グループ相対方策最適化による強化学習アンラーニング
大規模言語モデル(LLM)が学習中に記憶した機密情報や著作権データを削除するため、強化学習フレームワークであるGRPOを応用した新手法「PURGE」が提案されました。この手法は忘却を「検証可能なタスク」として再定義し、外部の報酬モデルを必要とせずに、禁止された概念への言及にペナルティを与える固有の報酬信号を利用することで、安全かつ一貫性のある忘却を実現します。検証の結果、既存手法と比較してトークン使用量を最大46倍削減し、モデルの流暢さを5.48%、敵対的攻撃への堅牢性を12.02%向上させつつ、元の実用性を98%という極めて高い水準で維持できることが示されました。
TL;DR(結論)
大規模言語モデル(LLM)が学習中に記憶した機密情報や著作権データを削除するため、強化学習フレームワークであるGRPOを応用した新手法「PURGE」が提案されました。この手法は忘却を「検証可能なタスク」として再定義し、外部の報酬モデルを必要とせずに、禁止された概念への言及にペナルティを与える固有の報酬信号を利用することで、安全かつ一貫性のある忘却を実現します。検証の結果、既存手法と比較してトークン使用量を最大46倍削減し、モデルの流暢さを5.48%、敵対的攻撃への堅牢性を12.02%向上させつつ、元の実用性を98%という極めて高い水準で維持できることが示されました。
なぜこの問題か
大規模言語モデルは、インターネット上の膨大なデータセットから学習する過程で、個人の機密情報や著作権で保護されたコンテンツ、さらには有害な応用に悪用される可能性のある知識を意図せず吸収し、保持してしまうという性質を持っています。このようなモデルの記憶能力は、欧州連合の一般データ保護規則(GDPR)における「忘れられる権利」や、AIシステムに対して特定のデータをオンデマンドで削除するメカニズムを求めるEU AI法などの法的枠組みにおいて、重大なコンプライアンス上の課題を突きつけています。これらの規制要件を満たすためには、モデルをゼロから再学習するという莫大なコストをかけることなく、デプロイ済みのモデルから特定の情報のみを選択的に削除する「マシンアンラーニング(機械忘却)」の技術が不可欠となっています。 しかし、既存の忘却アプローチにはいくつかの重大な欠点が存在しています。例えば、インコンテキスト手法ではプロンプトの操作によってデータが漏洩するリスクがあり、コンテキストウィンドウの制限も課題となります。…
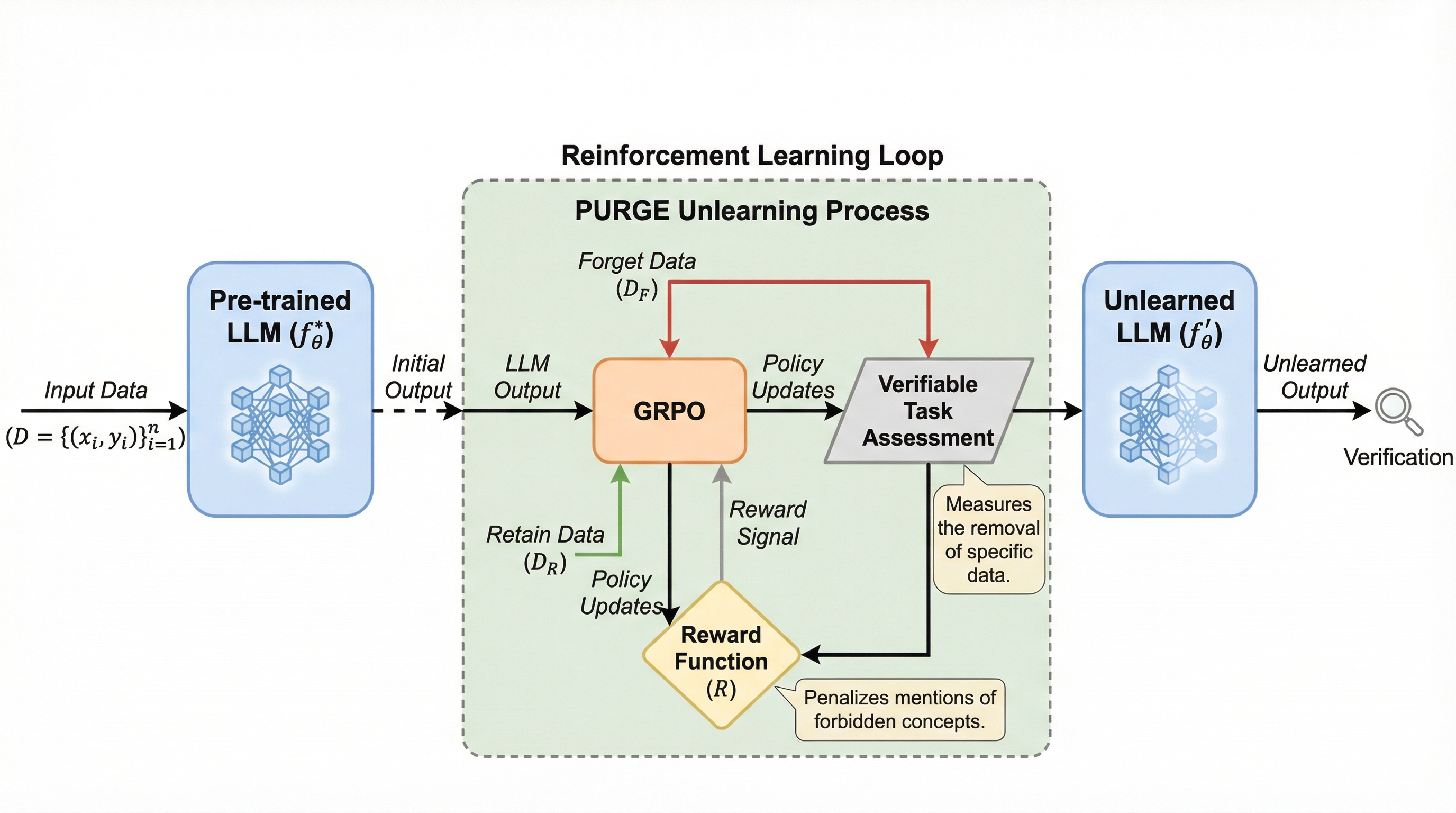
核心:何を提案したのか
本論文では、Group Relative Policy Optimization(GRPO)フレームワークに基づいた新しい忘却手法である「PURGE(Policy Unlearning through Relative Group Erasure)」が提案されました。この手法の核心的なアイデアは、大規模言語モデルにおける忘却を、数学の問題解決やコード生成のように客観的な基準で測定し改善できる「検証可能なタスク」として定式化した点にあります。従来の忘却手法が特定のデータを単に削除しようと試みるのに対し、PURGEはGRPOの仕組みを活用して、モデルが一般的な実用性を維持しながら特定の知識のみを忘却するように導く、原理に基づいた強化学習アプローチを採用しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related