概念成分分析(ConCA):LLMの内部表現から概念を抽出するための原理的アプローチ
大規模言語モデル(LLM)の内部表現を解釈する手法として、従来の稀な自己符号化器(SAE)が抱えていた理論的根拠の欠如という課題を解決するため、潜在変数モデルに基づいた新しい枠組みである概念成分分析(ConCA)が提案されました。
TL;DR(結論)
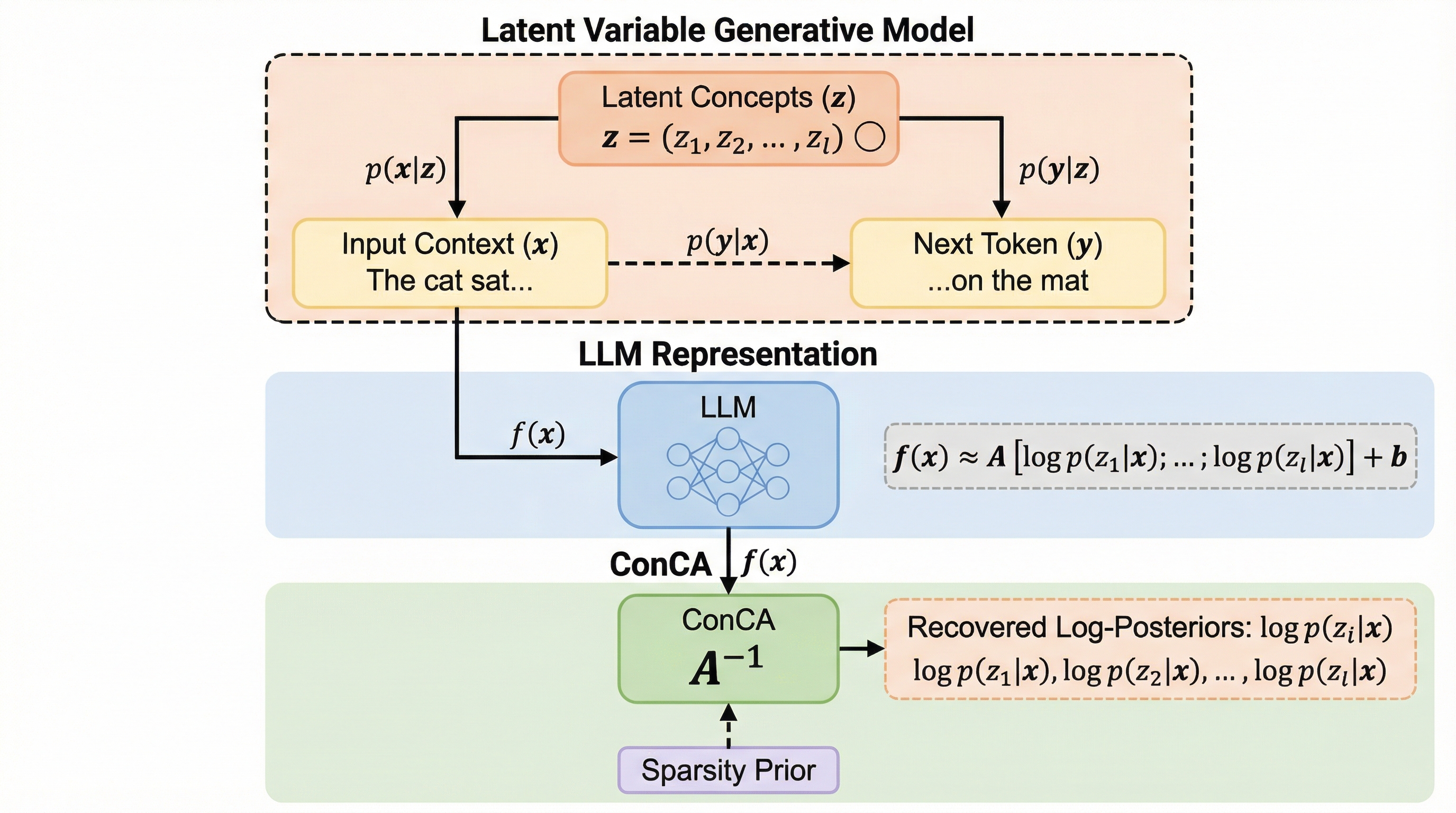
大規模言語モデル(LLM)の内部表現を解釈する手法として、従来の稀な自己符号化器(SAE)が抱えていた理論的根拠の欠如という課題を解決するため、潜在変数モデルに基づいた新しい枠組みである概念成分分析(ConCA)が提案されました。 この手法は、モデルの内部表現が各潜在概念の対数事後確率の線形混合として近似できるという数学的証明に基づいており、従来のSAEで一般的だったエンコーダーの非線形関数を排除し、指数変換後の確率空間で稀疎性を強制する設計を採用しています。 Pythia、Gemma3、Qwen3を用いた検証により、113のデータセットにわたる評価で従来のSAEを上回る概念抽出性能を実証し、LLMの内部で概念が対数事後確率として線形に符号化されているという理論的整合性を明らかにしました。
なぜこの問題か
大規模言語モデル(LLM)が社会の様々な重要領域に導入される中で、モデルが内部でどのような情報処理を行い、どのような概念を保持しているかを人間が理解可能な形で解釈することは、信頼性と安全性を確保する上で避けては通れない課題となっています。メカニスティックな解釈可能性の研究分野では、モデルの活性化値から意味のあるプロセスや概念を抽出する試みが続けられてきました。その中でも、稀な自己符号化器(SAE)は、LLMの内部表現を辞書的な要素に分解し、単一の意味を持つ「モノセマンティック」な概念を抽出するための有力な手法として広く採用されています。SAEは主に、概念が線形に符号化されているという「線形表現仮説」と、モデルがニューロン数以上の特徴を重ね合わせて保持しているという「重ね合わせ仮説」という二つの経験的な仮説に依存しています。 しかし、SAEが実用面で一定の成功を収めている一方で、そこには根本的な理論的曖昧さが残されていました。具体的には、LLMの内部表現と人間が理解可能な概念との間に、どのような数学的な対応関係が厳密に存在するのかが定義されていなかったのです。…
核心:何を提案したのか
本研究では、LLMの内部表現と人間が理解可能な概念との間の理論的な関係を解明し、それに基づいた原理的な概念抽出手法である「概念成分分析(ConCA)」を提案しています。まず、テキストデータが未知の潜在的な概念によって生成されるという潜在変数モデル(LVM)を構築しました。ここで「概念」とは、時制、複数形、感情、構文的役割、トピックなど、人間が解釈可能な離散的な潜在変数として定義されます。このモデルに基づき、次単語予測の枠組みで学習されたLLMの表現が、入力文脈が与えられたときの各潜在概念の対数事後確率の線形混合として近似できることを数学的に証明しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related