オンプレミス環境の小規模モデル向け!教師なしで強化学習アライメントを実現する蒸留手法「PU-RL」
オンプレミス環境での小規模モデル運用において、プライバシーやコストの制約から困難だった強化学習によるアライメントを、外部の教師モデルからの「アンカー」生成一回のみで実現する新しい蒸留手法「PU-RL」が提案された。
TL;DR(結論)
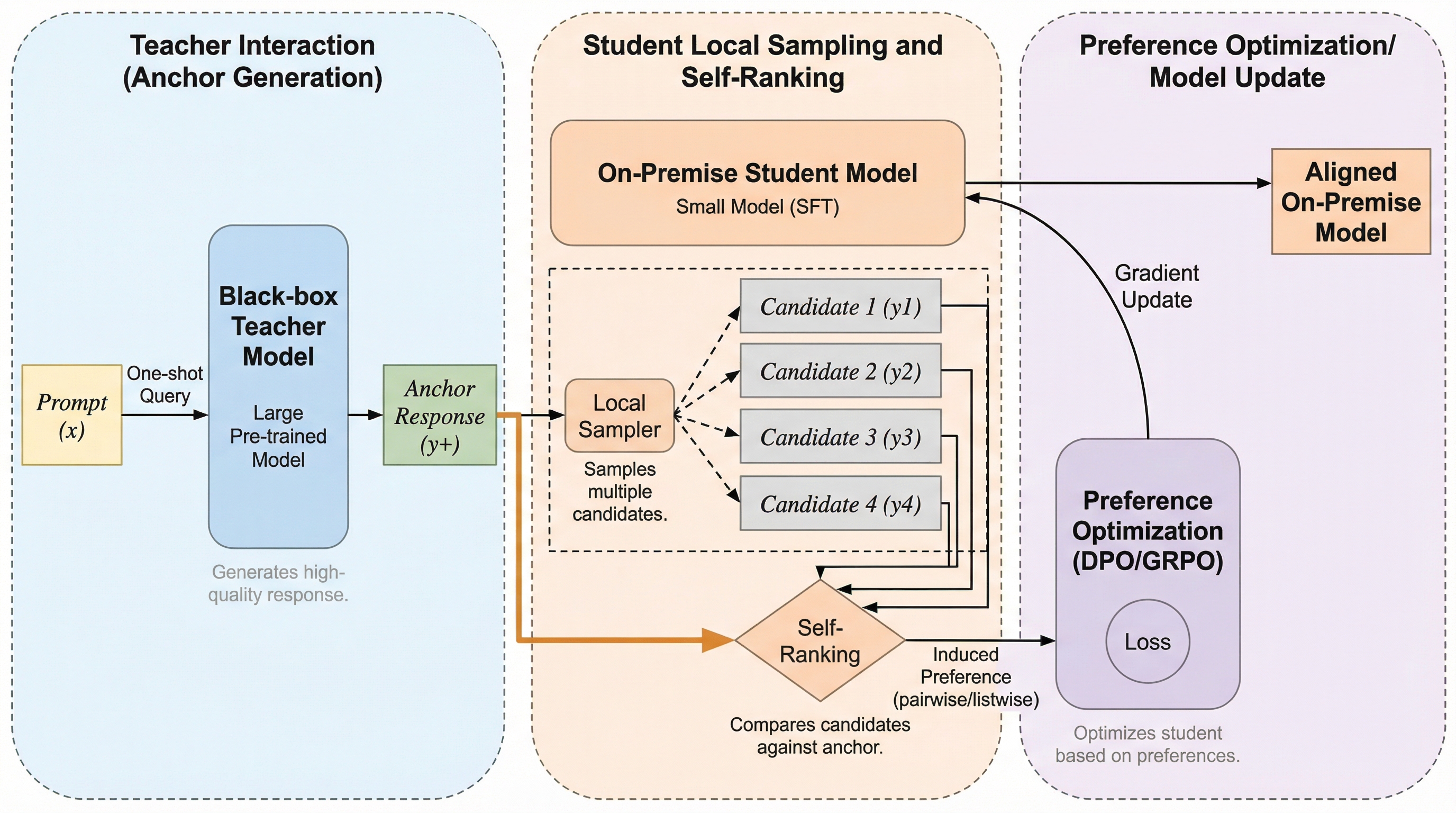
オンプレミス環境での小規模モデル運用において、プライバシーやコストの制約から困難だった強化学習によるアライメントを、外部の教師モデルからの「アンカー」生成一回のみで実現する新しい蒸留手法「PU-RL」が提案された。この手法は、高価な人間によるフィードバックや複雑な報酬モデルの構築を一切必要とせず、ブラックボックスな教師モデルの能力を効率的に学生モデルへ移転する画期的なアプローチである。 本手法は、教師モデルをブラックボックスとして扱い、得られた回答を正例のアンカーとし、モデル自身が生成した複数の回答を未分類データとして扱うPositive-Unlabeled(PU)学習の枠組みを強化学習に応用している。学生モデルはアンカーを基準に自己評価を行い、相対的な好みの分布を導き出すことで、外部の判定者に頼ることなくローカル環境のみで完結する学習ループを形成することに成功した。 人手による評価や報酬モデルの維持コストを排除しながら、アンカーを用いた自己評価によって局所的な学習を回すことで、従来の教師あり学習や高コストな評価手法を上回る性能を達成した。理論的にも順序の一貫性が証明されており、文章作成や数学的推論、画像理解といった多様な専門タスクにおいて、低コストかつプライバシーを保護した状態でのモデル改善が可能となったことが示されている。
なぜこの問題か
現在、プライバシーの保護、運用コストの削減、低遅延の実現、およびコンプライアンスへの対応といった観点から、オンプレミス環境で小規模な専門モデルを配備する需要が急速に高まっている。一般的に、高性能なモデルを構築するための標準的な手順は、まず教師あり微調整(SFT)を行い、その後に強化学習(RL)を用いたアライメントを適用することである。しかし、実際の運用現場において、この強化学習の段階を実行することは極めて困難であるという課題が存在する。その主な理由は、強化学習によるアライメントには、人間による膨大な好みのラベル付け、あるいは高品質な報酬モデルの構築と維持が必要となるためである。 人間によるラベル付けは持続不可能なほど高価であり、また信頼性の高い報酬モデルをトレーニングして維持することは、技術的にも運運用上も容易ではない。さらに、クラウドサービスプロバイダーが保有する大規模な指示データや好みのコーパスは、独自の所有権や規制上の制約により、オンプレミス環境で共有して利用することができない。…
核心:何を提案したのか
本論文では、人間による好みのラベルや報酬モデルを一切使用せずに、ブラックボックスな大規模モデルから強化学習の能力をオンプレミスの小規模モデルへと蒸留する手法「PU-RL」を提案している。このアプローチは、強化学習能力蒸留(RLCD)という概念に基づいており、教師モデルには生成機能のみを介してアクセスし、学生モデルはローカル環境でサンプリングと更新を行うと…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related