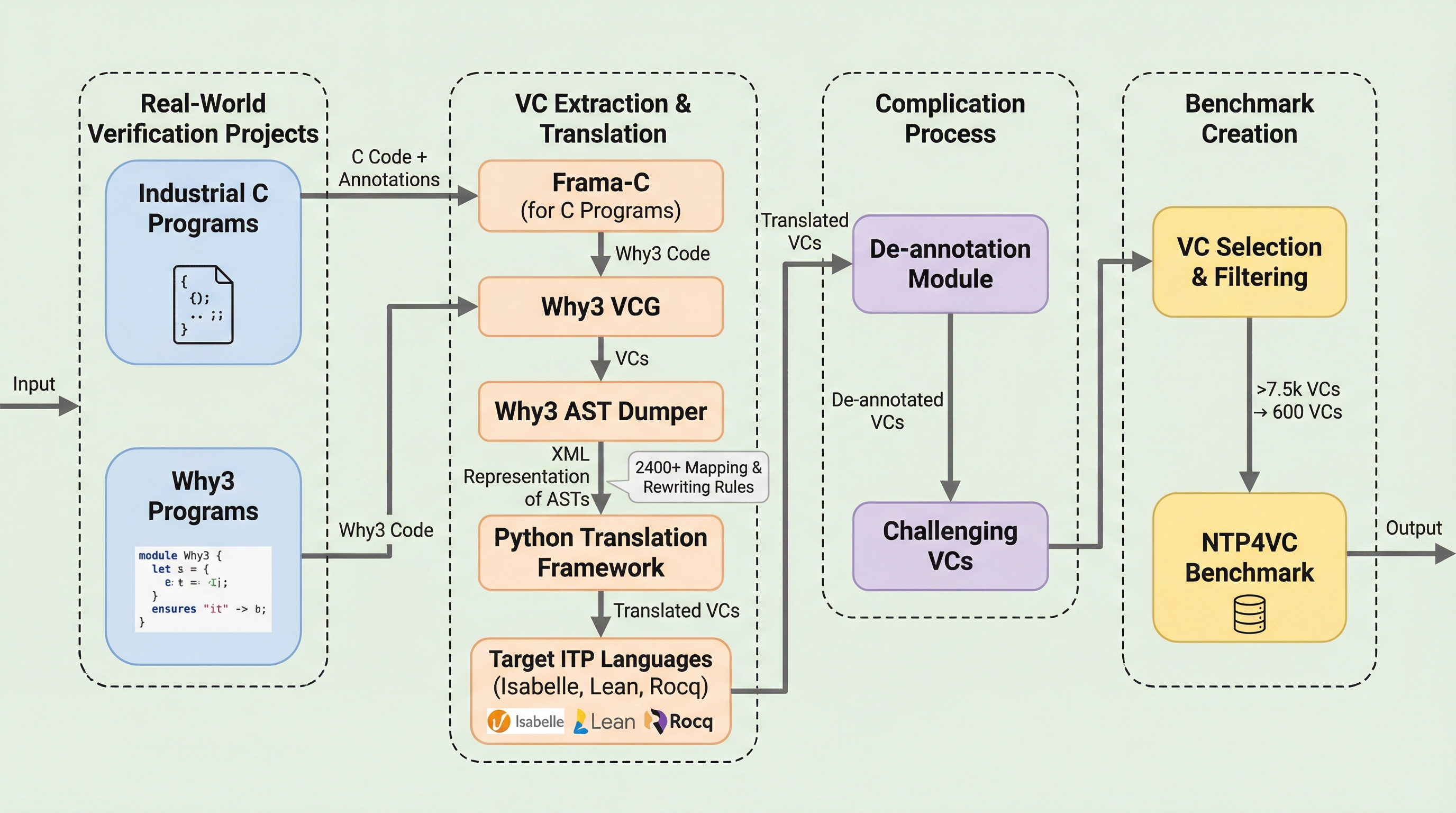
ソフトウェアの信頼性を数学的に保証するプログラム検証において、最大の難所である「検証条件(VC)」の自動証明を解決するため、機械学習を用いたニューラル定理証明(NTP)を実世界の複雑なコードに適用する初のベンチマーク「NTP4VC」を構築した。
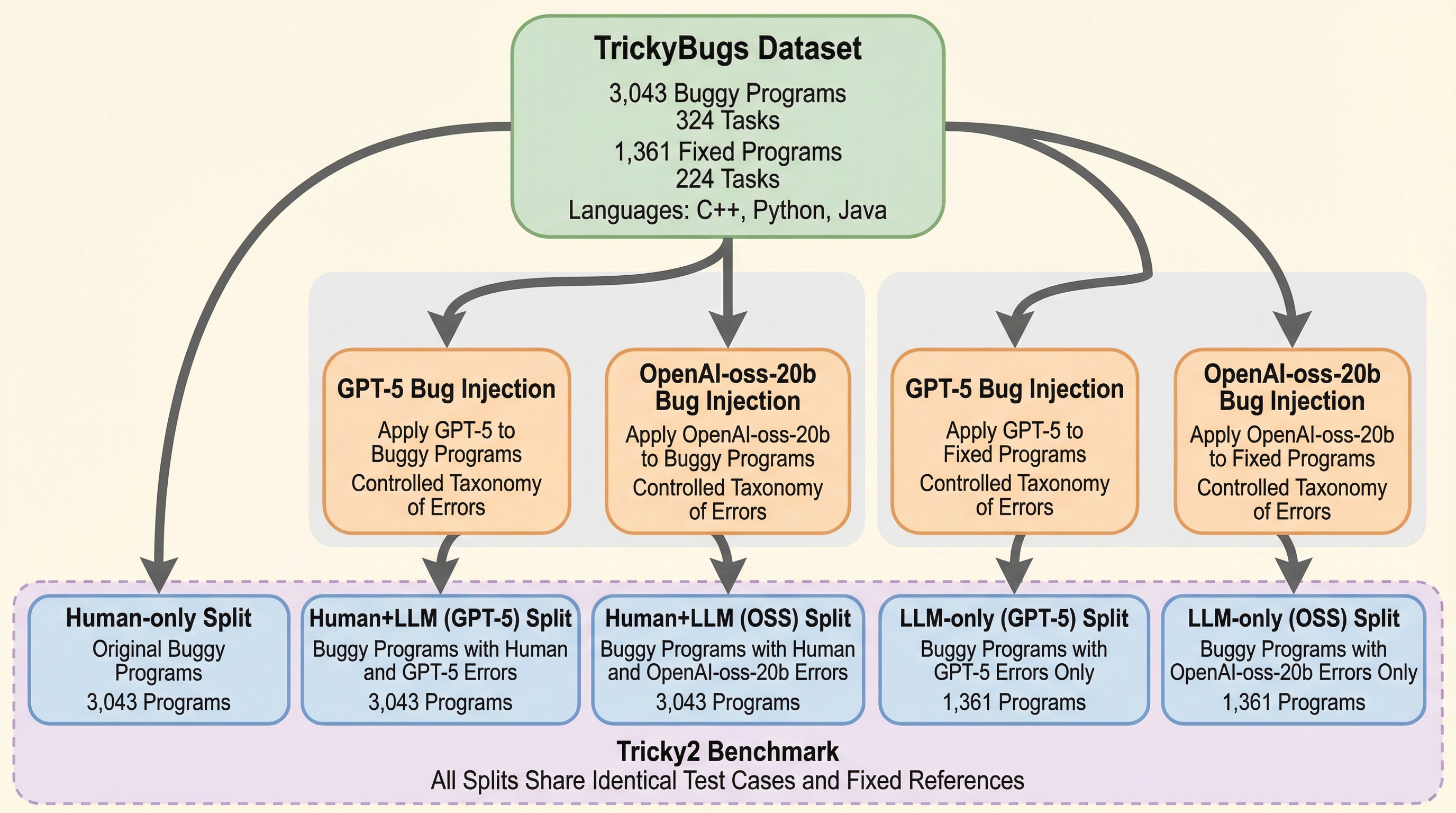
ソフトウェア開発において大規模言語モデル(LLM)の活用が急速に広がる中で、人間が書いたコードとAIが生成したコードが混在する環境での信頼性確保が重要な課題となっています。本研究では、人間由来のバグとLLMが生成したバグが同一プログラム内で共存する「混合起源エラー」を評価するための新しいベンチマーク「Tricky$^2$」を提案し、その複雑性を体系的にモデル化しました。検証の結果、人間とAIのバグが組み合わさることでエラー同士が互いを隠蔽または悪化させる相互作用が発生し、単一のバグ修正よりも難易度が劇的に上昇することが実証されました。