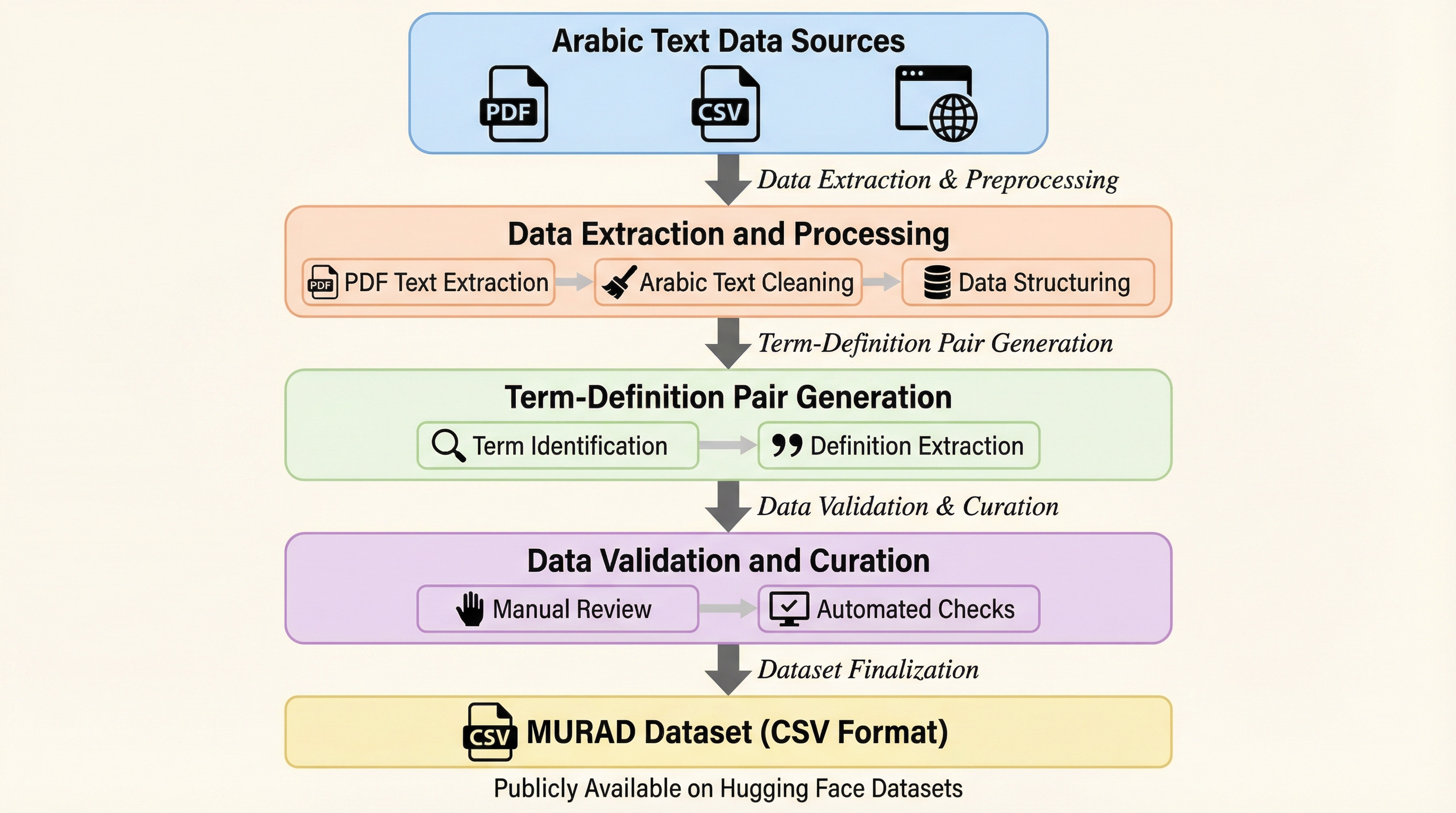
MURAD: 大規模な多領域統合型アラビア語逆引き辞書データセット
1. MURADは、96,243組の単語と定義のペアを収録した、アラビア語において過去最大規模を誇る多領域統合型の逆引き辞書データセットであり、17の信頼できる学術的・教育的出典から構築されている。 2.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
1. MURADは、96,243組の単語と定義のペアを収録した、アラビア語において過去最大規模を誇る多領域統合型の逆引き辞書データセットであり、17の信頼できる学術的・教育的出典から構築されている。 2.
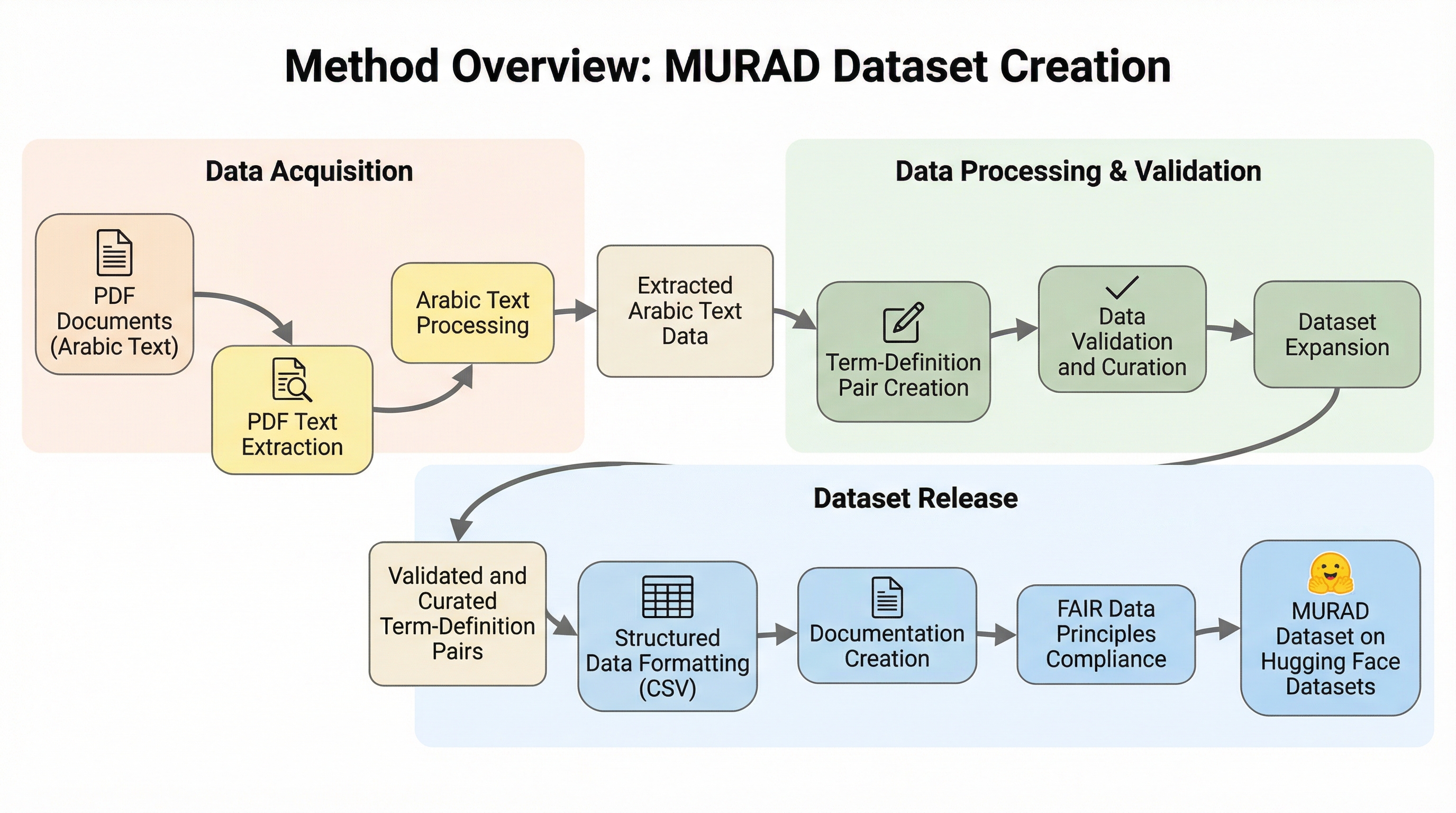
MURADは、アラビア語の語彙と定義を紐付けた96,243組のペアを収録する、大規模でオープンな多領域統合型逆引き辞典データセットです。17の信頼できる出典から構築され、イスラム学、言語学、数学、物理学、工学などの13の専門領域を網羅し、OCRやGPT-4oを活用したハイブリッドなパイプラインによって高い精度と一貫性を確保しています。言葉が思い出せない「舌先現象」の解消や、意味検索、定義生成、埋め込み評価といったアラビア語の自然言語処理研究を促進し、学術的・技術的なコミュニケーションにおける用語の一貫性を支援することを目的としています。
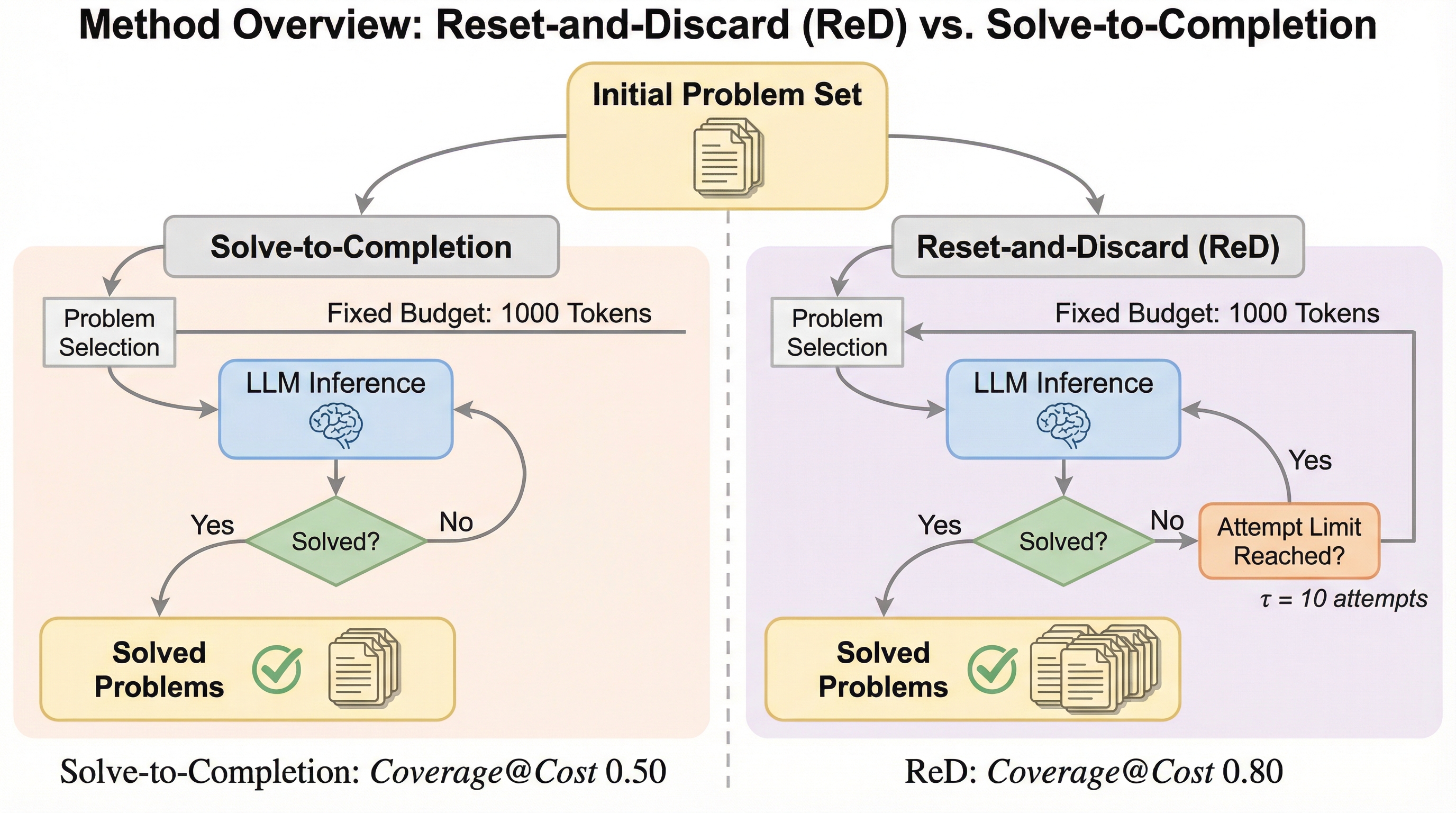
大規模言語モデル(LLM)の性能評価を、従来の1問あたりの成功率(pass@k)から、限られた総予算内で解決できるユニークな問題数(coverage@cost)へと転換することを提案しています。
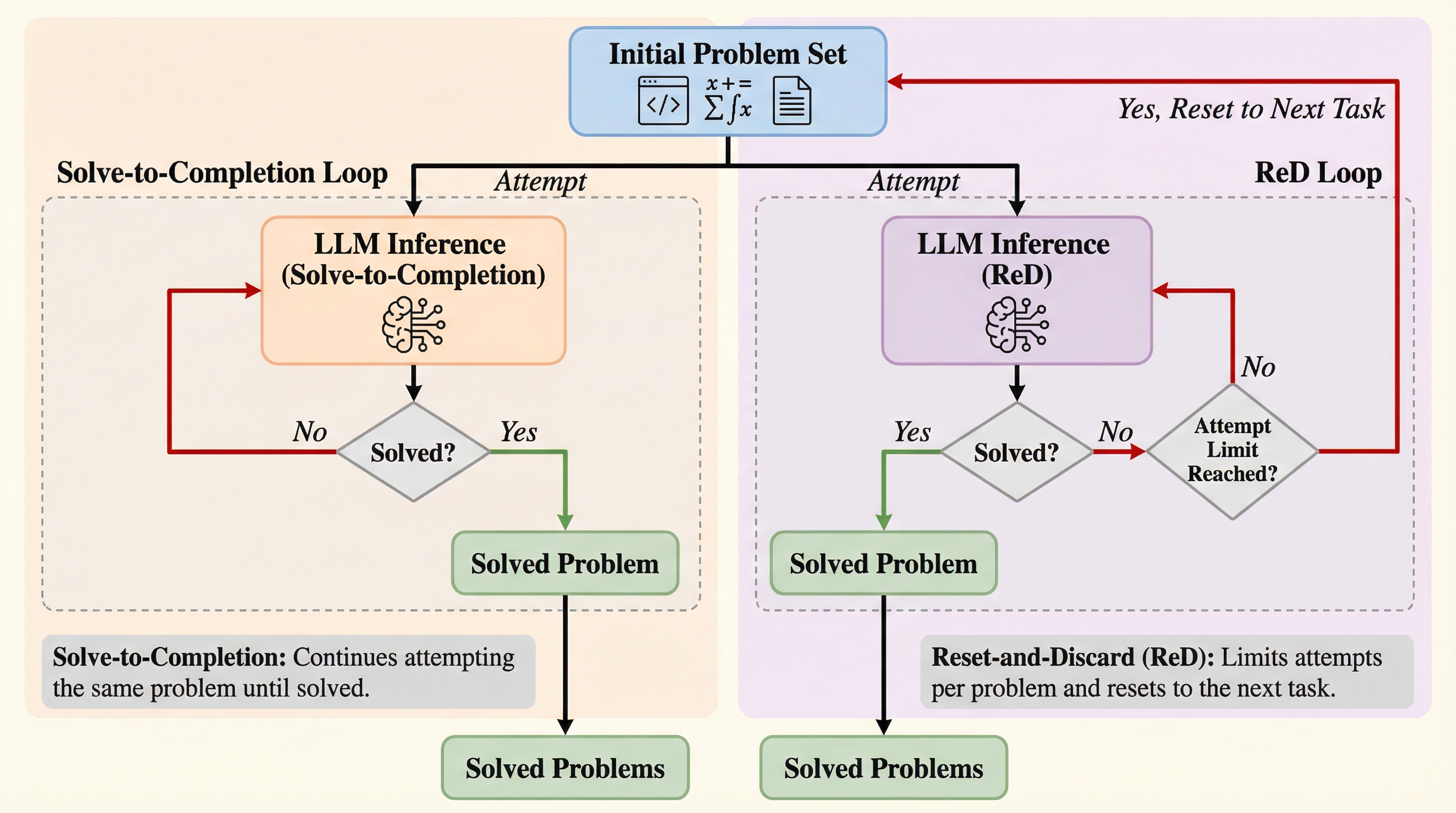
大規模言語モデル(LLM)の推論において、従来は1回でも正解する確率を示すpass@kが重視されてきましたが、実運用では限られた予算内でいくつの異なる問題を解決できるかというcoverage@costがより重要な指標となります。
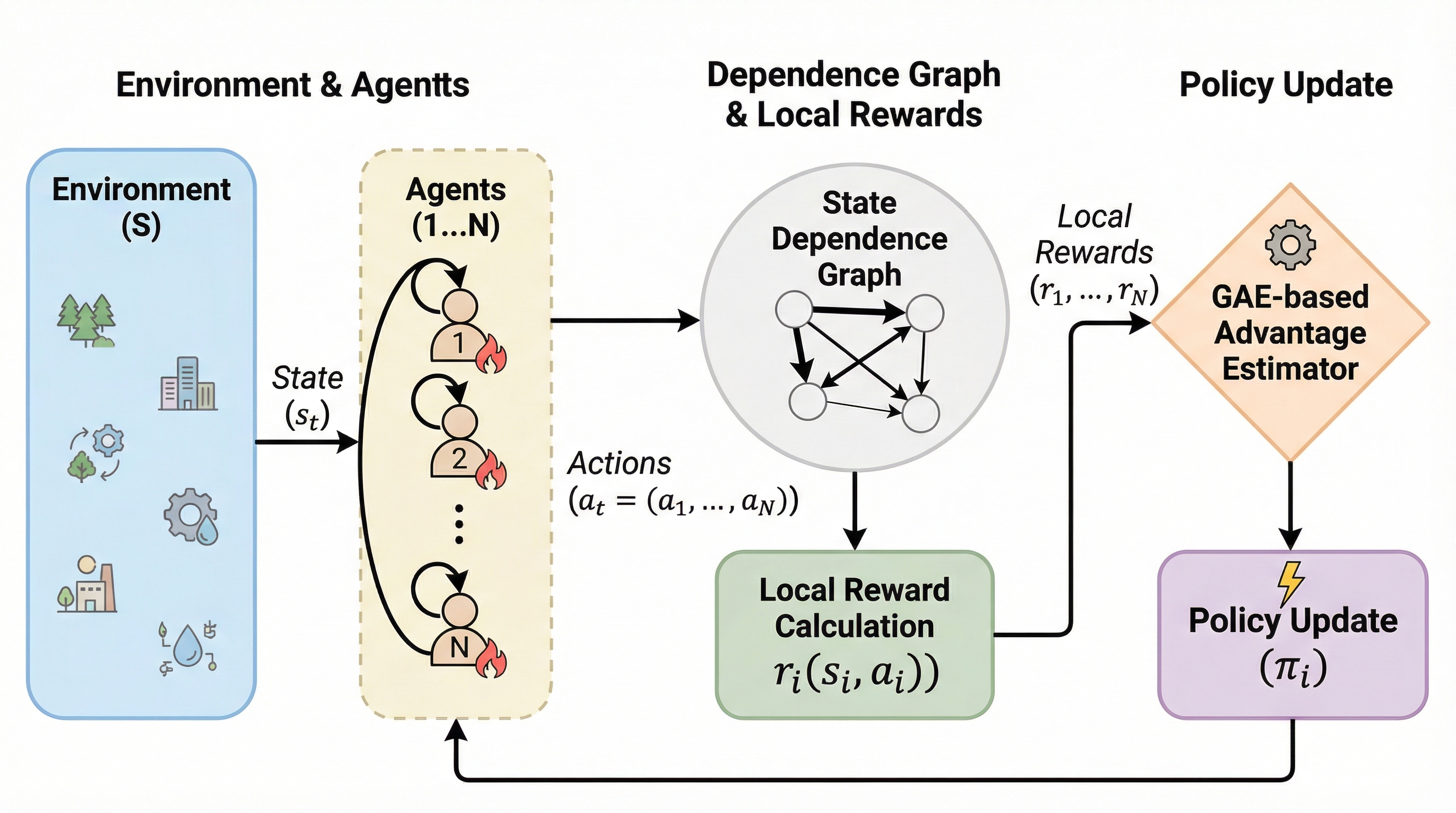
マルチエージェント強化学習において、全エージェントの報酬を統合するグローバル報酬は協力行動を促すが、各個体の貢献度が不明瞭になるクレジット割り当て問題を引き起こし、学習のノイズを増大させる。 一方で、個別の局所報酬を用いる手法は学習速度に優れるものの、エージェントが自身の利益のみを追求する利己的な振る舞いに陥りやすく、システム全体の最適性を損なう「報酬のジレンマ」が存在する。 本研究が提案する手法は、エージェント間の相互作用を依存グラフとしてモデル化し、影響が及ぶ経路に基づいて不要な報酬信号を遮断することで、協力の維持と効率的な学習を両立させる明示的なクレジット割り当てを実現した。
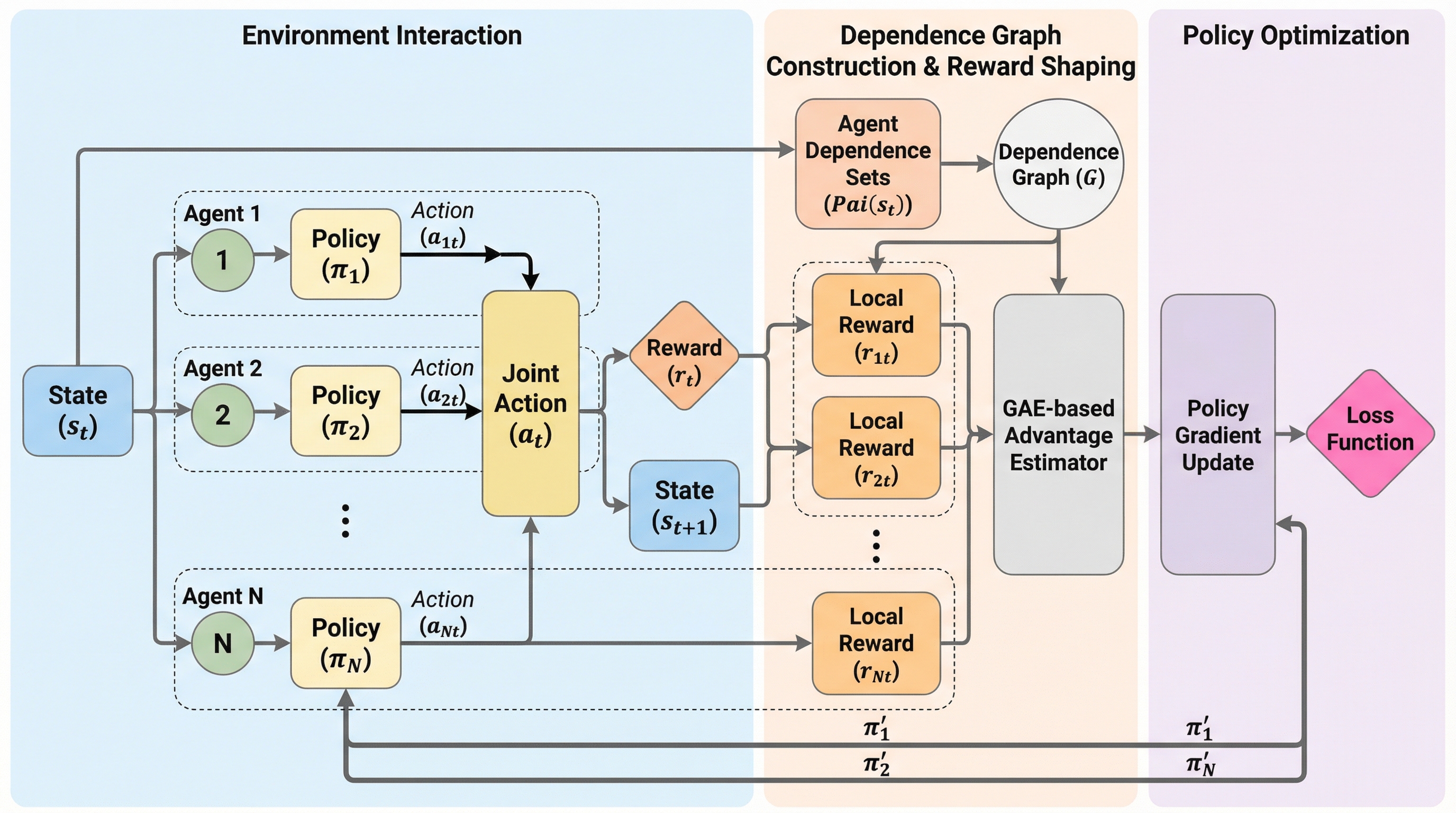
マルチエージェント強化学習において、全体の報酬を共有する「グローバル報酬」は協力行動を促すが、各エージェントの貢献度が不明確になる「貢献度割当問題」を引き起こし、逆に個別の「ローカル報酬」は学習は早いが、エージェントが利己的になり全体の最適性を損なうというジレンマが存在する。
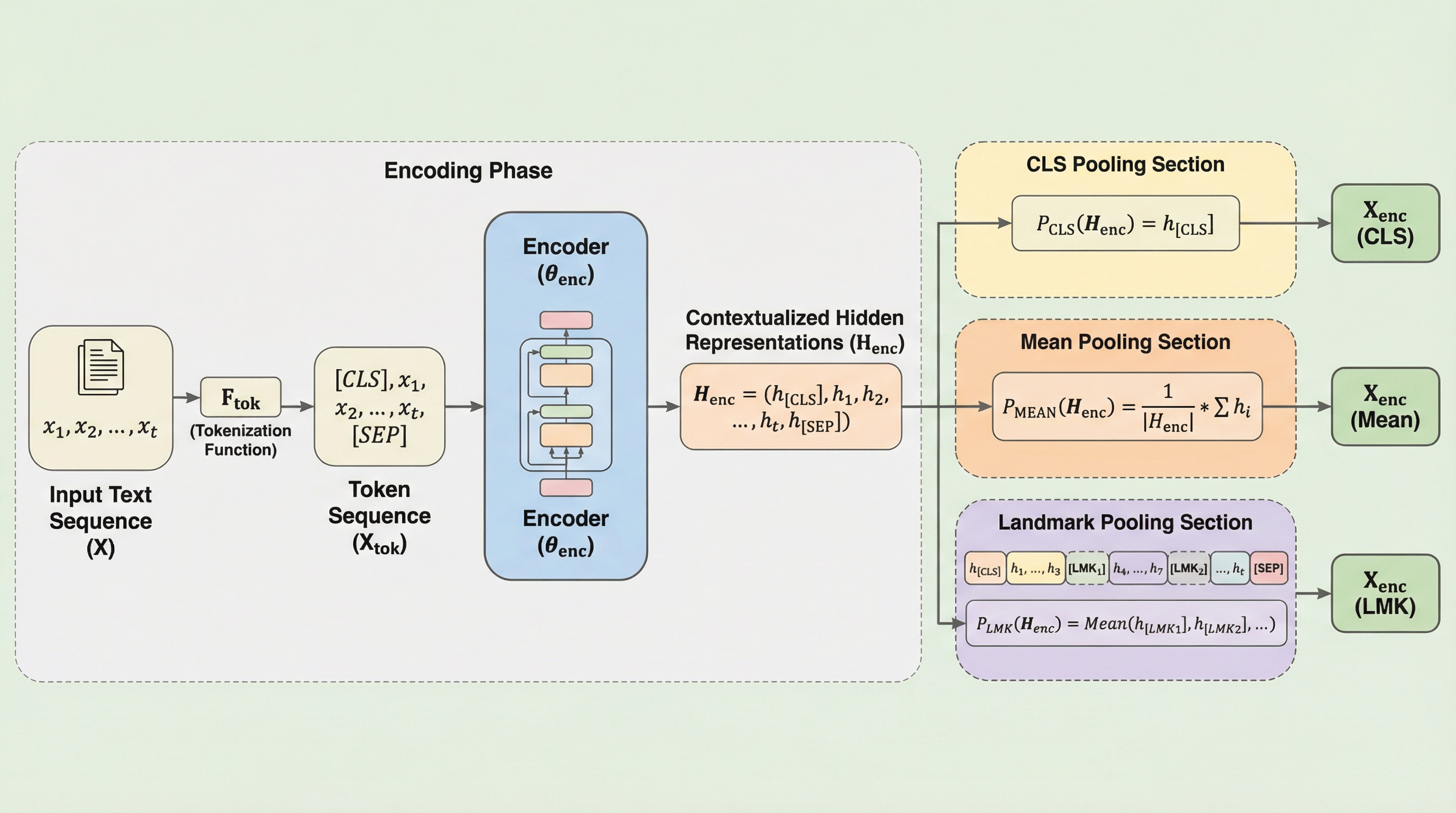
従来の密な埋め込みで主流だった[CLS]トークンや平均プーリングには、長い文章において情報の偏りや重要な信号の希釈が生じるという構造的な弱点がありました。本研究が提案するランドマーク(LMK)プーリングは、文章を一定の間隔で区切り、その間に挿入した複数の特殊トークンの埋め込みのみを平均化することで、情報のボトルネックを解消します。検証の結果、この手法は短い文章での精度を維持しつつ、長い文章の検索タスクにおいて既存手法を大幅に上回る性能と高い外挿性を示し、実用的で拡張可能な代替案となることが証明されました。
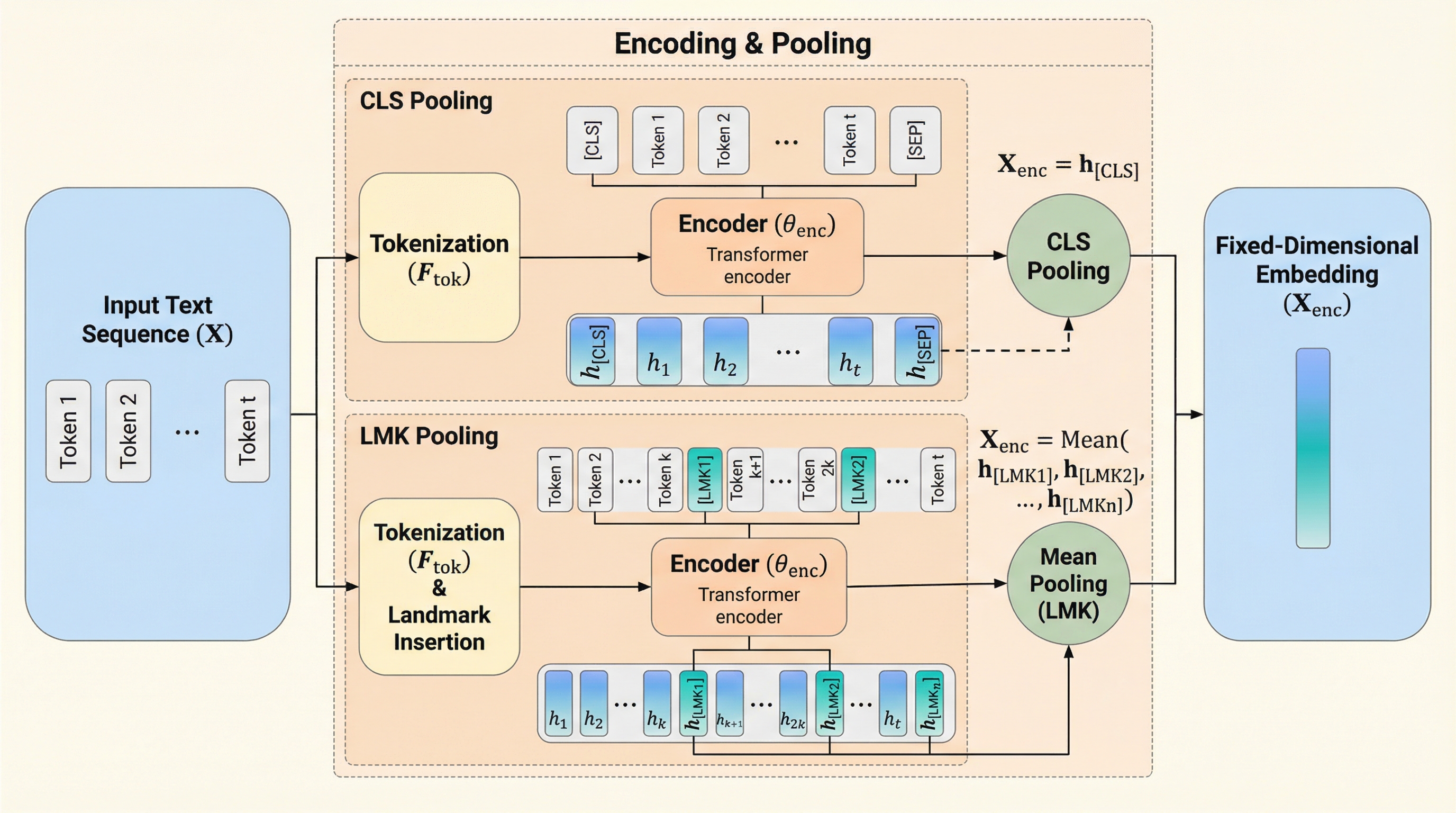
従来のテキスト埋め込みにおける[CLS]プーリングは系列の先頭に情報が偏る傾向があり、平均プーリングは重要な局所信号を希釈してしまうという系統的な弱点があるが、本研究が提案するランドマーク(LMK)プーリングは系列をチャンクに分割して特殊トークンを挿入し、それらの埋め込みのみを平均化することで長文への対応力を劇的に高める。 この手法は、入力テキストの各所に配置されたランドマークトークンがそれぞれの区間の情報を適応的に集約するため、単一のトークンに表現の負担を強いることなく、系列全体から重要な特徴を抽出して固定次元のベクトルに変換することが可能であり、特に長文コンテキストにおける情報の消失や偏りの問題を解決する。 検証の結果、LMKプーリングは短文の検索タスクにおいて既存の標準的な手法と同等の高い性能を維持しつつ、長文タスクにおいては従来手法を大幅に上回る精度向上を達成しており、現代のテキストエンコーダにおける実用的かつ計算効率に優れた新しい標準的なプーリング手法としての有効性が示された。
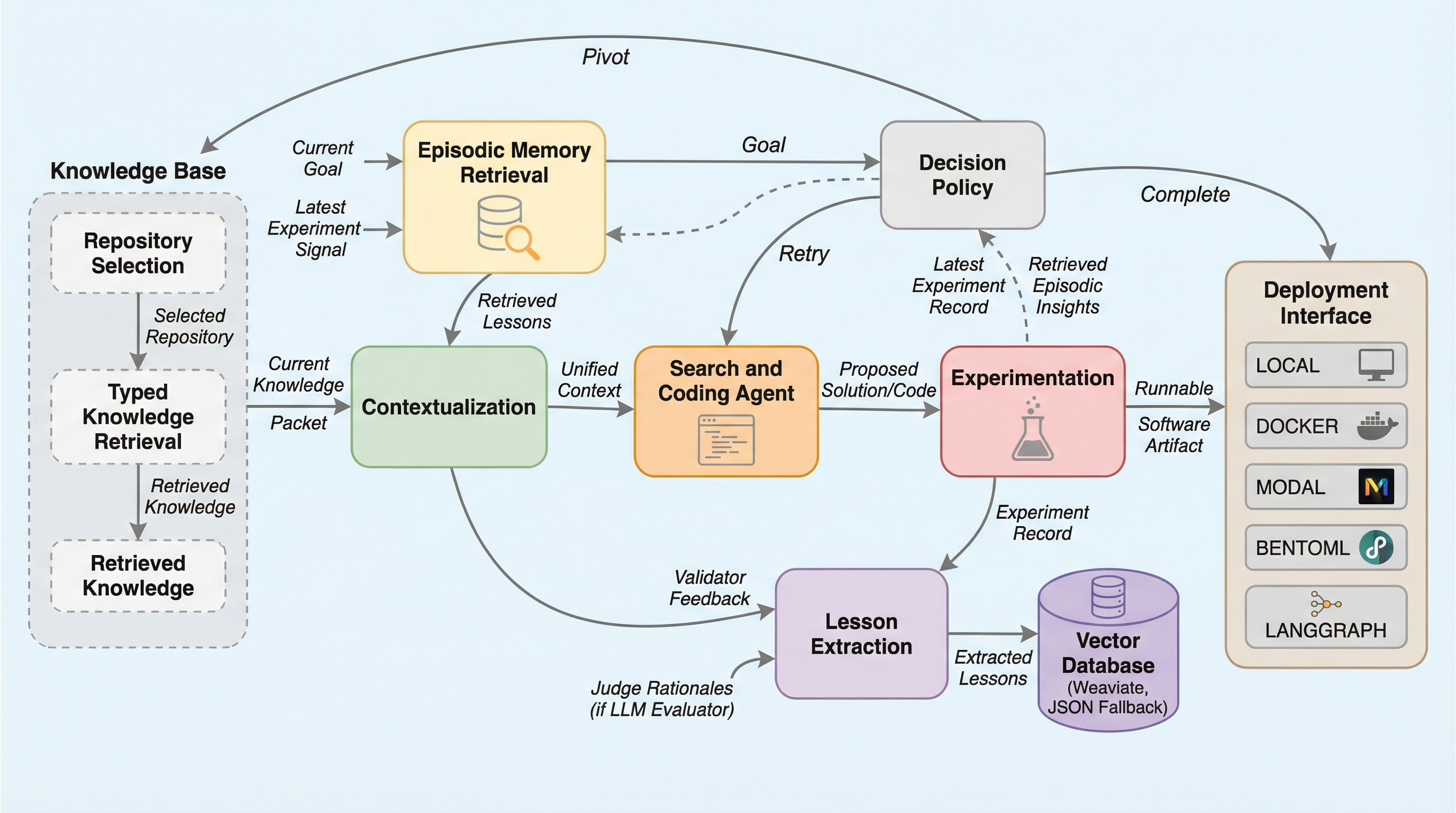
KAPSOは、自然言語の目標と評価方法を入力として、プログラムの着想、合成、実行、評価、学習のサイクルを自律的に繰り返すモジュール式のフレームワークであり、プログラム合成を単なるコード生成の終着点ではなく、測定可能な目標に向けた継続的な最適化プロセスとして再定義している。
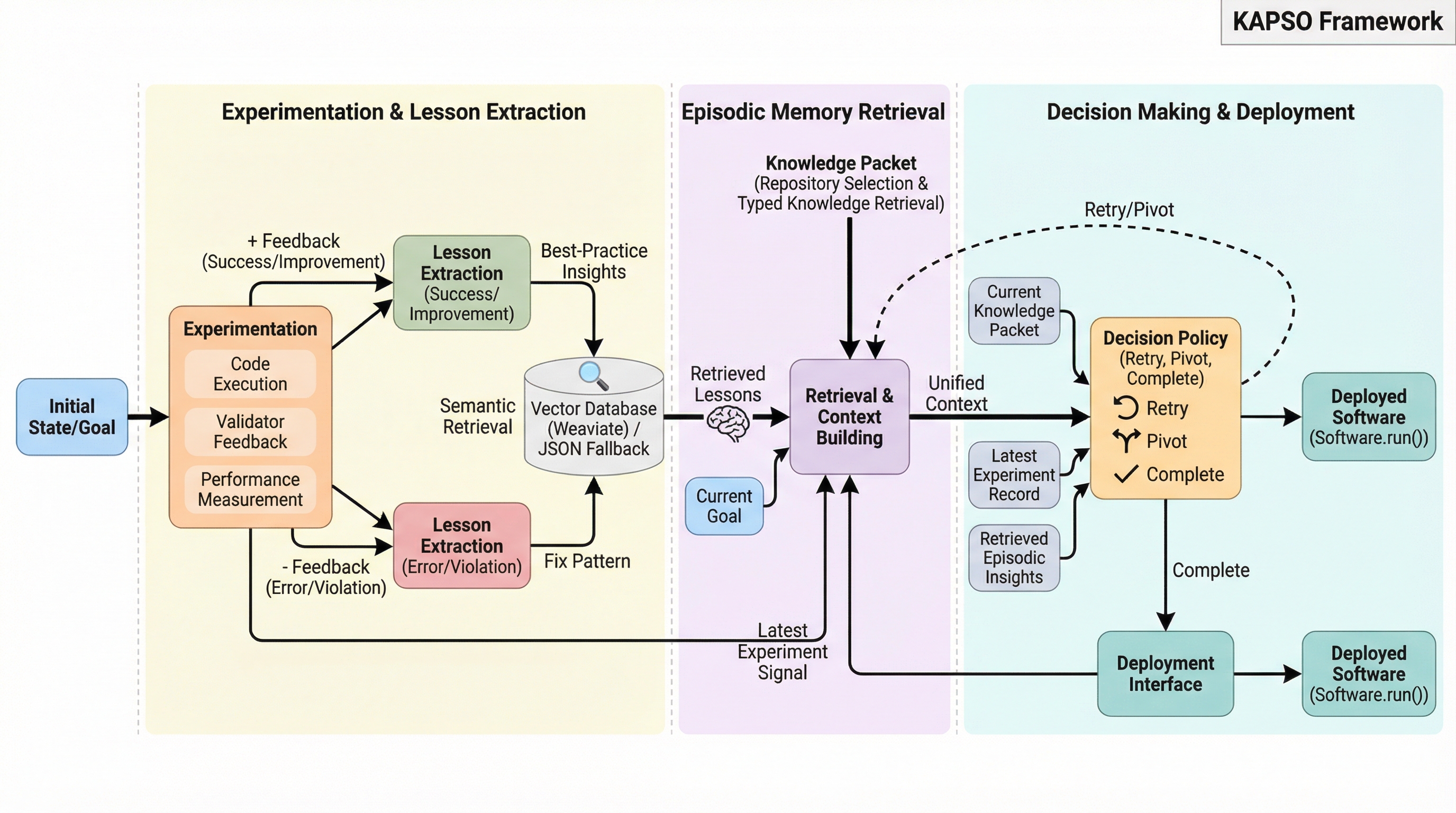
KAPSOは、自然言語の目標と評価方法を入力として、アイデア生成、コード合成、実行、評価、学習を繰り返すことで、測定可能な目標に向けて成果物を自律的に改善し続けるモジュール型フレームワークである。