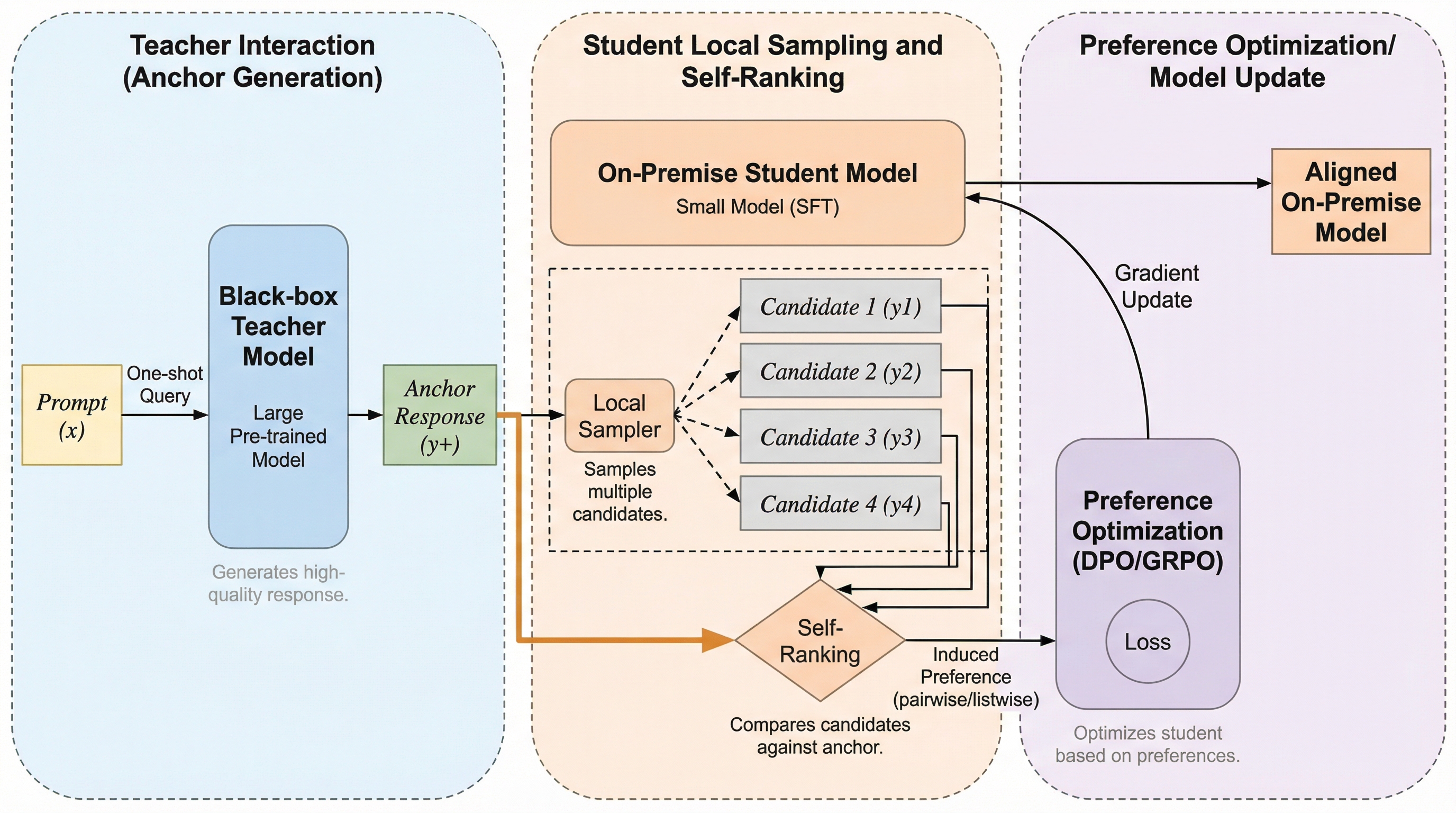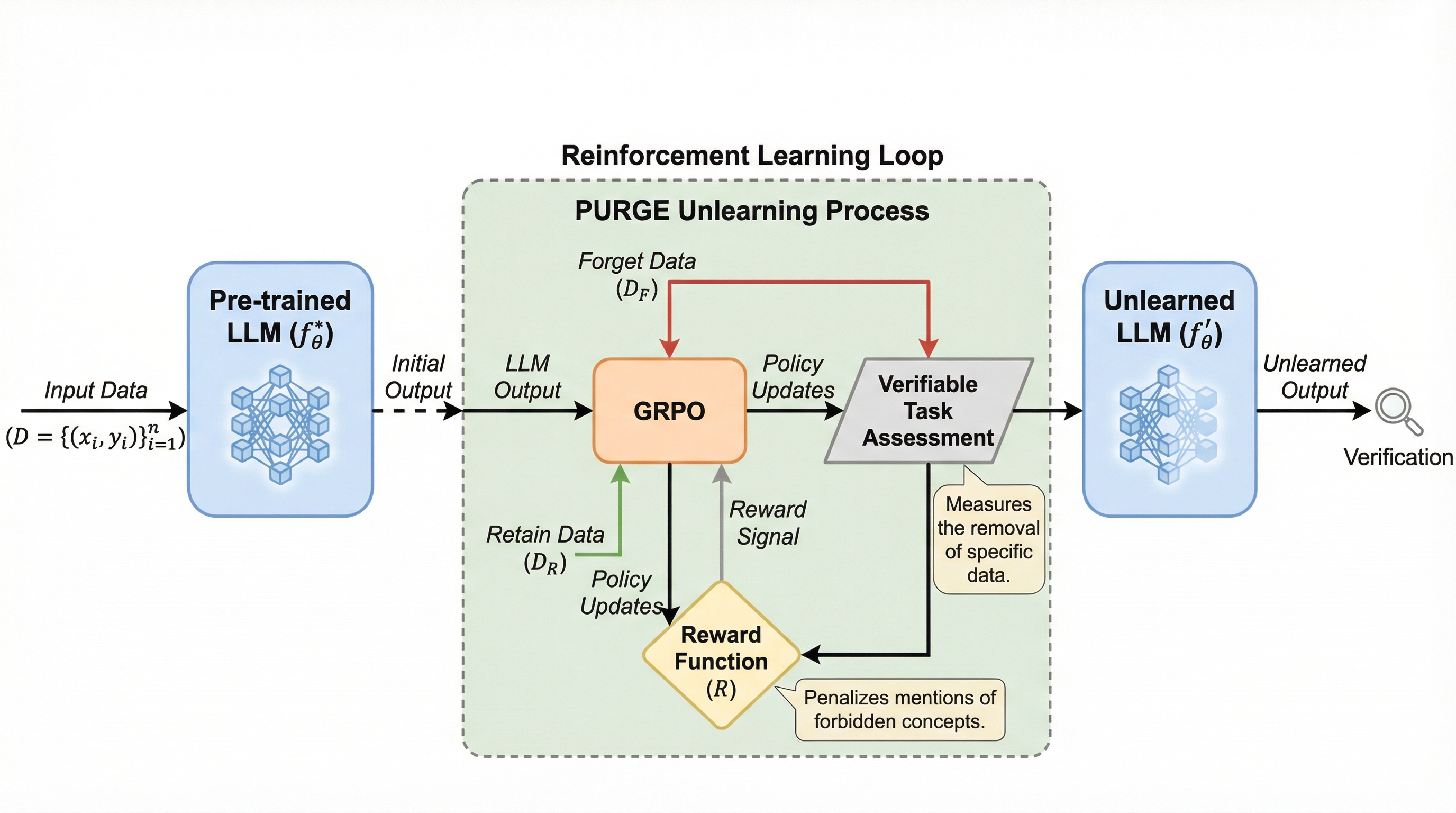
グループ相対方策最適化による強化学習アンラーニング
大規模言語モデル(LLM)が学習中に記憶した機密情報や著作権データを削除するため、強化学習フレームワークであるGRPOを応用した新手法「PURGE」が提案されました。この手法は忘却を「検証可能なタスク」として再定義し、外部の報酬モデルを必要とせずに、禁止された概念への言及にペナルティを与える固有の報酬信号を利用することで、安全かつ一貫性のある忘却を実現します。検証の結果、既存手法と比較してトークン使用量を最大46倍削減し、モデルの流暢さを5.48%、敵対的攻撃への堅牢性を12.02%向上させつつ、元の実用性を98%という極めて高い水準で維持できることが示されました。