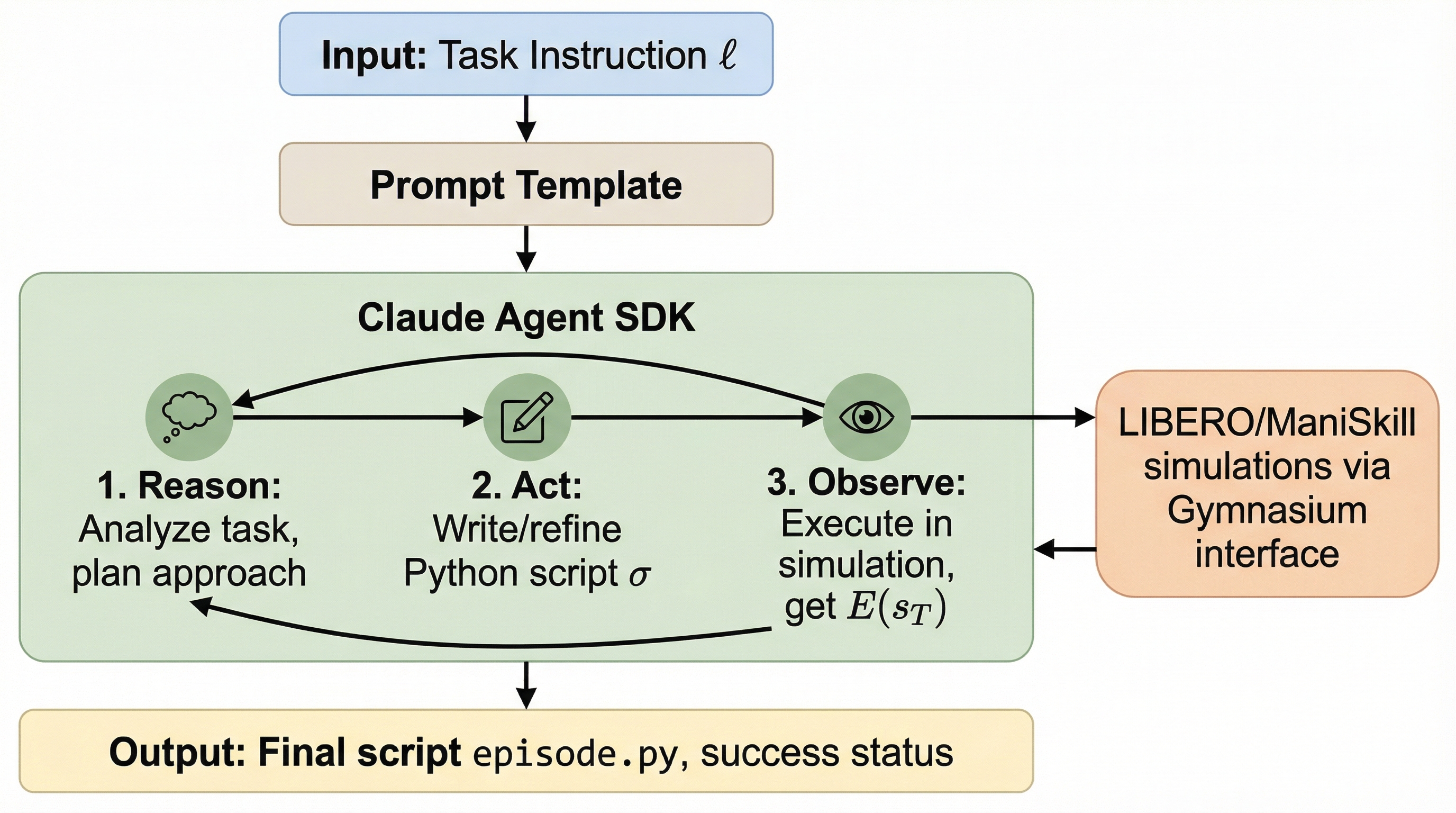
LLMエージェントによる教示不要のロボット制御
FAEA(Frontier Agent as Embodied Agent)は、ソフトウェア開発用に設計された汎用LLMエージェントであるClaude Agent SDKを、一切の変更を加えずそのままロボット操作に適用した手法であり、事前のデモンストレーションや追加学習を必要とせずに、試行錯誤を通じたプログラム合成によって自律的にタスクを遂行する。 LIBERO、ManiSkill3、MetaWorldという3つの主要なベンチマークにおいて、特権的な環境状態を利用することでそれぞれ84.9%、85.7%、96%という高い成功率を達成し、最大100件のデモンストレーションで学習した既存の視覚・言語・行動(VLA)モデルに匹敵、あるいはそれを上回る性能を示した。 この手法は、エージェントがシミュレーション内で自律的に成功軌道を生成できるため、ロボット学習のためのデータ拡張ツールとしての実用性が高く、汎用モデルの進化やエージェント基盤の改善がそのままロボット制御の向上に直結する新しいパラダイムを提示している。