BabyReasoningBench:赤ちゃん言語モデル評価のための発達に着想を得た推論タスクの生成
従来の言語モデル評価は成人の知識や複雑な指示への追従を前提としていましたが、本研究では乳幼児の認知発達の軌跡に着想を得た新しい評価指標「BABYREASONINGBENCH」を提案しました。 このベンチマークは、心の理論、類推、因果推論、基本的な推論プリミティブの4つの領域にわたる19のタスクで構成されており、子供向けの発話データなどで学習された「赤ちゃん言語モデル」の能力を精密に測定します。 実験の結果、学習データの規模を拡大することで物理的・因果的な推論能力は向上するものの、他者の信念の理解や語用論的な判断を要する課題は依然として困難であり、能力の出現には不均一なパターンがあることが明らかになりました。
TL;DR(結論)
従来の言語モデル評価は成人の知識や複雑な指示への追従を前提としていましたが、本研究では乳幼児の認知発達の軌跡に着想を得た新しい評価指標「BABYREASONINGBENCH」を提案しました。 このベンチマークは、心の理論、類推、因果推論、基本的な推論プリミティブの4つの領域にわたる19のタスクで構成されており、子供向けの発話データなどで学習された「赤ちゃん言語モデル」の能力を精密に測定します。 実験の結果、学習データの規模を拡大することで物理的・因果的な推論能力は向上するものの、他者の信念の理解や語用論的な判断を要する課題は依然として困難であり、能力の出現には不均一なパターンがあることが明らかになりました。
なぜこの問題か
大規模言語モデル(LLM)の推論能力を測定するための従来のベンチマークは、広範な世界知識、長文の指示への追従、そして成熟した言語運用能力を前提とした成人中心の設計が支配的であるという大きな課題があります。このような評価手法は、保護者と子供の対話データや幼少期の物語、簡略化された知覚的・叙述的な入力のみで学習された「赤ちゃん言語モデル(Baby Language Models)」の評価には適していません。成人向けの基準では、限られた学習環境下でどのような推論能力が実際に芽生えているのか、あるいは何が欠けているのかを正確に把握することが困難です。また、認知モデリングやデータ効率の良い人工知能の開発という観点からも、発達段階に適した評価パラダイムの構築が強く求められています。 子供のような限定的なデータ分布からどのような知能が立ち上がるのかを解明することは、人間の認知発達のプロセスを理解する上でも極めて重要です。さらに、子供を対象とした実験では実施が難しい因果的な介入実験をモデル上で行うための基盤としても、発達心理学の古典的なパラダイムに整合した評価指標が必要とされていました。…
核心:何を提案したのか
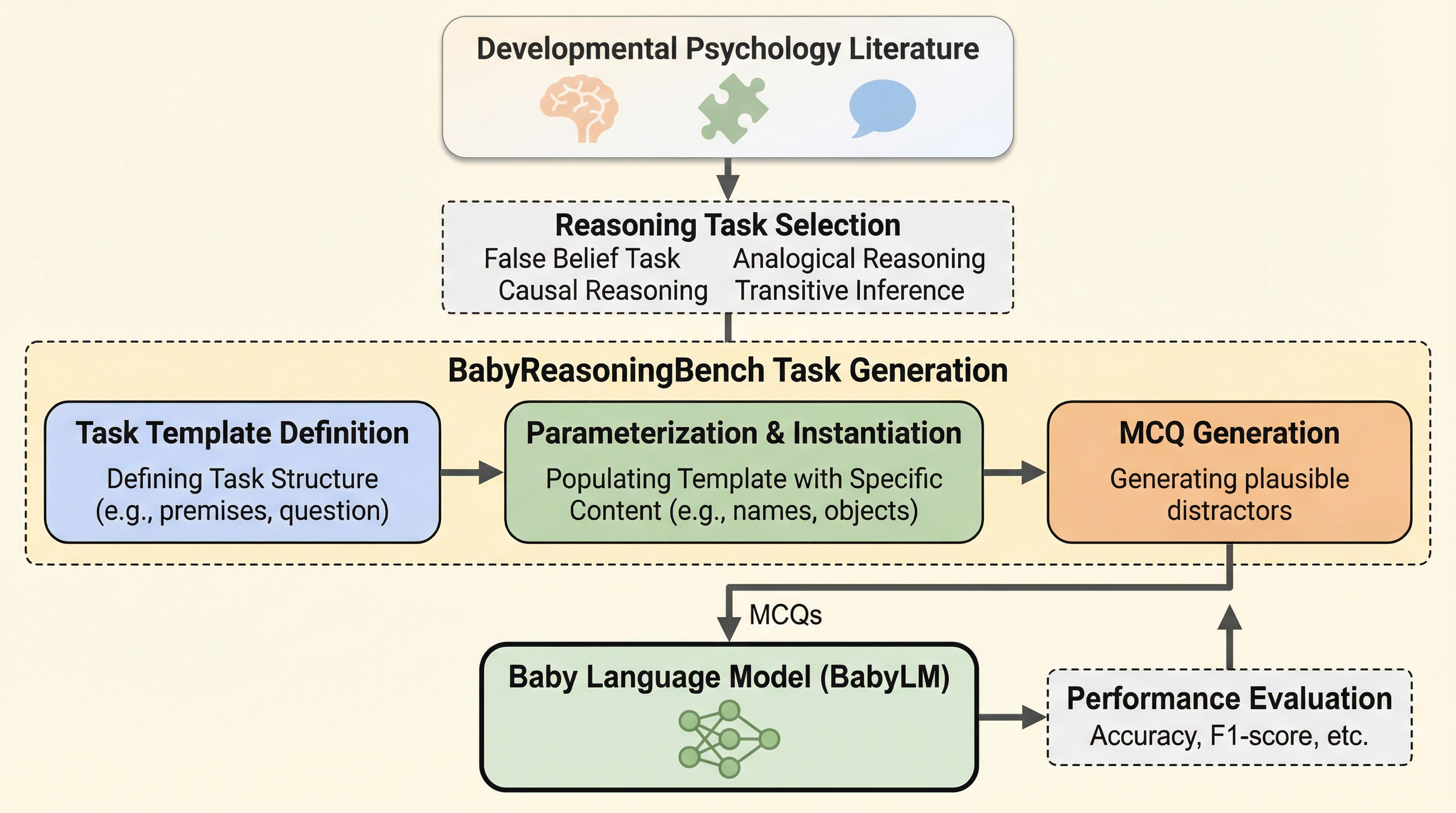
本研究では、発達心理学の古典的な実験パラダイムに基づいた19の推論タスクを集約した「BABYREASONINGBENCH」を提案しました。このベンチマークは、心の理論(Theory of Mind)、類推と関係推論、因果学習、推論プリミティブという4つの主要なカテゴリーを網羅しています。具体的には、他者の誤った信念を理解する能力を問う「サリーとアンの課題」や、未知の物体の因果的な力を推論する「ブリケット検知器(Blicket Detector)」の課題、さらには物理的な原因と結果の原則に関する判断などが含まれています。これらのタスクは、人間の子供が成長過程でどのように認知能力を獲得していくかという指標に基づいています。 タスクの構築にあたっては、系統的かつ表現の偏りに依存しない評価を実現するため、GPT-5.2を活用して多肢選択式(MCQ)の質問を生成しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related