SICL-AT:聴覚LLMを低リソースタスクに適応させる新手法
聴覚大規模言語モデル(Auditory LLM)は、子供の音声認識や複雑な音声推論といったデータが乏しい低リソースタスクにおいて、直接的な微調整を行うと過学習や分布の不一致により性能が不安定になるという課題を抱えています。
TL;DR(結論)
聴覚大規模言語モデル(Auditory LLM)は、子供の音声認識や複雑な音声推論といったデータが乏しい低リソースタスクにおいて、直接的な微調整を行うと過学習や分布の不一致により性能が不安定になるという課題を抱えています。 本研究が提案する「SICL-AT」は、豊富な既存の音声データを用いて、推論時と同じ形式の「デモンストレーション(例示)に基づく学習」をモデルに明示的に学習させる事後学習レシピであり、勾配更新なしで未知のタスクに適応する能力を向上させます。 検証の結果、SICL-ATを適用したモデルは、子供の音声認識や音声理解・推論タスクにおいて、従来のゼロショットや直接的な微調整を上回る高い精度と堅牢性を発揮し、学習に使用していない言語やタスクに対しても優れた汎用性を示すことが確認されました。
なぜこの問題か
現代の聴覚大規模言語モデルは、広範な音声やオーディオの理解タスクで強力な性能を示していますが、特定の専門的な領域やデータが極端に少ない低リソースタスクに適用しようとすると、依然として大きな困難に直面します。特に、子供の音声認識や複雑な音声推論タスクでは、ラベル付きのドメイン内データを大規模に収集することが非常に困難であり、利用可能なデータが真のテスト分布を十分に代表していないことが多々あります。このような状況で、限られたデータを用いてモデルを直接微調整(Supervised Fine-tuning)しようとすると、モデルが特定の訓練データに過剰に適合してしまい、わずかなドメインの変化に対しても性能が著しく低下する「脆さ(brittleness)」が生じることが大きな問題となっていました。 一方で、大人の英語音声認識データのような高リソースなデータは豊富に存在しており、これらの「ドメイン外」の膨大なデータを、どのようにしてデータが不足している「ドメイン内」のタスクに役立てるかが重要な課題となっています。…
核心:何を提案したのか
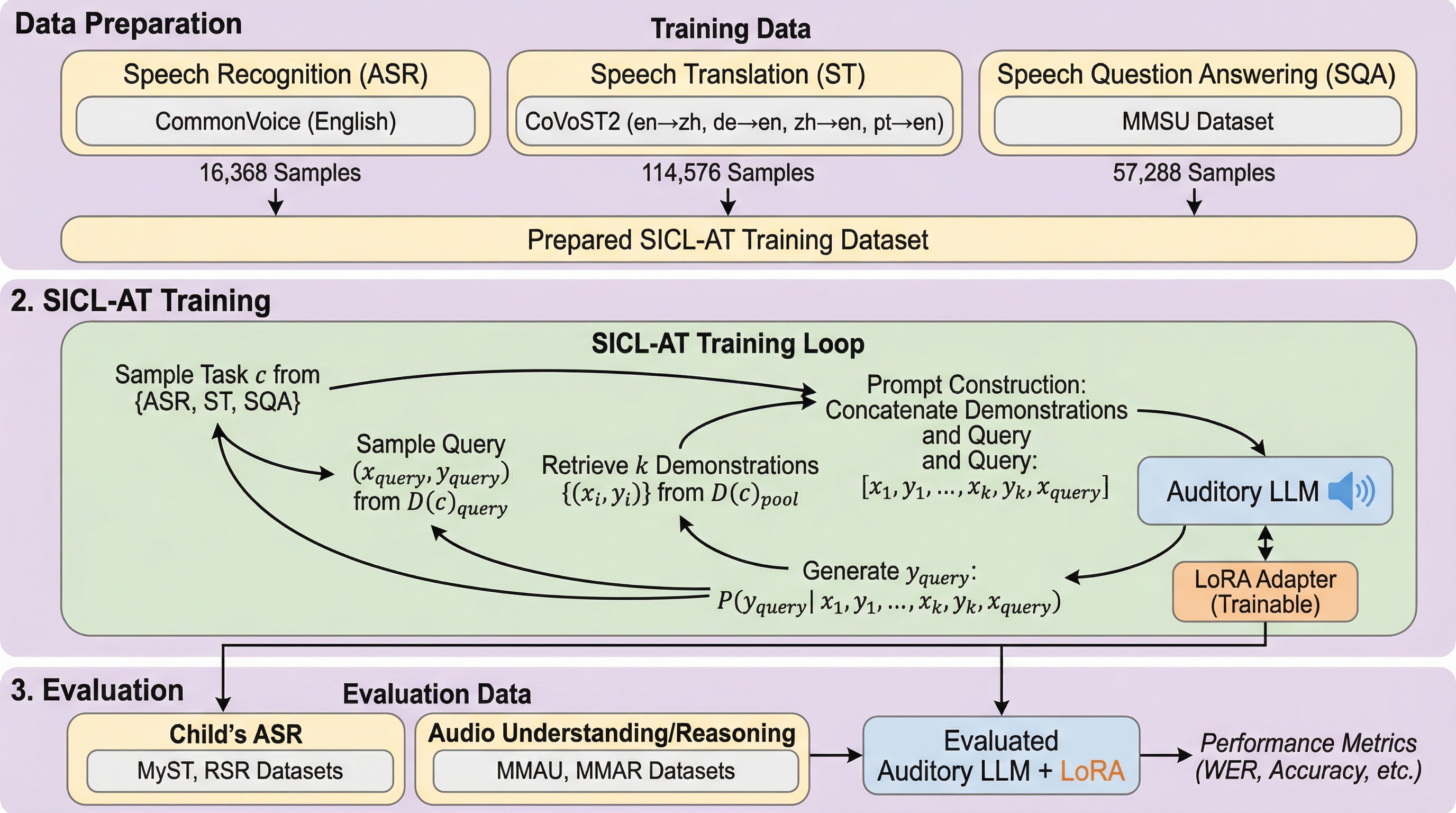
本研究では、聴覚LLMのインコンテキスト学習能力を根本から強化するための新しい事後学習戦略として、「Speech In-Context Learning Adaptation-Tuning(SICL-AT)」を提案しています。この手法の核心は、モデルに対して特定のドメイン知識を教え込むことではなく、推論時に提供されるオーディオのデモンストレーション(例示)を条件として、適切な回答を生成する「能力そのもの」を訓練することにあります。具体的には、豊富な高リソース音声データを利用して、推論時と全く同じエピソード形式のフォーマットでモデルを学習させることで、未知のタスクや低リソースな設定においても、少数の例示から柔軟に適応できるインテリジェンスを養います。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related