RIFT:単一の多段階プロンプト構造における指示従順性を評価するための並べ替え指示従順性テストベッド
大規模言語モデル(LLM)が複雑な指示に従う能力を、タスクの難易度や内容から構造的な配置を切り離して精密に評価するための新しいベンチマークフレームワーク「RIFT」が提案されました。 テレビ番組のクイズを基にしたデータセットを用い、順番通りに回答する「線形プロンプト」と、指示に従って非連続な順序で回答を求める「ジャンププロンプト」の二つの構造でモデルの性能を比較検証しています。 最新の高性能モデルであっても、非連続な指示条件下では正解率が最大で72%も低下し、モデルが指示を論理的な推論スキルとしてではなく、単なる逐次的なパターンの継続として処理しているという構造的な脆弱性が明らかになりました。
TL;DR(結論)
大規模言語モデル(LLM)が複雑な指示に従う能力を、タスクの難易度や内容から構造的な配置を切り離して精密に評価するための新しいベンチマークフレームワーク「RIFT」が提案されました。 テレビ番組のクイズを基にしたデータセットを用い、順番通りに回答する「線形プロンプト」と、指示に従って非連続な順序で回答を求める「ジャンププロンプト」の二つの構造でモデルの性能を比較検証しています。 最新の高性能モデルであっても、非連続な指示条件下では正解率が最大で72%も低下し、モデルが指示を論理的な推論スキルとしてではなく、単なる逐次的なパターンの継続として処理しているという構造的な脆弱性が明らかになりました。
なぜこの問題か
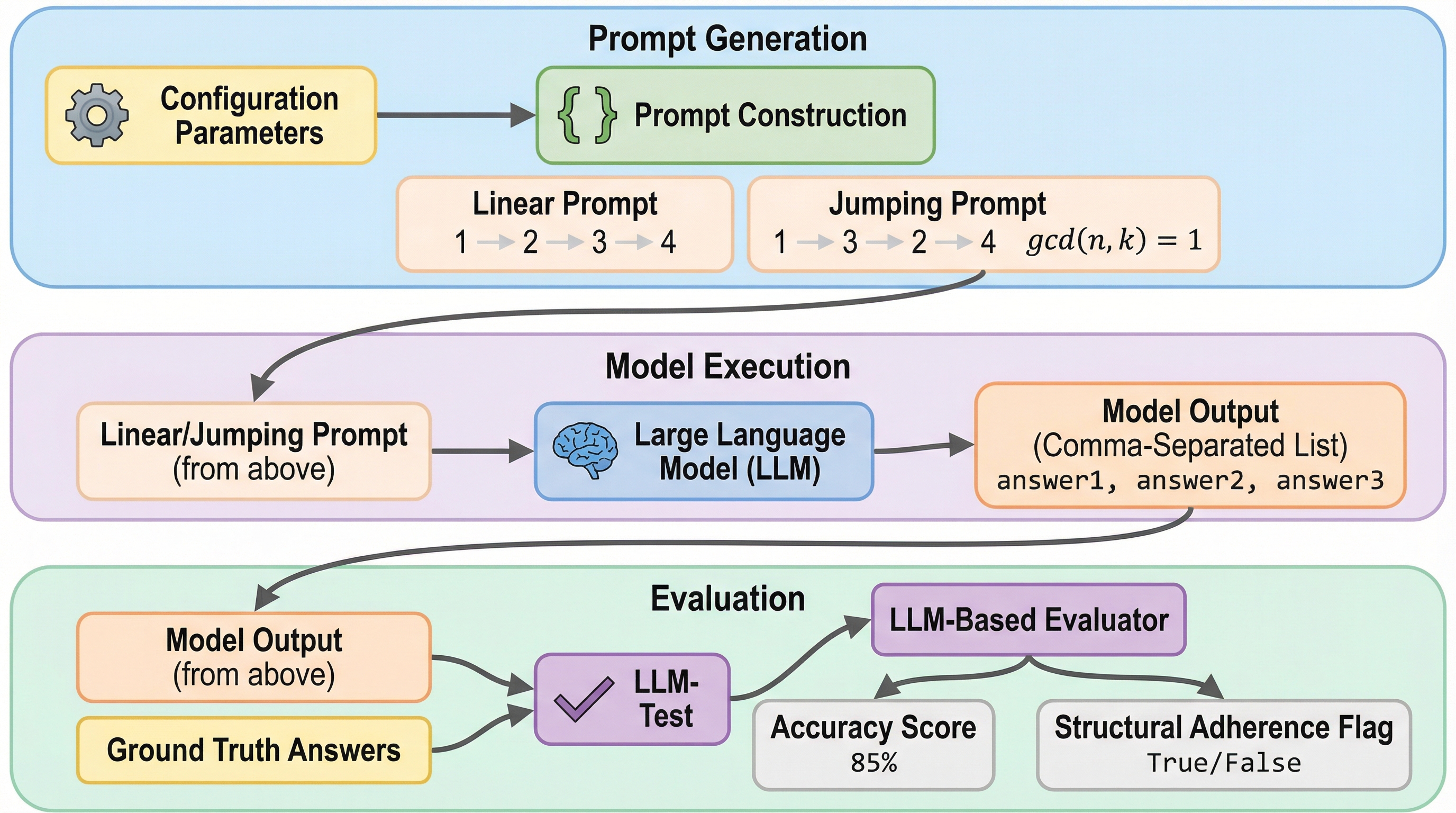
大規模言語モデル(LLM)は、自動推論や対話管理、意思決定支援といった複雑なワークフローにおいて中心的な役割を果たすようになっています。しかし、複数のステップからなる指示や条件付きの指示を正確に実行する能力については、まだ十分に解明されていないのが現状です。特に、指示がモデルにとって馴染みのある線形な順序から外れた場合、その信頼性が著しく低下することが懸念されています。既存の指示従順性ベンチマークであるIFEval、HELM、BIG-Benchなどは、タスクの複雑さ、言語的な難易度、そしてプロンプトの構造を混同して評価しているという課題があります。これらのベンチマークでは構造を独立して操作することができないため、性能の差がタスク自体の難易度によるものなのか、あるいは指示の提示順序によるものなのかを特定することが困難でした。 先行研究では、指示の数が増えるほど全ての制約を満たす確率が急激に低下する「指示の呪い」や、後の指示よりも前の指示を優先して守る「初頭効果」などが報告されています。…
核心:何を提案したのか
本研究では、プロンプトの構造と内容を分離して評価するための制御された実験フレームワーク「RIFT(Reordered Instruction Following Testbed)」を提案しています。このフレームワークの核心は、同一の質問セットを用いながら、その実行順序だけを「線形(Linear)」と「ジャンプ(Jumping)」の二つの異なるトポロジーに再構成し、モデルの指示従順性を診断することにあります。これにより、言語的な難易度や知識の有無といった要因を排除し、純粋に「指示された順序に従う能力」を測定することが可能になりました。 具体的には、テレビ番組「Jeopardy!」のクイズ形式のデータセットを採用しています。このデータセットは、多様なドメインの事実知識を含んでおり、難易度も調整しやすいため、LLMの基礎能力を測るのに適しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related